







 文章介绍了如何借助ChatGPT来创建一个关于社交媒体营销的在线课程,包括市场调研、选择细分领域、制定课程大纲、编写章节内容,并最终转化为PPT格式,同时考虑加入学员案例和参考范例。
文章介绍了如何借助ChatGPT来创建一个关于社交媒体营销的在线课程,包括市场调研、选择细分领域、制定课程大纲、编写章节内容,并最终转化为PPT格式,同时考虑加入学员案例和参考范例。
【ChatGPT】前些天发现了一个巨牛的人工智能学习资源,通俗易懂,风趣幽默,无广告,忍不住分享一下给大家。(点击查看学习资源)
该场景对应的关键词库(13个):
市场调研、在线网络课程、教学平台、社交媒体营销、子主题、细分领域、课程大纲、章节、推广渠道、课程脚本、文案基本要素、案例、具体方法
提问模板(6个):
第一步,做课程的市场调研
提问模板:
1、请列举10个在中国比较受欢迎的在线网络课程的教学平台;
2、请列举10个在XXX在线教育平台,有哪些受欢迎的、销量高的课程;
3、请从这些销量高的课程里面,筛选出与社交媒体营销(XXX主题)紧密相关的课程。
第二步,根据大的方向,再进行细化,你从中选择要主攻的细分领域
提问模板:
你是一个社交媒体营销(XXX子主题)专家,我想设计一个关于社交媒体营销(XXX子主题)的课程,在这个领域,有哪些更细化的主题可以选择?
第三步:根据细分领域的主题,生成课程大纲
提问模板:
根据主题:《如何在小红书规划社交媒体内容,包括:如何构思和制作有吸引力的文案、图片和视频,以及如何通过调研、竞品分析等方式提高内容创作的效率和质量》(XXX细分领域的主题名+该主题下包含的具体内容)
根据以上主题,帮我设计一门在线课程大纲,要求包含课程名称、课程亮点、课程目标用户、课程章节、课程推广渠道。
第四步:针对课程大纲里面的单独小节进行提问,让Chatgpt根据上面提问的回复,进行总结,最后生成对应主题的章节内容。
