







西瓜书决策树
了解决策树算法后,巩固和理解算法,编程实现信息熵。一开始打算直接用pandas读取的数据进行计算。但是计算信息增益的时候发现数据选取太麻烦,所以还是需要参考将DataFrame转为向量形式。
#决策树
#计算根结点信息熵
dataset=pd.read_excel("watermelon.xlsx")
label=dataset["好瓜"].value_counts()
Ent=0
for target in label.index:
Ent+=-(label[target]/label.sum())*log(label[target]/label.sum(),2)
Ent
#0.9975025463691153
#与西瓜书上计算一致
#计算色泽信息增益但数据选取太麻烦
label_1=dataset["色泽"].value_counts()
label_1
dataset[(dataset["色泽"]=="青绿") & (dataset["好瓜"]=="是")]["色泽"].count()
dataset[(dataset["色泽"]=="青绿") & (dataset["好瓜"]=="是")]["色泽"].count()/ dataset[(dataset["色泽"]=="青绿")]["色泽"].count()
dataset=dataset.iloc[:,[1,2,3,4,5,6,9]]
dataset

dataset["色泽"]=dataset["色泽"].map({"青绿":0,"乌黑":1,"浅白":2})
dataset["根蒂"]=dataset["根蒂"].map({"蜷缩":0,"稍蜷":1,"硬挺":2})
dataset["敲声"]=dataset["敲声"].map({"浊响":0,"沉闷":1,"清脆":2})
dataset["纹理"]=dataset["纹理"].map({"清晰":0,"稍糊":1,"模糊":2})
dataset["脐部"]=dataset["脐部"].map({"凹陷":0,"稍凹":1,"平坦":2})
dataset["触感"]=dataset["触感"].map({"硬滑":0,"软粘":1})
dataset["好瓜"]=dataset["好瓜"].map({"是":1,"否":0})
np.array(dataset)
"""
array([[0, 0, 0, 0, 0, 0, 1],
[1, 0, 1, 0, 0, 0, 1],
[1, 0, 0, 0, 0, 0, 1],
[0, 0, 1, 0, 0, 0, 1],
[2, 0, 0, 0, 0, 0, 1],
[0, 1, 0, 0, 1, 1, 1],
[1, 1, 0, 1, 1, 1, 1],
[1, 1, 0, 0, 1, 0, 1],
[1, 1, 1, 1, 1, 0, 0],
[0, 2, 2, 0, 2, 1, 0],
[2, 2, 2, 2, 2, 0, 0],
[2, 0, 0, 2, 2, 1, 0],
[0, 1, 0, 1, 0, 0, 0],
[2, 1, 1, 1, 0, 0, 0],
[1, 1, 0, 0, 1, 1, 0],
[2, 0, 0, 2, 2, 0, 0],
[0, 0, 1, 1, 1, 0, 0]], dtype=int64)
"""
#或者直接转化为array
dataset=np.array(dataset)
dataset
"""
array([['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '是'],
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '是'],
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '是'],
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '是'],
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '是'],
['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '是'],
['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', '是'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', '是'],
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', '否'],
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', '否'],
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', '否'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', '否'],
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', '否'],
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', '否'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '否'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', '否'],
['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', '否']], dtype=object)
"""
#计算数据集的信息熵
def Entropy(dataset):
#计算好瓜坏瓜比例
row_num=len(dataset)
label_count={}
for label in dataset[:,-1]:
label_count[label]=label_count.get(label,0)+1
#计算信息熵
Entropy=0
for key in label_count:
p=label_count[key]/row_num
Entropy -=p * log(p, 2)
return Entropy
#获取各个属性的小数据集
def get_data(dataset,feature_num,feature_value):
bool_ls=[]
for feature in dataset:
bool_ls.append(feature[feature_num]==feature_value)
data=dataset[bool_ls]
return data
feature_dic={0:"色泽",1:"根蒂",2:"敲声",3:"纹理",4:"脐部",5:"触感"}
for feature_num in range(dataset.shape[1]-1):
#获取属性的集合
feature_set=set(dataSet[:,feature_num])
data_entropy=0
#计算信息增益
for feature_value in feature_set:
data=get_data(dataset,feature_num,feature_value)
data_entropy+=(len(data)/len(dataSet))*(Entropy(data))
data_entropy=Entropy(dataset)-data_entropy
print("{}的信息增益为{:.3f}".format(feature_dic[feature_num],data_entropy))
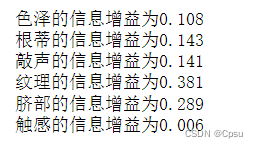
和西瓜书上的计算值一样。后续可以完善实现决策树算法。















 1041
1041











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









