






Medical-Transformer
论文链接:Medical Transformer: Gated Axial-Attention for Medical Image Segmentation
官方链接:Medical-Transformer
可以先了解一下这篇论文,因为Medical-Transformer就是效仿ta的:Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation
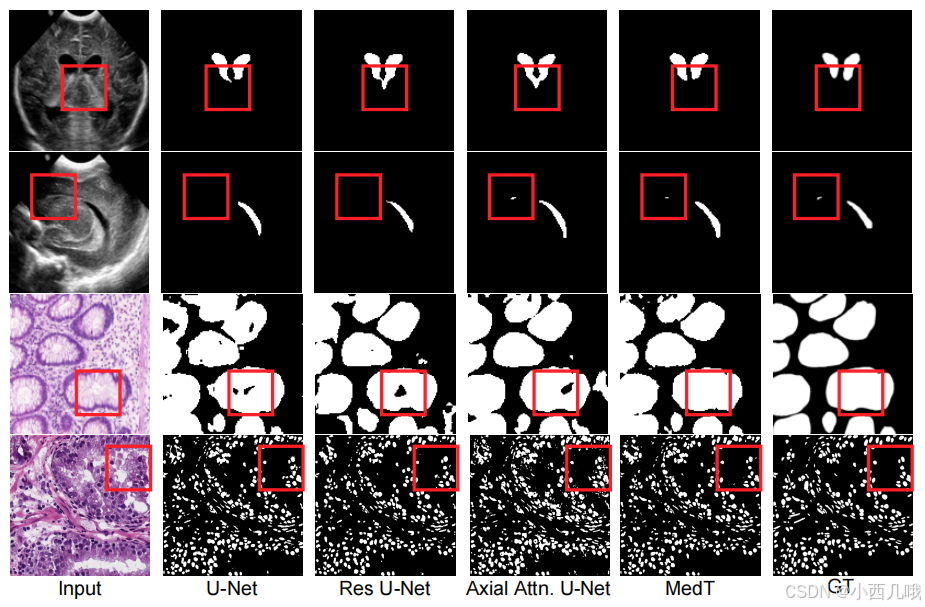
看看效果,医学的细胞图像分割,上面一行是预测的,下面一行是真实标签。我就跑了400个epochs,数据集也比较小,跑了几分钟,所以效果可能没那么明显的好。

这个是官方给的一个对比图
Medical-Transformer总体流程
1、图像模型里引入Transformer一般采用的都是2D self-attention,即把图片上按H和W维上的每个像素点都算一遍互相之间的关系。这个计算量肯定是不小的,可不可以给它转为1D self-attention呢。
那当然是可以的,规则就是用来打破的。如何做呢?
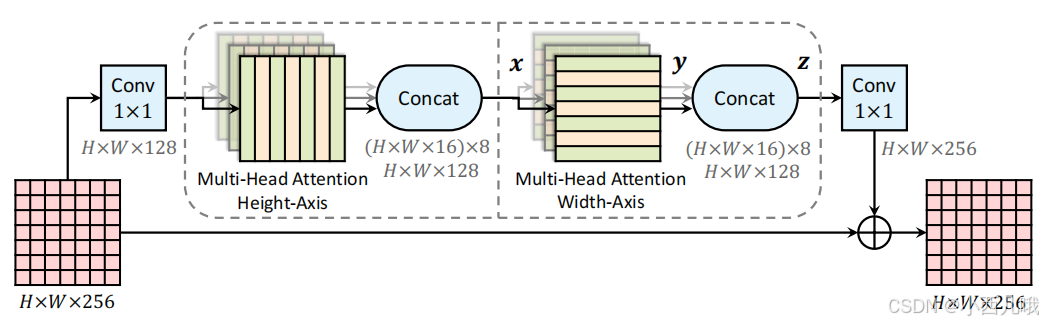
原来每个像素点需要计算与其它所有像素点的关系,但是现在,no! 如上图,一个特征图输入进来经过一个conv之后,先计算每个像素点在同一列的关系,再计算同一行的关系。假设输入一个HW为256的特征图,原来的self-attention的计算量得是(256×256)的平方,而现在,只需2×(256+256)!
