







1.前言
2.线性回归
2.1用numpy模拟计算predict和计算loss的过程
import numpy as np
import matplotlib.pyplot as plt
import sys
#大致模型为y=x*w
x_data=[1.0,2.0,3.0]
y_data=[2.0,4.0,6.0]
def forward(x):
return x*w
def loss(y_pred,y):
return np.power(y_pred-y,2)
w_list=[]
mse_list=[]
length=len(x_data)
for w in np.arange(0.0,4.1,0.1):
print(f"-----------w={w}-------------------------")
loss_sum=0
for x_val,y_val in zip(x_data,y_data):
y_pred=forward(x_val)
loss_val=loss(y_pred,y_val)
loss_sum+=loss_val
print(f'x_val={x_val},y_val={y_val},y_pred={y_pred},loss_val={loss_val}')
print(f"-----------MSE={loss_sum/length}----------")
w_list.append(w)
mse_list.append(loss_sum/length)
plt.plot(w_list,mse_list)
plt.ylabel("Loss")
plt.xlabel('w')
plt.show()
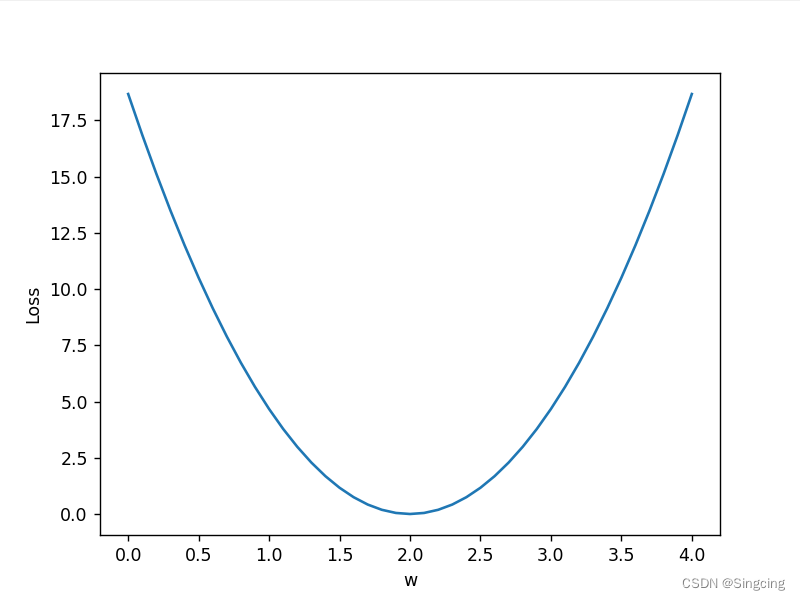
3.梯度下降
3.1numpy模拟梯度下降,用y=x*w的模型
import numpy as np
import matplotlib.pyplot as plt
x_data=[1.0,2.0,3.0,4.0,5.0]
y_data=[2.0,4.0,6.0,8.0,10.0]
# 权重初始化为1
w=1.0
def forward(x):
return x*w
#mean square error
# 批量数据的损失的平均值
def loss(x_data,y_data):
loss_sum=0
for x,y in zip(x_data,y_data):
y_pred=forward(x)
loss_sum+=(y_pred-y)**2
return loss_sum/len(x_data)
#计算w的梯度,就是代价函数对w求导,这里的w只有一个,因为x只有一个列,x只有一个特征
# 批量数据的导数的平均值
# d(x*w-y)**2 / dw = 2*w*(x*w-y)
def gradient(x_data,y_data):
gradient=0
for x,y in zip(x_data,y_data):
gradient+=(x*w-y)*x*2
return gradient/len(x_data)
mse_list=[]
w_list=[]
print("before training:",6,forward(6))
for epoch in range(100):
loss_val=loss(x_data,y_data)
mse_list.append(loss_val)
grad_val=gradient(x_data,y_data)
#梯度更新
w-=0.01*grad_val
w_list.append(w)
print(f"Epoch={epoch}, w={w},loss={loss_val}")
print("Predict(after training)",6,forward(6))
print(len(x_data))
print(len(y_data))
# ---------------画个图----------------
import matplotlib.pyplot as plt
import sys
# 因为forward函数中的x*w是单个数之间相乘
def forward2(x):
result=[xi * w for xi in x]
return result
fig, axes = plt.subplots(nrows=1, ncols=2)
axes[0].plot(w_list,mse_list)
axes[0].set_xlabel("Loss")
axes[0].set_ylabel("w")
axes[0].legend()
axes[1].scatter(x_data,y_data,color="blue",s=100,label="real data")
axes[1].plot(x_data,forward2(x_data),color="orange",label="linear model")
axes[1].set_xlabel("x_data")
axes[1].set_ylabel("y_data")
axes[1].legend()
plt.show()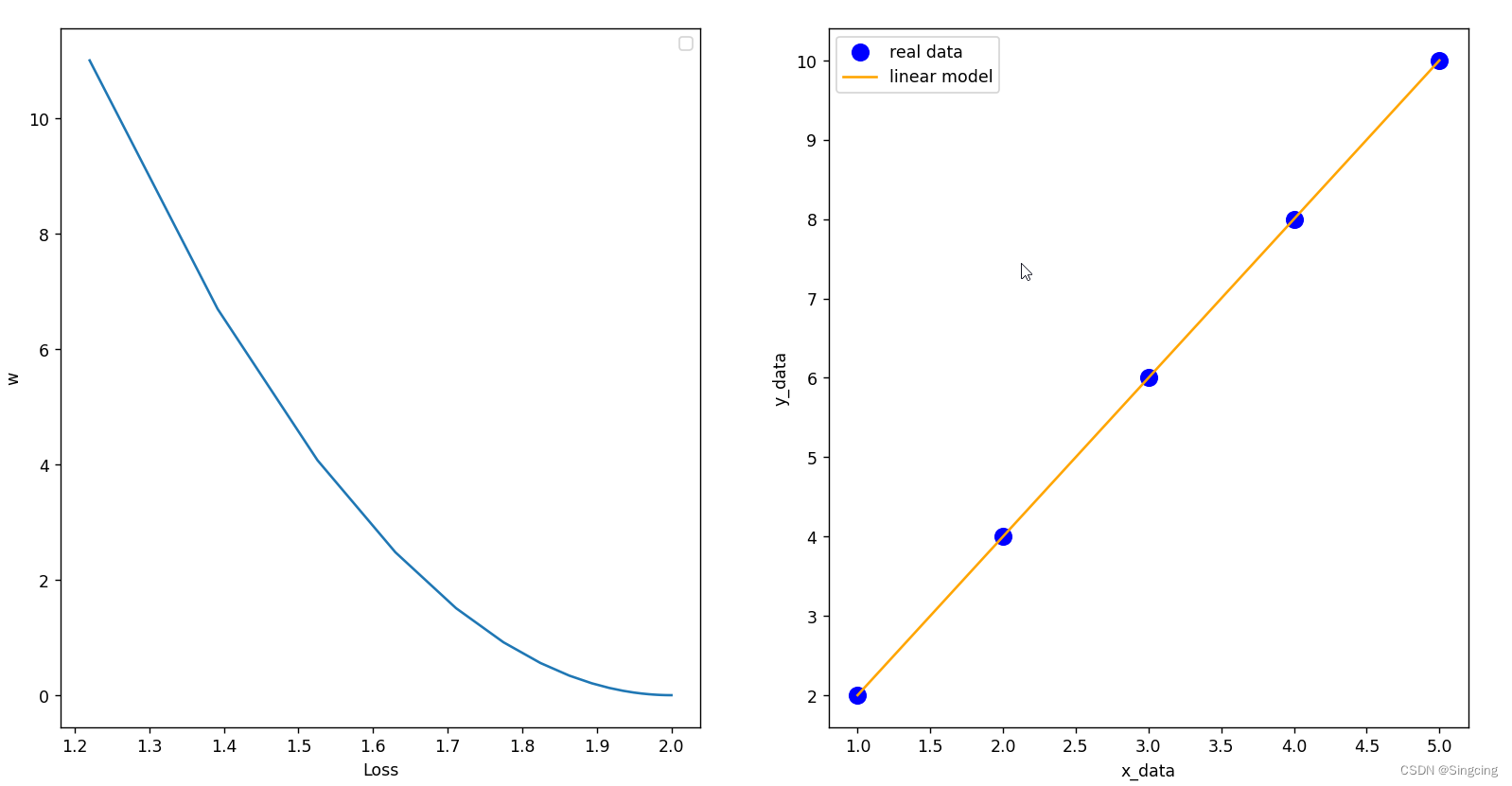
4.反向传播
4.1pytorch模拟梯度下降,用y=x*w的模型,loss.backword()自动求梯度,w开启存梯度的空间
import torch
import numpy as np
x_data=[1.0,2.0,3.0]
y_data=[2.0,4.0,6.0]
w=torch.Tensor([1.0])
w.requires_grad=True
#因为w是tensor,torch把运算结果自动转为tensor
def forward(x):
return x*w
#这个方法返回的也是tensor
def loss(x,y):
y_pred=forward(x)
return (y_pred-y)**2
print("predict(before training),",4,forward(4).item())
epoches=100
loss_list=[]
for epoch in range(epoches+1):
# 保存一个轮次所有样本的损失
loss_sum=0
for x,y in zip(x_data,y_data):
#loss_val返回的是tensor,具有计算图功能,能进行反向传播,
# 本例中,loss_val是一个数
loss_val=loss(x,y)
loss_sum+=loss_val.item()
loss_val.backward()
print("\tgrad:",x,y,w.grad.item())
#w.data不需要构建计算图,不需要w.backward(),为了节省空间不用tensor类型
# 梯度下降,后续可用optimizer.step()来处理
w.data=w.data-0.01*w.grad.data
w.grad.data.zero_()
# print("progress:",epoch,loss_val.item())
# 保存一个轮次的所有样本的平均损失
loss_list.append(loss_sum/len(x_data))
print("predict(after training)",4,forward(4).item())
import matplotlib.pyplot as plt
import sys
fig, axes = plt.subplots(nrows=1, ncols=2)
# x_data-->tensor(list)-->
# x_data和forward(x_data)不是单个数不能用item(),detach().numpy()来转换
y_pred=forward(torch.tensor(x_data)).tolist()
print(y_pred)
axes[0].scatter(x_data,y_data,color="blue",s=100,label="real data")
axes[0].plot(x_data,y_pred,color="orange",label="linear model")