先针对某一个小节进行全方位提问:
提问模板:
1、根据《创作有吸引力的小红书文案(复制上面的课程大纲里的某一节标题)》,写一个课程脚本
2、请对主题《了解小红书的文案基本要素(复制上面的课程大纲里的某一节标题)》,进行详细解释
3、针对以上的内容,能给我举一些具体的案例吗?并且提供10个XXX领域(复制主题名称)的XX(名词)
4、目前国际上有哪些比较流行的、高效的(列举2-3个形容词)XXX(具体方法),请为我做详细说明
5、帮我展开详细介绍一下这个主题:《创作有吸引力的小红书文案(复制上面的课程大纲里的某一节标题)》
针对某一个小节提问完毕后,再继续提问:
提问模板:
结合上面刚刚你提到的一些XXX(具体方法/名词),帮我写一个章节内容。
主题是《XXXXX》(直接复制上面的课程大纲里的某一节标题)
如果写到2000字就不写了,那就复制ChatGPT所说的最后一句话,然后告诉它请从这里继续往下写。
第五步,将章节内容转换成PPT格式
提问模板:
1、请将以上脚本转换为幻灯片演示文本;
2、帮我把上面这个章节的内容,转写成PPT里面每一页的内容(包含:标题、副标题、正文、话题标签)
第六步,将学员案例、参考范例加进去,让chatgpt根据某个主题进行改写或者续写。
提问模板:
1、请参考以下示例:XXXX(输入学员的案例描述),帮我根据《创作有吸引力的小红书文案》(XX主题)进行改写;
2、请参考以下范本:XXX(输入参考范例,根据《创作有吸引力的小红书文案》(XX主题)进行续写。
案例:
第一步,做课程的市场调
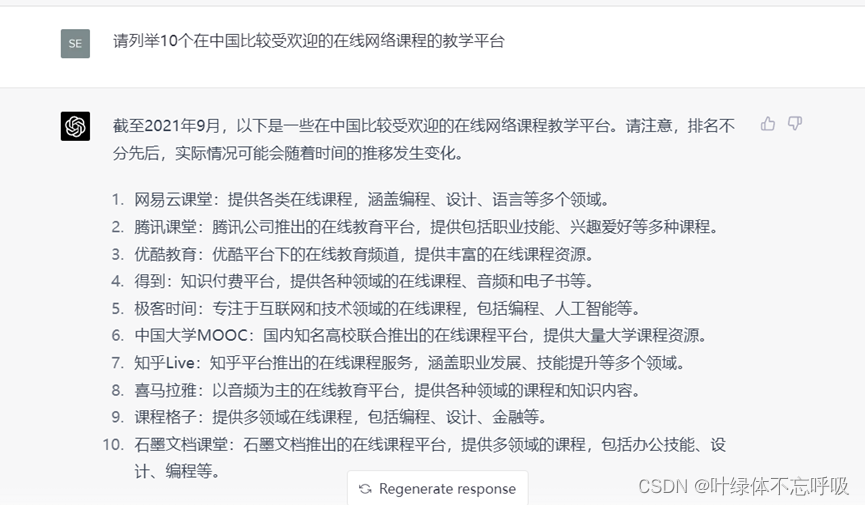
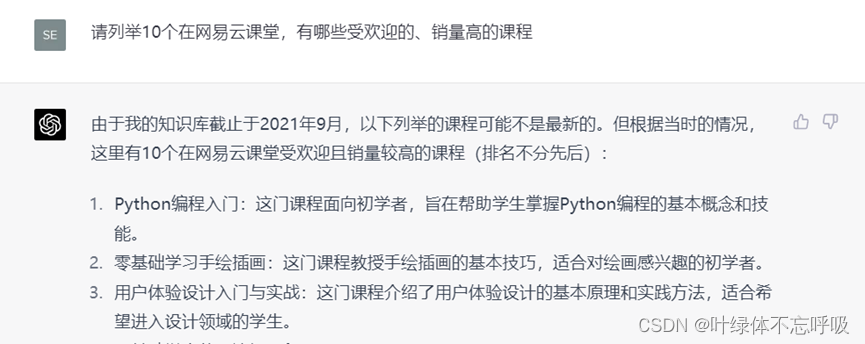
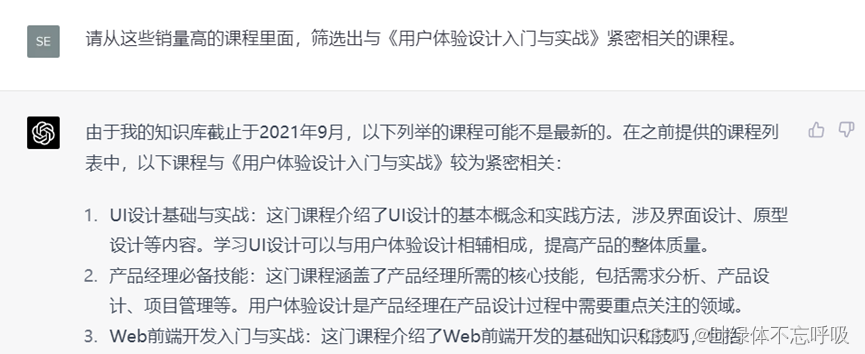
第二步,根据大的方向,再进行细化,你从中选择要主攻的细分领域。