诶,肯定有人要说了,你这投机取巧确实大大降低了计算量,但是你也丢失了很多全局信息啊。官话解释呢就是,虽然每个像素仅感知自己所在的行和列信息,但是经过前一层的信息传递后,每个像素间接获得更大范围的感知。经过足够多的层次,信息能够在整个图像中逐渐扩散,相当于弥补了局部信息的不足。这种逐步建模全局关系的方式是不是很像CNN卷积叠加扩大感受野的思想。糙人解释呢,你管ta呀,效果好就行,这神经网络不可解释性多了去了。越是贪图圆满,越是搜不干净——黑神话:悟空,阿弥陀佛。
2、图像模型里引入Transformer,一般会切成好几块patch,然后给每块patch敷衍的加个位置编码。但是好像没有哪个会给qkv也加个位置编码吧,这似乎也是个突破点。
有Transformer基础一眼鉴定下图左边的这个结构,标准的qkv计算。而右边的这个结构就是加了位置编码信息。
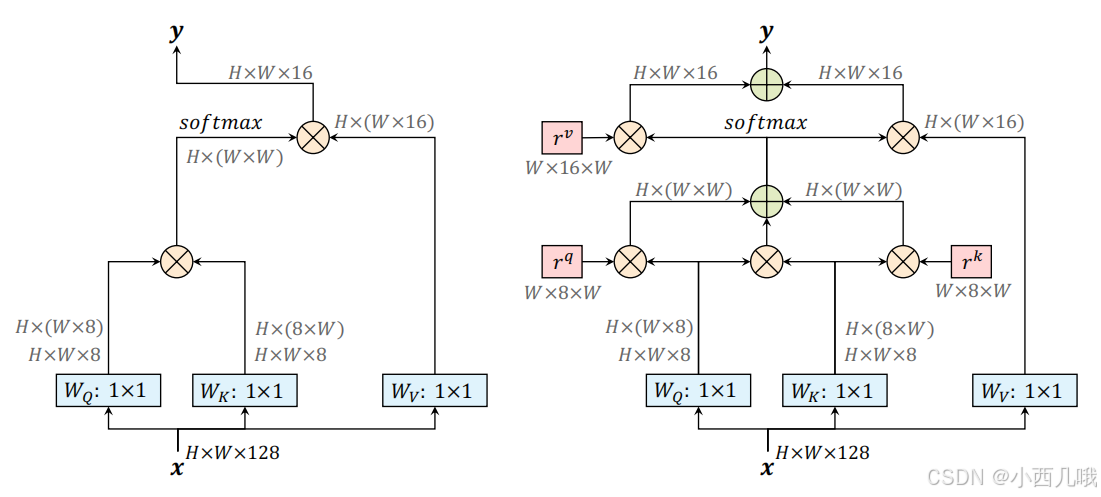
这个位置编码怎么解释呢,很抽象啊,为什么给qkv也加位置编码呢,烧脑壳。它和普通的位置编码还不一样,正常会加上一个位置编码,用的是绝对位置。这个是乘上一个位置编码,用的是相对位置。然后还会将加了位置编码的q和加了位置编码的k和qk的内积融合在一起…具体公式如下
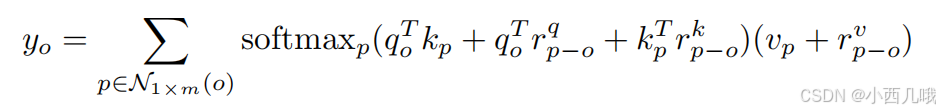
啊呀啊呀,我也不知道为啥这样做效果会变好,到时候代码里讲一下怎么做的吧,至于为什么这么做就交给…
开头有说Medical-Transformer借鉴了另一篇论文的东西,没错,就是在别人qkv计算的结构上加了一个门控单元,如下图。
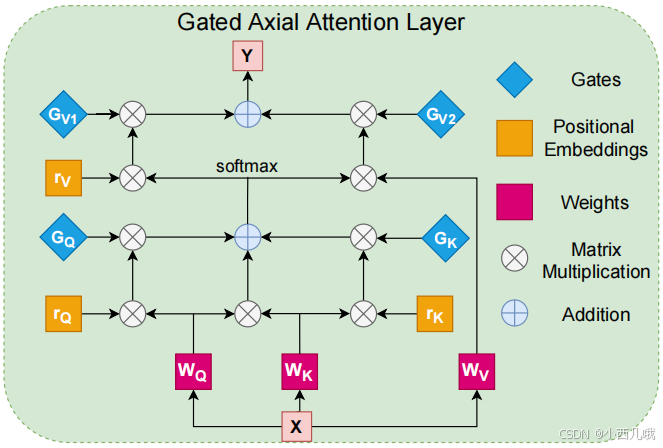
这个门控单元怎么听起来高大上啊,它对这个结构进行了怎样的一个优化啊?论文里写了个长篇大论介绍这个门控单元,去源码里一看就是加了几行代码。其实很好理解,就把它当成一个可学习的权重项,初始化是一个很小的值,比如0.1。乘一个零点几的数不就是弱化了位置编码的作用嘛。很简单的一个设计,效果却很好。
(这让我想到前几天老师让我给我的一篇论文申请个专利,我勒个心虚的一批,我只是在别人算法的基础上加了个差不多十行代码做了个优化就成我的东西了?又让我想起来本科的毕设,那个老师也让我申请专利,也给我整的支支吾吾,核心内容是直接调用别人的so库)
总体流程呢如下图
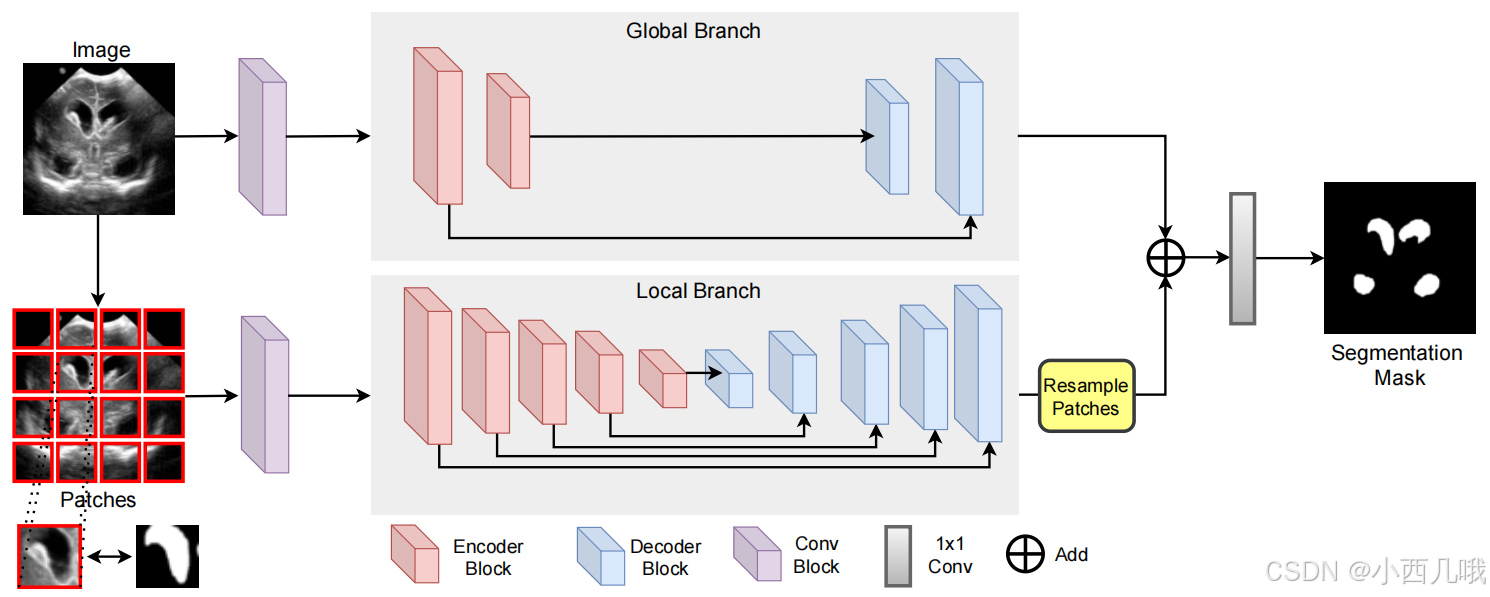
分了两步走,上面是直接对整个图片做全局特征提取,下面是给图片切成4×4个小块,然后对每个小块做局部的特征提取,最后将全局的和局部的融合在一起,得到最终输出。发现全局的做了两层Enconder Block,局部的做了好几层。比较官方的解释呢,全局特征提取采用 较浅的网络以获取整体结构信息,而局部特征提取采用更深的网络以学习细节信息,从而形成互补。也可以这样理解一下,全局的图片是128×128的,局部的是32×32的,那全局做Enconder Block计算量大啊,计算时间得长,那乘这个时间,局部的多做几轮,反正最后要一起融合,等着也是等着。
代码
配置一下参数运行。
--train_dataset
nucleus/train # 换自己的数据集路径
--val_dataset
nucleus/val # 换自己的数据集路径
--imgsize
128 # 换自己的数据集的size
数据准备
数据准备这里要说明一下,我自己用的数据集是1000×1000像素的图片,这么大像素肯定跑不动的,batch_size设为1都超显存。论文里用的图片size是128,如果是学习的话建议也用128size的图片。我采用了简单粗暴的方式,直接resize为128。
在utils.py的ImageToImage2D下的方法__getitem__中添加了两行代码
