







2020年发表在CVPR
原文链接:https://arxiv.org/pdf/2003.09163v2.pdf
使用本文方法进行目标检测的效果:

后面被遮挡着的人也被完全检测了出来!
1 目的
检测拥挤场景中高度重叠的实例。
2 关键
让一个提议(proposal)预测一组实例,而不是单个实例。
3 为什么在密集或遮挡情况下容易检测失败
主要有两个原因:
(1)高度重叠的实例(以及它们相关的提议)可能具有非常相似的特性。因此,检测器很难分别对每个提议产生有区别的预测。
(2)由于实例之间可能严重重叠,因此预测很可能被NMS错误地抑制。
(前面写过的DETR,即检测transformer,是一个预测框对应一个实例,且一个实例只对应一个预测框,所以就没有NMS后处理。)
4 我们的方案:一种思想三种技术
思想:
对于每个提议框,预测一组可能高度重叠的实例,而不是像往常一样预测单个实例。
技术:
(1)提出了一种EMD损耗来监督实例集预测的学习。
(2)提出了一种新的后处理方法Set NMS来抑制来自不同提议的重复。
(3)设计了一个可选的优化模块(RM)来处理潜在的误报。
4.1 多实例预测
对于每个提议框
b
i
b_i
bi,预测gt实例的相关集合
G
(
b
i
)
G(b_i)
G(bi):
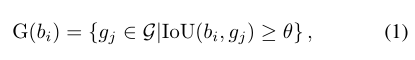
- G G G:所有gt框的集合。
- b i b_i bi:一个提议框。
- g j g_j gj:某个实例的真实框。
- θ \theta θ:给定的交并比阈值。

上图中
(
a
)
(a)
(a)是之前的预测方法,每个提议预测一个实例,而在重叠情况下,想要产生有区别的预测,是非常困难的;
(
b
)
(b)
(b)是我们的预测方法,红绿蓝三个框预测的都是刀子和叉子这两个实例。
实例集预测:
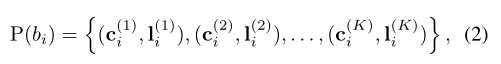
- ( c i ( x ) , l i ( x ) ) (c_i^{(x)},l_i^{(x)}) (ci(x),li(x)):代表一个相关实例。
- c i c_i ci:有置信度的类标签。
- l i l_i li:相对坐标。
- K K K:给定的常数,是数据集中 G ( b i ) G(b_i) G(bi)的最大基数,即一个提议框最多预测的真实框数量。
P ( b i ) P(b_i) P(bi)可以通过引入额外的预测分支在大多数现有的框架中被实现。如果一个提议框没有对应足够 K K K个实例,则多余的预测为背景类。
4.2 EMD loss
目标:最小化
P
(
b
i
)
P(b_i)
P(bi)与
G
(
b
i
)
G(b_i)
G(bi)之间的差距。可归为集合距离测量问题。
EMD损失:最小化两个集合之间的Earth Mover’s
Distance:

- π \pi π:表示一个特定的排列 ( 1 , 2 , . . . , K ) (1,2,...,K) (1,2,...,K),第 k k k项就是 π k \pi_k πk。
- g π k g_{\pi_k} gπk:是 G ( b i ) G(b_i) G(bi)中的一个元素,表示第 π k \pi_k πk个真实框。
- L c l s ( ⋅ ) L_{cls}(·) Lcls(⋅):分类损失。
- L r e g ( ⋅ ) L_{reg}(·) Lreg(⋅):回归损失。
背景类无回归损失。当 K = 1 K = 1 K=1时,Eq. 3等价于传统单实例预测框架中的损失。
4.3 Set NMS
每次在NMS算法中的一个框压制另一个框之前,插入一个额外的测试,以检查这两个框是否来自同一个提议。如果是,则跳过抑制。
4.4 Refinement module
减少误报情况。该模块简单地将预测作为输入,结合proposal feature,进行第二轮预测。我们希望优化模块纠正可能的错误预测。
5 网络体系结构
本文中,选择具有RoIAlign的FPN(特征金字塔网络)作为基线检测器。在FPN中,区域提议网络(RPN)分支负责生成提议,RCNN(或称为RoI)分支用于预测RoI提议对应的实例。我们的方法附加到后面的分支。在本文中超参数
K
K
K(即一个提议最多对应的实例)设为了2。

上图是总体结构。
(
a
)
(a)
(a)中的
b
o
x
A
box_A
boxA和
b
o
x
B
box_B
boxB是被一个提议预测的两个实例。优化模块是可选的。
(
b
)
(b)
(b)中优化模块将特征和框信息进行拼接,对结果进行优化。
6 结论
在本文中,提出了一种非常简单但有效的基于提议的目标检测器,专门为拥挤实例检测而设计。该方法利用了多实例预测的概念,引入了EMD损耗、Set NMS和优化模块等新技术。该方法不仅有效,而且灵活地与最先进的基于提议的检测框架结合;此外,还可以很好地推广到人群较少的场景。















 8938
8938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









