






首先理清人工智能,机器学习,深度学习的关系。
人工智能最大,机器学习是人工智能的一个分支,深度学习是人工智能的一个分支。
什么是机器学习?
就是让机器在训练之后变得拥有类似人类的能力,可以执行一些任务。
就跟神模仿自己造出了人类一样。
机器学习有几种种类?
机器学习按照训练方法有三类:监督学习,无监督学习,强化学习。(半监督基于两者之间)
- 监督学习就是需要你给label,比如图像识别的数据集,需要框起来写class。
- 无监督学习就是不给方向,机器自己找特征,比如聚类。
- 强化学习就是指定一个方向(区别于label),类似打分机制,当机器做出理想行为则打高分,错误行为则打低分。它的思想是:不是告诉你什么是好的,而是告诉你什么比什么更好。chatgpt就是用了强化学习,研究团队认为这样可以突破监督学习的极限。
而这些机器学习算法要完成的任务是:
- 分类算法-是什么?即根据一个样本预测出它所属的类别。
- 回归算法-是多少?即根据一个样本预测出一个数量值。
- 聚类算法-怎么分?保证同一个类的样本相似,不同类的样本之间尽量不同。
- 强化学习-怎么做?即根据当前的状态决定执行什么动作,最后得到最大的回报。
深度学习和机器学习的关系
那么深度学习是哪一种机器学习呢?答案是都有可能。
深度学习的定义是一种以人工神经网络为架构,对资料进行表征学习的算法。
这里的人工神经网络包括:深度神经网络、卷积神经网络和深度置信网络和循环神经网络。
通过训练得到一种特殊的映射,使得输入一个东西,得到我们想要的输出。
收到gpt,yolo等影响,现在说机器学习,就是在说深度学习,和增强学习。
1. 深度学习
深度学习和SVM是对冤家,在梯度消失,样本少,算力高等问题没有解决之前,一直是SVM占上风。不过现在基本上都是用深度学习了。
-
深度神经网络:DNN,就是说网络层数很多,现在基本上都很多。
-
深度置信网络:DBN,用作DNN的预训练层。在小样本训练时提供较为可靠的初始化参数。每一层都是受限玻尔兹曼机,RBM。
-
玻尔兹曼机:RBM。首先得了解随机神经网络,就是在神经网络中加入随机变量,来避免局部最优解。其中一种随机变量是在神经元中使用随机传递函数,而这种随机神经网络的模型就叫玻尔兹曼机。
ps:如果毫无约束则没有意义,如图。
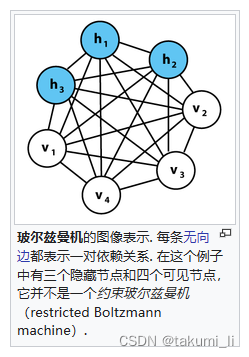
-
受限玻尔兹曼机:就是连接情况受限的玻尔兹曼机。介绍神经网络的时候应该都看过这个图,这就是大家常聊的受限玻尔兹曼机。
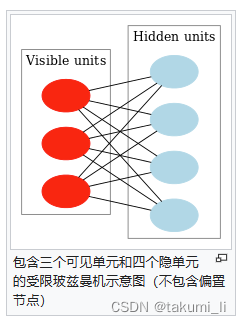
-
生成模型:玻尔兹曼机是一种随机生成神经网络模型。其中的“生成”二字,代表着这个模型可以根据已知数据集去猜测未知输入的输出概率分布,毕竟样本集不可能包括这个世界上所有的情况。区别于“判别模型”。判别模型只能对给出的样本集分类,如果遇到一个新词儿,判别模型就抓瞎了,这显然是不符合现在的潮流的。
-
最大似然估计:似然性类似于概率,但区别于概率。似然性是指根据已观察到的现象,对模型参数进行预测。当似然性值最大时,就说模型是这个参数的可能性最大。(如丢硬币3次出现2正1反,猜测该模型,即硬币,的出正面的概率参数更有可能是0.5还是0.6?)
下图就是似然函数,已知最终情况A,求模型参数B:

-
卷积神经网络:CNN,用于图像。
-
循环神经网络:RNN,用于NLP,语音。
2. 增强学习
RL,又叫强化学习,通过打分告诉机器什么比什么更好,进而突破监督训练的极限。作用可以参考gpt的训练过程:初期无监督训练,中期有监督训练,后期强化训练。用于模拟人类从婴儿到成人的学习过程。
标准的定义是:训练如何基于环境而行动,进而获得最大收益。比如下围棋。
思想接近于动态规划。
-
马尔可夫决策过程:基本的强化学习被建模为马尔可夫决策过程。
- 环境状态的集合S
- 动作的集合A;
- 在状态之间转换的规则(转移概率矩阵)P;
- 规定转换后“即时奖励”的规则(奖励函数)R;
- 描述主体能够观察到什么的规则。
强化学习的目标是找到由(St,a,St+1)构成的r奖励函数最大的行为a。
参考:https://zhuanlan.zhihu.com/p/43833351
https://zh.wikipedia.org/wiki/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0#%E6%B7%B1%E5%BA%A6%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C















 2187
2187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