def __getitem__(self, idx):
image_filename = self.images_list[idx]
image = cv2.imread(os.path.join(self.input_path, image_filename))
image = cv2.resize(image, (128, 128)) # 添加的代码
# read mask image
mask = cv2.imread(os.path.join(self.output_path, image_filename[: -3] + "png"), 0)
mask = cv2.resize(mask, (128, 128)) # 添加的代码
mask[mask <= 127] = 0
mask[mask > 127] = 1
# correct dimensions if needed
image, mask = correct_dims(image, mask)
if self.joint_transform:
image, mask = self.joint_transform(image, mask)
if self.one_hot_mask:
assert self.one_hot_mask > 0, 'one_hot_mask must be nonnegative'
mask = torch.zeros((self.one_hot_mask, mask.shape[1], mask.shape[2])).scatter_(0, mask.long(), 1)
return image, mask, image_filename
代码里没对图像数据做啥预处理。
我自己用的数据是nucleus,下载链接:夸克网盘分享
去官方源码的链接里也有数据集的下载,不过下载下来的格式是xml的,需要自己处理一下格式。可以直接在github上搜索这个数据集的名字,会有很多人分享转格式的代码和数据集的。
Model
直接进入主题了兄弟们,到在lib/models路径下,axialnet.py里medt_net下的方法_forward_impl,看看怎么个事。
Gloabl
代码较长,分两端讲,先看一个全局是怎么做的。
def _forward_impl(self, x):
xin = x.clone() # (b,3,128,128)
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.conv3(x)
x = self.bn3(x)
x = self.relu(x) # (b,8,64,64)
x1 = self.layer1(x) # (b,32,64,64)
x2 = self.layer2(x1) # (b,64,32,32)
x = F.relu(F.interpolate(self.decoder4(x2), scale_factor=(2, 2), mode='bilinear')) # (b,32,64,64)
x = torch.add(x, x1)
x = F.relu(F.interpolate(self.decoder5(x), scale_factor=(2, 2), mode='bilinear')) # (b,16,128,128)
先来一波简单的三件套conv->bn->relu,给图片进行一个特征提取,将原图的(b,3,128,128)->(b,8,64,64)。ok,重点就是这个self.layer,我们来看看怎么个事。
AxialAttention_dynamic
我们跳到AxialAttention_dynamic的forward方法中
def forward(self, x):
