









论文名:Delving into the Devils of Bird’s-eye-view Perception: A Review, Evaluation and Recipe
Github
论文网址
零、摘要
BEV perception 主要的4个问题是:
- 如何通过从perspective view 到 BEV视角的重构丢失的3D信息
- 如何获取BEV网格的ground truth 标注
- 如何公式化合并从不同sources和views获取的特征的pipline
- 如何在不同场景下传感器参数变化时,训练一个适配的、泛化性好的算法
一、Introducation
1.1 Big Picture at a Glance
本文基于输入的数据,将BEV研究分为:
- BEV camera:仅视觉 或 以视觉为中心的目标检测/分割算法,多摄像头
- BEV LiDAR :点云作为输入
- and BEV fusion:多模态输入,例如camera,LiDAR,GNSS,odomerty,HD-Map,CAN-bus
1.2 Motivation to BEV Perception Research
- Significance.
- 当前在nuScenes数据集上,仅视觉的算法比基于LiDAR的算法NDS指标低20%;在Waymon数据集上,甚至低超过30%。
- 单个相机的价格低于LiDAR的1/10
- Space.
- Readiness.
- 数据集:KITTI、Waymo、nuScenes、Argoverse
- 结构:Transformer,ViT, Mased Auto-encoders, CLIP
二、Background in 3D perception
2.1 Task Definition and Related Work
- 基于单目摄像头的3D目标检测:从单张RGB图预估深度时ill-posed problem, 因此表现较差。
- 基于LiDAR的3D目标检测:效果往往比基于摄像头的要好很多,因为多了深度的先验信息
- 传感器融合:摄像头、激光雷达、雷达融合
2.2 Datasets and Metrics
2.2.1 数据集
主要的数据集如下:
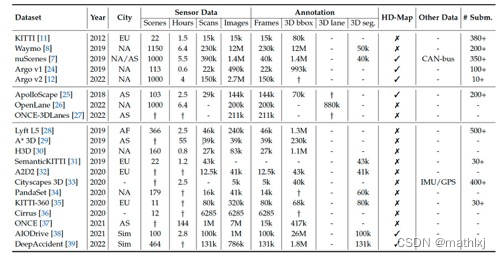
- KITTI:3D目标检测两个衡量指标:3D目标检测指标 & BEV指标
- Waymo: 5 LiDARs and 5 views (左,左前,前,右前,右)
- nuScenes: 6 views, 1 LiDAR, and 5 Radars + HD-Map and CAN-bus data.
2.2.2 Evaluation Metrics
- LET-3D-APL:类似于3D-AP,但给纵向位置一定的容许偏差.
- mAP: 在BEV视角下,根据不同距离阈值
- NDS:The nuScenes detection score,综合考虑mAP, mATE (Average Translation Error), mASE (Average Scale Error), mAOE (Average Orientation Error), mAVE (Average Velocity Error) and mAAE (Average Attribute Error)给出的分数。
三、Methodology of BEV perception
近期主要的文献有如下:
![[Image]](https://i-blog.csdnimg.cn/blog_migrate/0bf8bf3254c28b07712600b19e8e28e3.png)
这些方法的表现如下表
![[Image]](https://i-blog.csdnimg.cn/blog_migrate/caabc2888d9532d5bb71e3566061401d.png)
我们比较关心使用LiDAR和不适用的差距,由标黄的部分可以发现,两者差距还是较大。
与仅仅使用雷达的算法,例如CenterPoint,仍有部分差距。但已经超过了PointPillars.
3.1 BEV Camera
3.1.1 BEV Camera