第三步:根据细分领域的主题,生成课程大纲。


第四步:针对课程大纲里面的单独小节进行提问,总结,最后生成对应主题的章节内容。

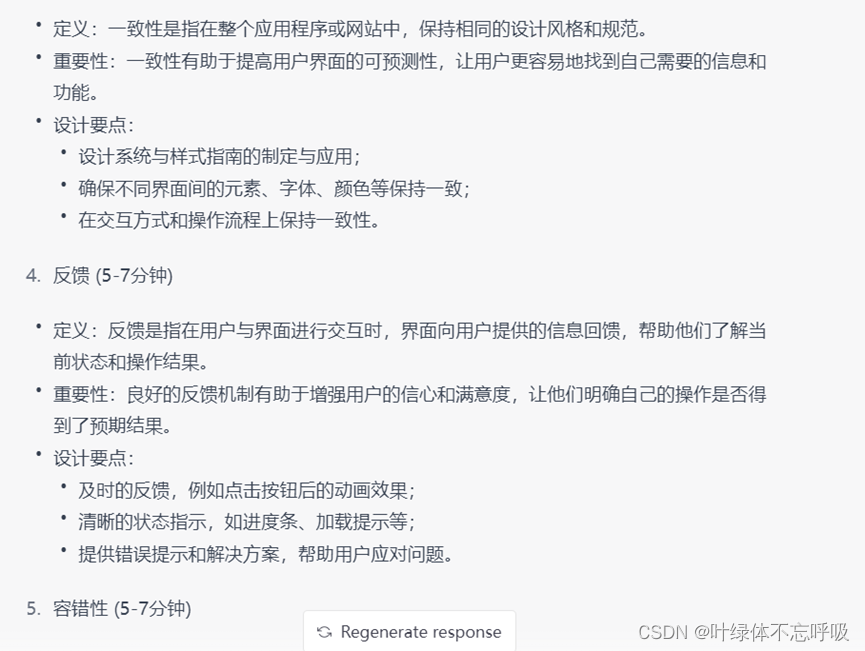


第五步,将章节内容转换成PPT格式。
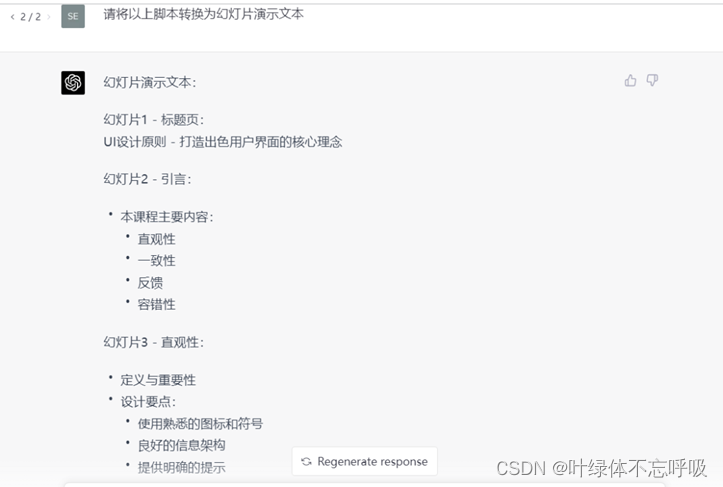


第六步,将学员案例、参考范例加进去,让chatgpt根据某个主题进行改写或者续写。
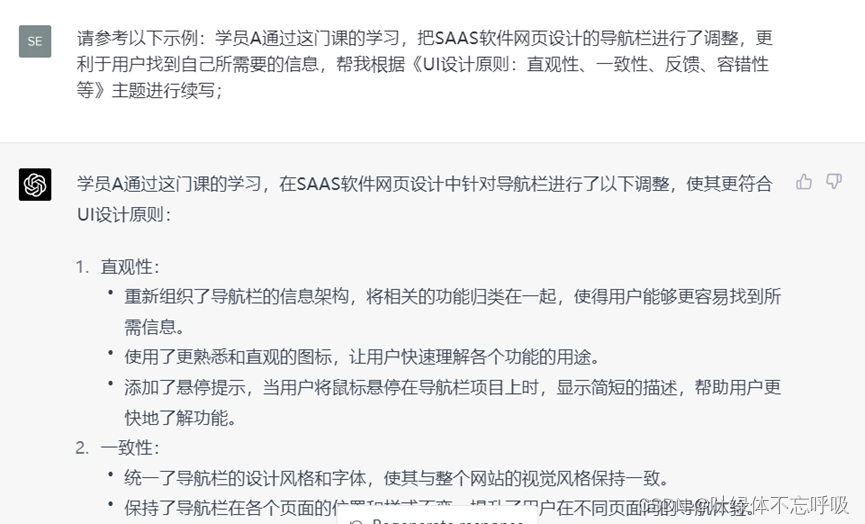



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