axes[0].set_xlabel("x_data")
axes[0].set_ylabel("y_data")
axes[0].legend()
axes[1].plot(np.arange(0,epoches+1,1),loss_list)
axes[1].set_xlabel("epoches")
axes[1].set_ylabel("loss")
axes[1].legend()
plt.show()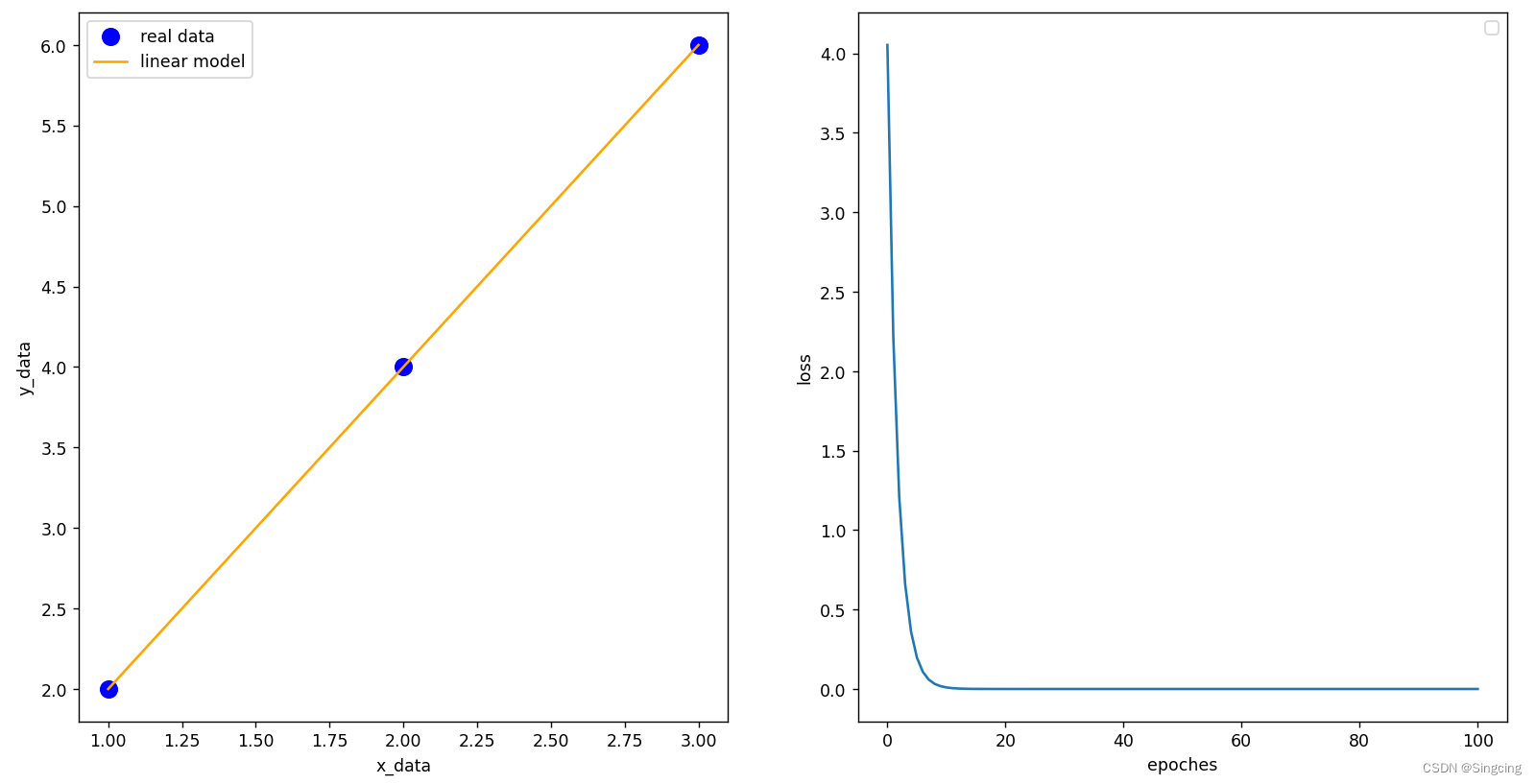
5.Pytorch实现线性回归
5.1 pytorch模拟y=x*w的线性模型,构建一个1x1的全连接层,使用optimizer.step()来梯度下降
import torch
import sys
import numpy as np
#3行1列的二位tensor
x_data=torch.Tensor([[1.0],
[2.0],
[3.0]])
y_data=torch.Tensor([[2.0],
[4.0],
[6.0]])
class LinearModel(torch.nn.Module):
def __init__(self) :
super(LinearModel,self).__init__()
self.linear=torch.nn.Linear(1,1)
def forward(self,x):
y_pred=self.linear(x)
return y_pred
model=LinearModel()
# def layer_summary(model,x):
# print("input shape:",x.size())
# for name,layer in model.named_children():
# x=layer(x)
# print(f"{name:<20s} {'out shape':>20s}",x.size())
# layer_summary(model,x_data)
# sys.exit()
# 创建一个均方误差损失函数对象,该对象用于衡量模型预测值与真实值之间的差异
criterion=torch.nn.MSELoss(size_average=False)
# 创建一个随机梯度下降优化器对象,该对象用于更新模型的参数。这里的学习率被设置为0.01
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)
loss_list=[]
epoches=20
for epoch in range(epoches+1):
y_pred=model(x_data)
loss=criterion(y_pred,y_data)
loss_list.append(loss.detach().numpy())
# print(epoch,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("w=",model.linear.weight.item())
print("b=",model.linear.bias.item())
x_test=torch.Tensor([[4.0]])
y_test=model(x_test)
print("y_pred=",y_test.data)
import matplotlib.pyplot as plt
fig,axes=plt.subplots(nrows=1,ncols=2)
axes[0].plot(np.arange(0,epoches+1,1),loss_list)
axes[0].set_xlabel("epoches")
axes[0].set_ylabel("loss")
axes[0].legend()
# (3,1),因为y_pred有梯度,不能直接numpy()
y_pred=model(x_data).detach().numpy()
x_data=x_data.numpy()
y_data=y_data.numpy()
axes[1].scatter(x_data[:,0],y_data[:,0],color="blue",s=100,label="real data")
axes[1].plot(x_data[:,0],y_pred[:,0],color="orange",label="linear model")
axes[1].set_xlabel("x_data")
axes[1].set_ylabel("y_data")
axes[1].legend()
plt.show()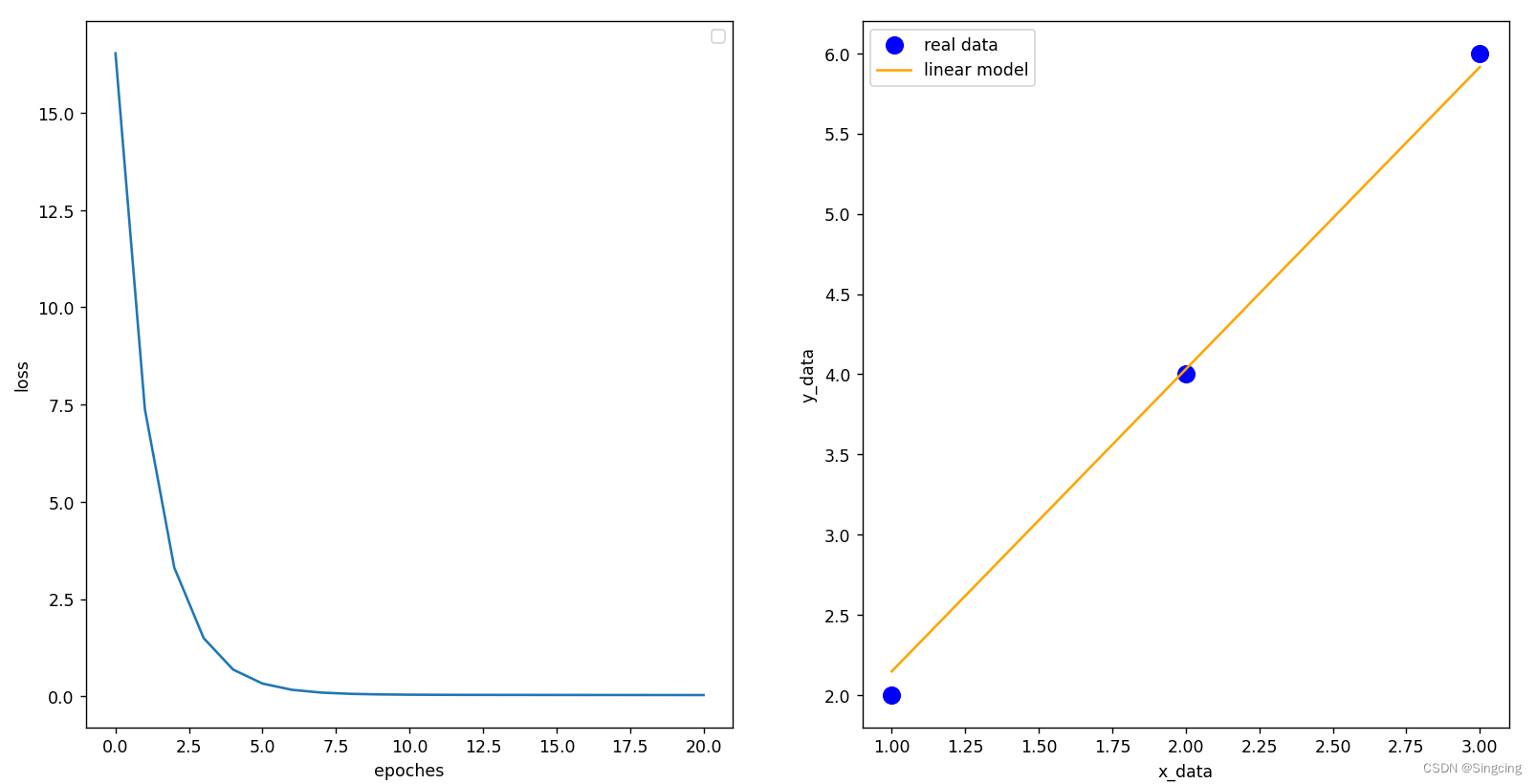
插曲:跟踪数据在网络中的形状变化
model=LinearModel()
def layer_summary(model,x):
print("input shape:",x.size())
for name,layer in model.named_children():
x=layer(x)
print(f"{name:<20s} {'out shape':>20s}",x.size())
layer_summary(model,x_data)input shape: torch.Size([3, 1])
linear out shape torch.Size([3, 1])6.Logistic回归
import torch.nn.functional as F
import torch
import sys
x_data=torch.Tensor([[1.0],
[2.0],
[3.0]])
y_data=torch.Tensor([[0],
[0],
[1]])
class LogisticRegression(torch.nn.Module):
def __init__(self) :
super(LogisticRegression,self).__init__()
self.linear=torch.nn.Linear(1,1)
def forward(self,x):
y_pred=torch.sigmoid(self.linear(x))
return y_pred
model=LogisticRegression()
# BCE(y,p)=-[y*log(p) + (1-y)*log(1-p)]
criterion=torch.nn.BCELoss(size_average=False)
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)
epoches=1000
for epoch in range(epoches+1):
y_pred=model(x_data)
loss=criterion(y_pred,y_data)
print(epoch,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
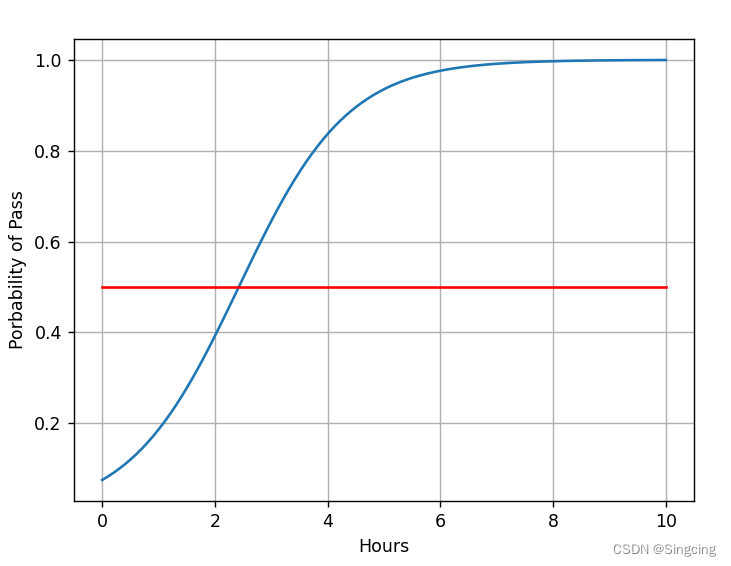
import numpy as np
import matplotlib.pyplot as plt
#生成一个包含200个元素的一维数组x,该数组的元素是0到10之间均匀分布的数字
x=np.linspace(0,10,200)
#view()相当于reshape()
x_t=torch.Tensor(x).view((200,1))
y_t=model(x_t)
y=y_t.data.numpy()
plt.plot(x,y)
plt.plot([0,10],[0.5,0.5],c='r')
plt.xlabel("Hours")
plt.ylabel("Porbability of Pass")
plt.grid()
plt.show()
7.处理多维特征的输入
import torch
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear=torch.nn.Linear(8,1)
self.sigmoid=torch.nn.Sigmoid()
def forward(self,x):
x=self.sigmoid(self.linear(x))
return x