if self.width:
x = x.permute(0, 2, 1, 3)
else:
x = x.permute(0, 3, 1, 2) # N, W, C, H
N, W, C, H = x.shape
x = x.contiguous().view(N * W, C, H) # (b×64,16,64) 只对H或W做操作了
# Transformations
qkv = self.bn_qkv(self.qkv_transform(x)) # (b×64,32,64)->q(b×64,8,1,64) k(b×64,8,1,64) v(b×64,8,2,64)
q, k, v = torch.split(qkv.reshape(N * W, self.groups, self.group_planes * 2, H),
[self.group_planes // 2, self.group_planes // 2, self.group_planes], dim=2)
# Calculate position embedding (4,64,64) 4->(q,k,v1,v2) (64,64)->每个点与每个点的相对位置信息
all_embeddings = torch.index_select(self.relative, 1, self.flatten_index).view(self.group_planes * 2,
self.kernel_size, self.kernel_size)
q_embedding, k_embedding, v_embedding = torch.split(all_embeddings, [self.group_planes // 2, self.group_planes // 2,
self.group_planes], dim=0)
qr = torch.einsum('bgci,cij->bgij', q, q_embedding) # (b×64,8,64,64)
kr = torch.einsum('bgci,cij->bgij', k, k_embedding).transpose(2, 3) # (b×64,8,64,64)
qk = torch.einsum('bgci, bgcj->bgij', q, k) # (b×64,8,64,64)
# multiply by factors
qr = torch.mul(qr, self.f_qr)
kr = torch.mul(kr, self.f_kr)
stacked_similarity = torch.cat([qk, qr, kr], dim=1)
stacked_similarity = self.bn_similarity(stacked_similarity).view(N * W, 3, self.groups, H, H).sum(dim=1)
# (N, groups, H, H, W)
similarity = F.softmax(stacked_similarity, dim=3)
sv = torch.einsum('bgij,bgcj->bgci', similarity, v) # (b×64,8,2,64)
sve = torch.einsum('bgij,cij->bgci', similarity, v_embedding) # (b×64,8,2,64)
# multiply by factors
sv = torch.mul(sv, self.f_sv)
sve = torch.mul(sve, self.f_sve)
stacked_output = torch.cat([sv, sve], dim=-1).view(N * W, self.out_planes * 2, H) # (b×64,32,64)