- 算法主要分为:
- 2D特征提取器:backbone;
- 2D<->3D的转换矩阵:两种视角转换,2d->3d和3d->2d. 使用物理先验或者3D监督。
- 3D解码器:输入2D/3D的特征,输出3D bbox、BEV视角的地图分割、3D车道线
3.1.2 View Transformation
视角转换在仅摄像头的3D感知中非常关键。主要由两种思路:
- 使用2D特征来估计深度信息(bin-wise distribution to voxel space),将2D特征lift到3D空间
- 使用3D-2D映射关系将2D特征编码到3D空间,基于Inverse Perspective Mapping (IPM),投影矩阵由相机的内参和外参建模。
3.2 BEV LiDAR
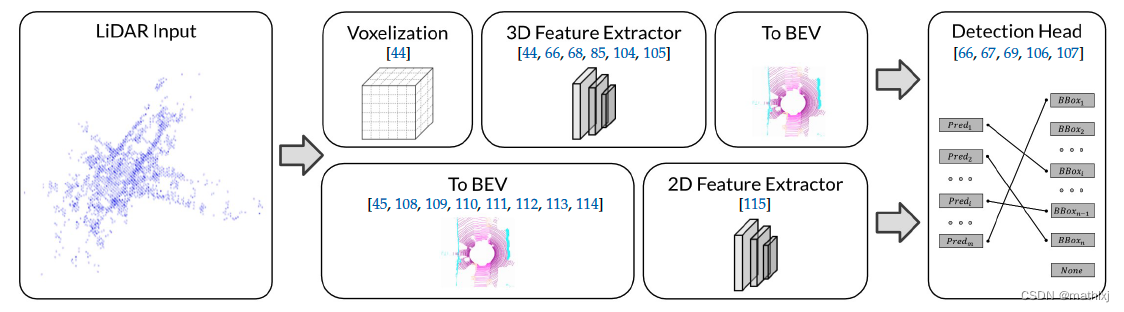
提取的3D点云特征转换为BEV特征图,再有一个解码器获得输出。3D点云->BEV的两种思路:
- Pre-BEV特征提取
原始点云->体素化点云为离散的网格->3D卷积和3D稀疏卷积 - Post-BEV特征提取
3D卷积计算量太大,因此转换为BEV grid, 网格中点的height、instensity、density来表示grid特征,常用的PointPillars、PointNet正是类似的思路
3.3 BEV Fusion
基于IPM,使用相机的内参&外参,将图像和点云特征在BEV视角内做融合。
- LiDAR-camera Fusion:以BEVFusion为代表
- Temporal Fusion:利用时序,将之前的BEV特征等利用起来。
3.4 Industrial Design of BEV Perception
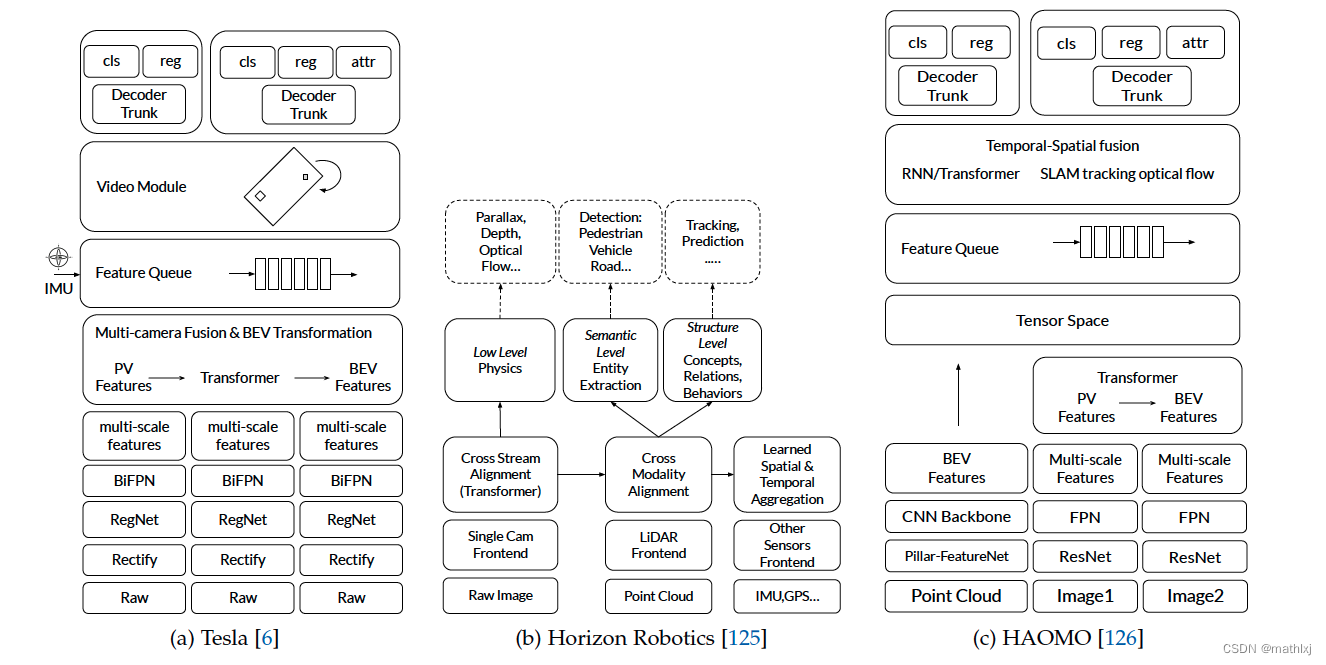
将PV特征映射到BEV空间的四种方法:
- Fixed IPM: 假设路面是平的,固定的转换矩阵
- Adaptive IPM:仍假设路面是平的,使用SDV的外参数
- Transformer:不需要先验信息,数据驱动,使用一个dense transormer,广泛应用到Tesla,Horizon, HAOMO
- ViDAR: 与LiDAR类似,使用pixel-level depth来映射

















 757
757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