model=Model()
import numpy as np
xy=np.loadtxt("diabetes.csv.gz",delimiter=",",dtype=np.float32)
x_data=torch.from_numpy(xy[:,:-1])
# 为了保存y_data的形状[32,1]的二维矩阵,而不是[32],所以不是xy[:,-1]
y_data=torch.from_numpy(xy[:,[-1]])
criterioin=torch.nn.BCELoss(size_average=True)
optimizer=torch.optim.SGD(model.parameters(),lr=0.1)
for epoch in range(100):
y_pred=model(x_data)
loss=criterioin(y_pred,y_data)
#Backward()
optimizer.zero_grad()
loss.backward()
#update
optimizer.step()8.加载数据集
8.1使用dataloader加载数据
"""使用dataloader加载数据"""
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import sys
#Dataset是抽象类
class DiabetesDataset(Dataset):
def __init__(self,filePath):
xy=np.loadtxt(filePath,delimiter=",",dtype=np.float32)
self.x_data=torch.from_numpy(xy[:,:-1])
#为了保存y_data的形状[32,1]的二维矩阵,而不是[32],所以不是xy[:,-1]
self.y_data=torch.from_numpy(xy[:,[-1]])
self.len=xy.shape[0]
#magic function:dataset[index]获取数据
def __getitem__(self, index):
return self.x_data[index],self.y_data[index]
#magic function
def __len__(self):
return self.len
dataset=DiabetesDataset("diabetes.csv.gz")
train_loader=DataLoader(dataset=dataset,
batch_size=32,
shuffle=True,
num_workers=0)
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear1=torch.nn.Linear(8,6)
self.linear2=torch.nn.Linear(6,4)
self.linear3=torch.nn.Linear(4,1)
self.sigmoid=torch.nn.Sigmoid()
def forward(self,x):
x=self.sigmoid(self.linear1(x))
x=self.sigmoid(self.linear2(x))
x=self.sigmoid(self.linear3(x))
return x
model=Model()
criterion=torch.nn.BCELoss(reduction="mean")
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)
def train():
for epoch in range(20):
#enumerate 从 0 开始枚举 train_loader 中的数据
for i, data in enumerate(train_loader,0):
# inputs_tensor([32,8]),labels_tensor([32,1])
inputs,labels=data
y_pred=model(inputs)
loss=criterion(y_pred,labels)
print(f"epoch={epoch}, i={i}, loss={loss.item()}")
optimizer.zero_grad()
loss.backward()
optimizer.step()
train()8.2 enumerate(train_loader) 一次迭代的结构
for a in enumerate(train_loader,0):
print(type(a)) # turple
print(len(a)) # len==2
print(type(a[0]),type(a[1]))#int list
print(len(a[1])) #len==2
print(type(a[1][0]),type(a[1][1])) # tensor tensor
print(a[1][0].size(),a[1][1].size()) #([32,8]), (32,1)
break
sys.exit()
"""
a的结构
a==turple:(
int:index of batch,
list:[ tensor([32,8]):inputs , tensor([32,1]):labels ]
)
"""9.多分类问题
9.1 torch.max()的例子
import torch
"""
一个torch.max的例子
"""
# Example predicted outputs (scores)
outputs = torch.tensor([
[0.1, 0.8, 0.3], # Sample 1: Scores for classes 0, 1, 2
[0.4, 0.2, 0.9], # Sample 2: Scores for classes 0, 1, 2
[0.7, 0.6, 0.5], # Sample 3: Scores for classes 0, 1, 2
[0.2, 0.3, 0.5] # Sample 4: Scores for classes 0, 1, 2
])
# Using torch.max to get the index of the maximum value along dimension 1 (column-wise)
number,predicted_indices = torch.max(outputs, dim=1)
# number: tensor([0.8000, 0.9000, 0.7000, 0.5000])
print("number: ",number)
# Predicted indices: tensor([1, 2, 0, 2])
print("Predicted indices:", predicted_indices)9.1 矩阵在网络中的计算中的,形状变化
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import random
import matplotlib.pyplot as plt
import sys
class Net(torch.nn.Module):
def __init__(self) -> None:
super(Net,self).__init__()
self.layer1=torch.nn.Linear(784,512)
self.layer2=torch.nn.Linear(512,256)
self.layer3=torch.nn.Linear(256,128)
self.layer4=torch.nn.Linear(128,64)
self.layer5=torch.nn.Linear(64,10)
def forward(self,x):
x=x.view(-1,784)
x=F.relu(self.layer1(x))
x=F.relu(self.layer2(x))
x=F.relu(self.layer3(x))
x=F.relu(self.layer4(x))
x=self.layer5(x)
return x
model=Net()
"""
变量的变化形状变化过程
"""
def layer_summary(model,x):
print("input shape:",x.size())
x=x.view(-1,784)
print("input shape:",x.size())
for name,layer in model.named_children():
x=layer(x)
print(f"{name:<20s} {'out shape':>20s}",x.size())
# 看网络的内部结构
print(model)
x_data=torch.randn(1,1,28,28)
layer_summary(model,x_data)
9.2 使用全连接网络训练MNIST数据集
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import random
import matplotlib.pyplot as plt
import sys
batchSize=64
transform=transforms.Compose([
transforms.ToTensor(),
#均值=0.1307,标准差=0.
# output=(input-mean)/std
transforms.Normalize((0.1307,),(0.3081,))
])
train_dataset=datasets.MNIST(root="data/mnist",
train=True,
download=True,
transform=transform)
train_loader=DataLoader(train_dataset,
shuffle=True,
batch_size=batchSize)
test_dataset=datasets.MNIST(root="data/mnist",
train=False,
download=True,
transform=transform)
test_loader=DataLoader(test_dataset,
shuffle=True,
batch_size=batchSize)
def showRandomPictures(train_loader):
data_iter=iter(train_loader)
images,labels=data_iter.__next__()
# Choose a random index from the batch
random_index = random.randint(0, batchSize - 1)
# Display the transformed image
transformed_image = images[random_index].squeeze().numpy()
transformed_image = (transformed_image * 0.3081) + 0.1307 # Inverse normalization
plt.imshow(transformed_image, cmap='gray') # Assuming MNIST images are grayscale
plt.title(f"Label: {labels[random_index].item()}")
plt.show()
# showRandomPictures(train_loader)
class Net(torch.nn.Module):
def __init__(self) -> None:
super(Net,self).__init__()
self.layer1=torch.nn.Linear(784,512)
self.layer2=torch.nn.Linear(512,256)
self.layer3=torch.nn.Linear(256,128)
self.layer4=torch.nn.Linear(128,64)
self.layer5=torch.nn.Linear(64,10)
def forward(self,x):
x=x.view(-1,784)
x=F.relu(self.layer1(x))
x=F.relu(self.layer2(x))
x=F.relu(self.layer3(x))
x=F.relu(self.layer4(x))
x=self.layer5(x)
return x
model=Net()
"""
input shape: torch.Size([1, 1, 28, 28])
input shape: torch.Size([1, 784])
layer1 out shape torch.Size([1, 512])
layer2 out shape torch.Size([1, 256])
layer3 out shape torch.Size([1, 128])
layer4 out shape torch.Size([1, 64])
layer5 out shape torch.Size([1, 10])
"""
# def layer_summary(model,x):
# print("input shape:",x.size())
# x=x.view(-1,784)
# print("input shape:",x.size())
# for name,layer in model.named_children():
# x=layer(x)
# print(f"{name:<20s} {'out shape':>20s}",x.size())
# x_data=torch.randn(1,1,28,28)
# layer_summary(model,x_data)
criterion=torch.nn.CrossEntropyLoss()
optimizer=optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
def train(epoch):
running_loss=0.0
for batch_idx,data in enumerate(train_loader,0):
# inputs_Size([64,1,28,28])
# target_Size([64])
inputs,target=data
inputs=inputs.to(device)
target=target.to(device)
optimizer.zero_grad()
# output_size([64,10])
outputs=model(inputs)
# loss=tensor(2.3112,grad_fn=<NllLossBackward0>)
# loss.item()=2.3112
# loss.size()=[],因为loss是个标量,不是矩阵或者张量或者矢量
loss=criterion(outputs,target)
loss.backward()
optimizer.step()
running_loss+=loss.item()
if batch_idx%300==299:
print(f"[epoch={epoch+1}, batch_index={batch_idx+1}, training_loss={running_loss/300}]")
running_loss=0.0
accuracyHistory=[]
def test():
correct=0
total=0
with torch.no_grad():
for data in test_loader:
#imagesSize([64,1,28,28]) lableSize([64])
images,labels=data
images=images.to(device)
labels=labels.to(device)
# outputsSize([64,10])
outputs=model(images)
#每一行的最大值的下标[max,maxIndex]
_,predicted=torch.max(outputs.data,dim=1)
#label.size(0)是batch_size
total+=labels.size(0)
correct+=(predicted==labels).sum().item()
print(f"Accuracy on test set:{100*correct/total}")
accuracyHistory.append(100*correct/total)
if __name__=="__main__":
for epoch in range(10):
train(epoch)
test()
plt.plot(accuracyHistory)
plt.xlabel("epoches")
plt.ylabel("accuracy in testset")
plt.show() 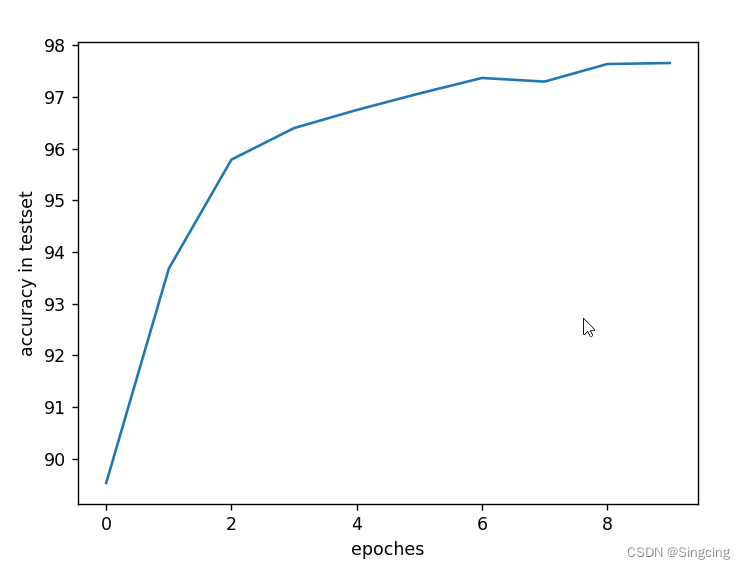
10.卷积神经网络
10.1 一个卷积层
import torch
in_channels, out_channels= 5, 10
width, height = 100, 100
kernel_size = 3
batch_size = 1
input = torch.randn(batch_size,
in_channels,
width,
height)
conv_layer = torch.nn.Conv2d(in_channels,
out_channels,
kernel_size=kernel_size)
output = conv_layer(input)
print(input.shape) # torch.Size[1,5,100,100]
print(output.shape) # torch.Size[1,10,98,98]
# conv_layer.weight.data.shape[out_channels,in_channels,kernel_height,kernel_width]
print(conv_layer.weight.shape) # torch.([10,5,3,3])
# print(conv_layer.weight.data)
"""
input[bs,channels,h,w]
output[bs,channels's, h-k+1,w-k+1]
"""10.2 有padding的卷积层
import torch
input = [ 3,4,6,5,7,
2,4,6,8,2,
1,6,7,8,4,
9,7,4,6,2,
3,7,5,4,1 ]
input = torch.Tensor(input).view(1, 1, 5, 5)
conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)
kernel = torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1, 1, 3, 3)
print(kernel)
conv_layer.weight.data = kernel.data
output = conv_layer(input)
print(output)
print(output.shape)10.3 Maxpooling
import torch
input = [ 3,4,6,5,
2,4,6,8,
1,6,7,8,
9,7,4,6,
]
input = torch.Tensor(input).view(1, 1, 4, 4)
maxpooling_layer = torch.nn.MaxPool2d(kernel_size=2)
output = maxpooling_layer(input)
print(output)10.4 在自定义卷积矩阵在网络中的变化
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import random
import matplotlib.pyplot as plt
import sys
class Net(torch.nn.Module):
def __init__(self) :
super(Net,self).__init__()
self.conv1=torch.nn.Conv2d(1,10,kernel_size=5)
self.pooling1=torch.nn.MaxPool2d(2)
self.conv2=torch.nn.Conv2d(10,20,kernel_size=5)
self.pooling2=torch.nn.MaxPool2d(2)
self.fc=torch.nn.Linear(320,10)
def forward(self,x):
batch_size=x.size(0)
x=F.relu(self.pooling1(self.conv1(x)))
x=F.relu(self.pooling2(self.conv2(x)))
x=x.view(batch_size,-1)
x=self.fc(x)
return x
model=Net()
"""
变量的变化形状变化过程
"""
def layer_summary(model,x):
for name,layer in model.named_children():
x=layer(x)
print(f"{name:<20s} {'out shape':>20s}",x.size())
if name=="pooling2":
bs=x.size(0)
x=x.view(bs,-1)
# 看网络的内部结构
print(model)
# x_data[bat_size:64, channels:1, height:28, width:28]
x_data=torch.randn(64,1,28,28)
layer_summary(model,x_data)
"""
result:
Net(
(conv1): Conv2d(1, 10, kernel_size=(5, 5), stride=(1, 1))
(pooling1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(10, 20, kernel_size=(5, 5), stride=(1, 1))
(pooling2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc): Linear(in_features=320, out_features=10, bias=True)
)
conv1 out shape torch.Size([64, 10, 24, 24])
pooling1 out shape torch.Size([64, 10, 12, 12])
conv2 out shape torch.Size([64, 20, 8, 8])
pooling2 out shape torch.Size([64, 20, 4, 4])
fc out shape torch.Size([64, 10])
"""10.5 构建CNN网络检测MNIST数据集
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import random
import matplotlib.pyplot as plt
import sys
batchSize=64
transform=transforms.Compose([
transforms.ToTensor(),
#均值=0.1307,标准差=0.3081
transforms.Normalize((0.1307,),(0.3081,))
])
train_dataset=datasets.MNIST(root="data/mnist",
train=True,
download=True,
transform=transform)
train_loader=DataLoader(train_dataset,
shuffle=True,
batch_size=batchSize)
test_dataset=datasets.MNIST(root="data/mnist",
train=False,
download=True,
transform=transform)
test_loader=DataLoader(test_dataset,
shuffle=True,
batch_size=batchSize)
def showRandomPictures(train_loader):
data_iter=iter(train_loader)
images,labels=data_iter.__next__()
# Choose a random index from the batch
random_index = random.randint(0, batchSize - 1)
# Display the transformed image
transformed_image = images[random_index].squeeze().numpy()
transformed_image = (transformed_image * 0.3081) + 0.1307 # Inverse normalization
plt.imshow(transformed_image, cmap='gray') # Assuming MNIST images are grayscale
plt.title(f"Label: {labels[random_index].item()}")
plt.show()
showRandomPictures(train_loader)
class Net(torch.nn.Module):
def __init__(self) :
super(Net,self).__init__()
self.conv1=torch.nn.Conv2d(1,10,kernel_size=5)
self.conv2=torch.nn.Conv2d(10,20,kernel_size=5)
self.pooling=torch.nn.MaxPool2d(2)
self.fc=torch.nn.Linear(320,10)
"""
image[bs,1,28*28]---conv1--->[bs,10,24*24]--->maxpooling--->[bs,10,12*12]
--->conv2--->image[bs,20,8*8]---maxpooling--->
image[bs,20,4*4]---view--->image[bs,320]-->linear-->image[bs,10]
"""
def forward(self,x):
batch_size=x.size(0)
x=F.relu(self.pooling(self.conv1(x)))
x=F.relu(self.pooling(self.conv2(x)))
x=x.view(batch_size,-1)
x=self.fc(x)
return x
model=Net()
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion=torch.nn.CrossEntropyLoss()
optimizer=optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
def train(epoch):
running_loss=0.0
for batch_idx,data in enumerate(train_loader,0):
inputs,target=data
# inputSize[64,1,28,28],targetSize([64])
inputs,target=inputs.to(device),target.to(device)
optimizer.zero_grad()
# outputSize[64,10]
ouputs=model(inputs)
# loss(2,3810,device="cuda:0",grad_fn=<NllLossBackward0>)
loss=criterion(ouputs,target)
loss.backward()
optimizer.step()
running_loss+=loss.item()
if batch_idx%300==299:
print("[%d %5d] loss:%.3f"%(epoch+1,batch_idx+1,running_loss/2000))
running_loss=0.0
accuracyHistory=[]
def test():
correct=0
total=0
with torch.no_grad():
for data in test_loader:
# inputsSize[64,1,28,28], targetSize[64]
inputs,target=data
inputs,target=inputs.to(device),target.to(device)
# outputSize[64,10]
outputs=model(inputs)
# predicted[64]
_,predicted=torch.max(outputs.data,dim=1)
total+=target.size(0)
correct+=(predicted==target).sum().item()
print(inputs.size()," ",target.size())
print(outputs.size())
print(predicted.size())
sys.exit()
print("Accuracy on test set %d %% [%d/%d]"%(100*correct/total,correct,total))
accuracyHistory.append(100 * correct/total)
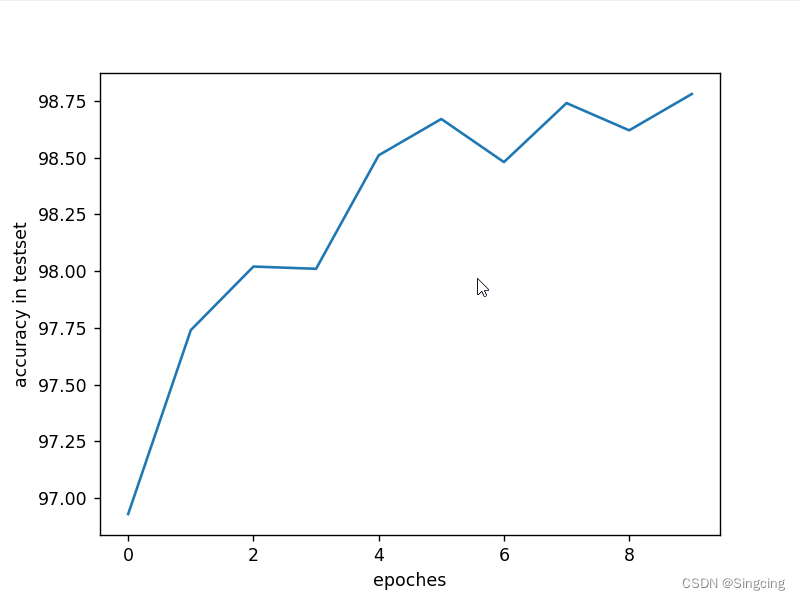
if __name__=="__main__":
for epoch in range(10):
train(epoch)
test()
plt.plot(accuracyHistory)
plt.xlabel("epoches")
plt.ylabel("accuracy in testset")
plt.show()
11. inception
11.1 inceptionA:一个inception模块
"""
transfor image(batch,c,w,h)-->image(batch,88,,w,h)
"""
import torch
from torch import nn
import torch.nn.functional as F
"""
MNIST数据集中,每张图片(c:1,h:28,w:28)
"""
class InceptionA(nn.Module):
def __init__(self,in_channel) -> None:
super(InceptionA,self).__init__()
self.branch_pool1x1=nn.Conv2d(in_channel,24,kernel_size=1)
self.branch1x1=nn.Conv2d(in_channel,16,kernel_size=1)
self.branch5x5_1=nn.Conv2d(in_channel,16,kernel_size=1)
self.branch5x5_2=nn.Conv2d(16,24,kernel_size=5,padding=2)
self.branch3x3_1=nn.Conv2d(in_channel,16,kernel_size=1)
self.branch3x3_2=nn.Conv2d(16,24,kernel_size=3,padding=1)
self.branch3x3_3=nn.Conv2d(24,24,kernel_size=3,padding=1)
def forward(self,x):
branch_pool=F.avg_pool2d(x,kernel_size=3,stride=1,padding=1)
branch_pool=self.branch_pool1x1(branch_pool)
branch1x1=self.branch1x1(x)
branch5x5=self.branch5x5_1(x)
branch5x5=self.branch5x5_2(branch5x5)
branch3x3=self.branch3x3_1(x)
branch3x3=self.branch3x3_2(branch3x3)
branch3x3=self.branch3x3_3(branch3x3)
outputs=[branch1x1,branch5x5,branch3x3,branch_pool]
return torch.cat(outputs,dim=1)11.2 inceptionA2 整个网络
"""
the overall Network
"""
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.optim as optim
import random
import matplotlib.pyplot as plt
import torch
import torch.nn
from torch import nn
import torch.nn.functional as F
import sys
"""
InceptionA:transfor image(batch,c,w,h)-->image(batch,88,,w,h)
"""
from InceptionA import InceptionA
class Net(nn.Module):
def __init__(self) -> None:
super(Net,self).__init__()
self.conv1=nn.Conv2d(1,10,kernel_size=5)
self.conv2=nn.Conv2d(88,20,kernel_size=5)
self.incep1=InceptionA(in_channel=10)
self.incep2=InceptionA(in_channel=20)
self.maxpooling=nn.MaxPool2d(2)
self.fc=nn.Linear(1408,10)
def forward(self,x):
batchSize=x.size(0)
x=F.relu(self.maxpooling(self.conv1(x)))
x=self.incep1(x)
x=F.relu(self.maxpooling(self.conv2(x)))
x=self.incep2(x)
x=x.view(batchSize,-1)
x=self.fc(x)
return x
11.3 inceptionA3 设计train和test过程
"""
data:MiNST
The concrete training and testing procedure
"""
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.optim as optim
import random
import matplotlib.pyplot as plt
import torch
import torch.nn
from torch import nn
import torch.nn.functional as F
from InceptionA2 import Net
batchSize=64
transformSetting=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])
"""
prepare the traning and testing data
"""
train_dataset=datasets.MNIST(root="data/mnist",
train=True,
download=True,
transform=transformSetting)
train_loader=DataLoader(train_dataset,
shuffle=True,
batch_size=batchSize)
test_dataset=datasets.MNIST(root="data/mnist",
train=False,
download=True,
transform=transformSetting)
test_loader=DataLoader(test_dataset,
shuffle=True,
batch_size=batchSize)
def showRandomPictures(train_loader):
data_iter=iter(train_loader)
images,labels=data_iter.__next__()
# Choose a random index from the batch
random_index = random.randint(0, batchSize - 1)
# Display the transformed image
transformed_image = images[random_index].squeeze().numpy()
transformed_image = (transformed_image * 0.3081) + 0.1307 # Inverse normalization
plt.imshow(transformed_image, cmap='gray') # Assuming MNIST images are grayscale
plt.title(f"Label: {labels[random_index].item()}")
plt.show()
showRandomPictures(train_loader)
model=Net()
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion=torch.nn.CrossEntropyLoss()
optimizer=optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
def train(epoch):
running_loss=0.0
for batch_idx,data in enumerate(train_loader,0):
inputs,target=data
inputs,target=inputs.to(device),target.to(device)
optimizer.zero_grad()
ouputs=model(inputs)
loss=criterion(ouputs,target)
loss.backward()
optimizer.step()
running_loss+=loss.item()
if batch_idx%300==299:
print("[%d %5d] loss:%.3f"%(epoch+1,batch_idx+1,running_loss/2000))
running_loss=0.0
accuracyOnTestHistory=[]
def test():
correct=0
total=0
with torch.no_grad():
for data in test_loader:
inputs,target=data
inputs,target=inputs.to(device),target.to(device)
outputs=model(inputs)
#每一行的最大值的下标[max,maxIndex]
_,predicted=torch.max(outputs.data,dim=1)
total+=target.size(0)
correct+=(predicted==target).sum().item()
print("Accuracy on test set %d %%[%d/%d]"%(100*correct/total,correct,total))
accuracyOnTestHistory.append(100*correct/total)
if __name__=="__main__":
for epoch in range(10):
train(epoch)
test()
plt.plot(accuracyOnTestHistory)
plt.show()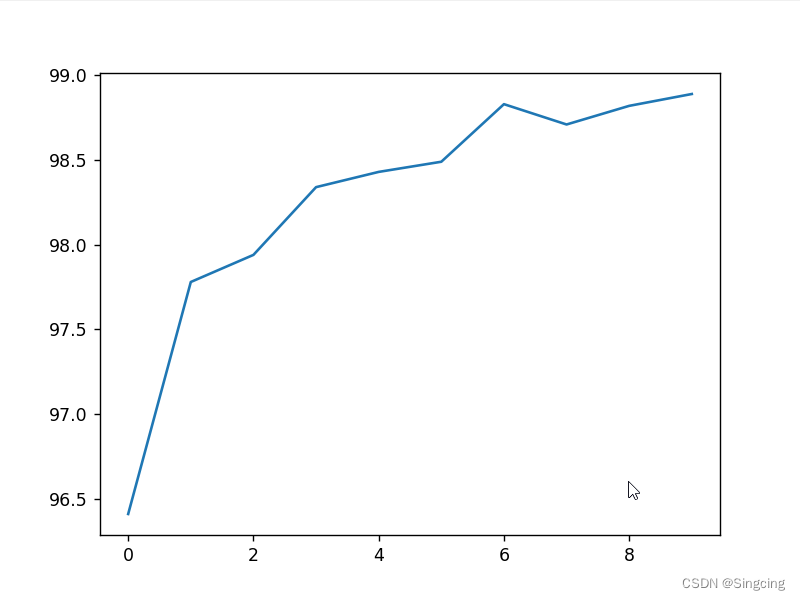
12. ResNet
12.1 ResNet :一个残差单元
"""
一个残差单元
"""
import torch
from torch import nn
import torch.nn.functional as F
"""
image(c,w,h)--->image(c,w,h)
"""
class ResidualBlock(nn.Module):
def __init__(self, channels) :
super(ResidualBlock,self).__init__()
self.channels=channels
self.conv1=nn.Conv2d(channels,channels,
kernel_size=3,padding=1)
self.conv2=nn.Conv2d(channels,channels,
kernel_size=3,padding=1)
def forward(self,x):
y=F.relu(self.conv1(x))
y=self.conv2(y)
return F.relu(x+y)12.2 ResNet2 :整个网络
import torch
from torch import nn
from Residual import ResidualBlock
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self) -> None:
super(Net,self).__init__()
self.conv1=nn.Conv2d(1,16,kernel_size=5)
self.conv2=nn.Conv2d(16,32,kernel_size=5)
self.mp=nn.MaxPool2d(2)
self.residualBock1=ResidualBlock(16)
self.residualBock2=ResidualBlock(32)
self.fc=nn.Linear(512,10)
def forward(self,x):
batch=x.size(0)
x=self.mp(F.relu(self.conv1(x)))
x=self.residualBock1(x)
x=self.mp(F.relu(self.conv2(x)))
x=self.residualBock2(x)
x=x.view(batch,-1)
x=self.fc(x)
return x12.3 ResNet3 设计train和test过程
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.optim as optim
import random
import matplotlib.pyplot as plt
import torch
import torch.nn
from torch import nn
import torch.nn.functional as F
from Residual2 import Net
batchSize=64
transformSetting=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])
"""
prepare the traning and testing data
"""
train_dataset=datasets.MNIST(root="data/mnist",
train=True,
download=True,
transform=transformSetting)
train_loader=DataLoader(train_dataset,
shuffle=True,
batch_size=batchSize)
test_dataset=datasets.MNIST(root="data/mnist",
train=False,
download=True,
transform=transformSetting)
test_loader=DataLoader(test_dataset,
shuffle=True,
batch_size=batchSize)
def showRandomPictures(train_loader):
data_iter=iter(train_loader)
images,labels=data_iter.__next__()
# Choose a random index from the batch
random_index = random.randint(0, batchSize - 1)
# Display the transformed image
transformed_image = images[random_index].squeeze().numpy()
transformed_image = (transformed_image * 0.3081) + 0.1307 # Inverse normalization
plt.imshow(transformed_image, cmap='gray') # Assuming MNIST images are grayscale
plt.title(f"Label: {labels[random_index].item()}")
plt.show()
showRandomPictures(train_loader)
model=Net()
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion=torch.nn.CrossEntropyLoss()
optimizer=optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
def train(epoch):
running_loss=0.0
for batch_idx,data in enumerate(train_loader,0):
inputs,target=data
inputs,target=inputs.to(device),target.to(device)
optimizer.zero_grad()
ouputs=model(inputs)
loss=criterion(ouputs,target)
loss.backward()
optimizer.step()
running_loss+=loss.item()
if batch_idx%300==299:
print("[%d %5d] loss:%.3f"%(epoch+1,batch_idx+1,running_loss/2000))
running_loss=0.0
accuracy_testset_history=[]
def test():
correct=0
total=0
with torch.no_grad():
for data in test_loader:
inputs,target=data
inputs,target=inputs.to(device),target.to(device)
outputs=model(inputs)
#每一行的最大值的下标[max,maxIndex]
_,predicted=torch.max(outputs.data,dim=1)
total+=target.size(0)
correct+=(predicted==target).sum().item()
print("Accuracy on test set %d %%[%d/%d]"%(100*correct/total,correct,total))
accuracy_testset_history.append(100*correct/total)
if __name__=="__main__":
for epoch in range(10):
train(epoch)
test()
plt.plot(accuracy_testset_history)
plt.show()
13. RNN
敬请期待















 4211
4211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