output = self.bn_output(stacked_output).view(N, W, self.out_planes, 2, H).sum(dim=-2) # (b,64,16,64)
# 输入与输出的size一样
if self.width:
output = output.permute(0, 2, 1, 3)
else:
output = output.permute(0, 2, 3, 1)
if self.stride > 1:
output = self.pooling(output)
return output
首先判定一下是对列做Attention还是对行做Attention,如果是对列做,就将行维度的数据放到batch那个维度里不管了。
这里的self.qkv_transform一次性给qkv计算出来,然后再分割开来。qk的维度是(b×64,8,1,64),而v的维度是(b×64,8,2,64)。我估计是为了最后输出的维度与输入的维度相同,所以给了v两倍的维度。(注:self.groups = 8表示8个注意力头,self.group_planes = 2表示每个头的通道数,qk 共享 2×8个通道,而 v独享 2×8个通道)。
all_embeddings会先初始化为一些随机的位置编码,然后切给qkv,qk的维度是(1,64,64),v是(2,64,64)。然后通过torch.einsum高级语法对q和q的位置编码、v和v的位置编码、q和v分别做内积,得到三个维度为(b×64,8,64,64)。
好,qr和kr乘上一个门控单元,这里的self.f_qr和self.f_kr就是我说的门控单元,给你们看一下它的表达形式。
self.f_qr = nn.Parameter(torch.tensor(0.1), requires_grad=False)
self.f_kr = nn.Parameter(torch.tensor(0.1), requires_grad=False)
将刚刚算的三个内积拼接一下(b×64,24,64,64),做个BN然后再view为(b×64,3,8,64,64),沿一维求和得到(b×64,8,64,64),最后做个softmax得到similarity。
通过torch.einsum高级语法对similarity与v、similarity与v的位置编码做内积,得到维度(b×64,8,2,64)。同理,这里也乘上门控单元,然后拼接->bn->view->sum,得到最终输出
(b,64,16,64)。再给它permute为原来的模样(b,16,64,64)。
这部分代码会先对列做一遍,然后再对行做一遍,一样的逻辑。最后上采样给还原回原来的size。
Local
全局做完了,再来看看局部是怎么个事。
x_loc = x.clone()
# start
for i in range(0, 4): # 横竖分别切分4块 做局部特征
for j in range(0, 4):
x_p = xin[:, :, 32 * i:32 * (i + 1), 32 * j:32 * (j + 1)] # 128/32 =4
# begin patch wise
x_p = self.conv1_p(x_p)
x_p = self.bn1_p(x_p)
x_p = self.relu(x_p)
x_p = self.conv2_p(x_p)
x_p = self.relu(x_p)
x_p = self.conv3_p(x_p)
x_p = self.bn3_p(x_p)
x_p = self.relu(x_p)
x1_p = self.layer1_p(x_p) # 与全局不同的是 局部没有qkv的位置编码信息
x2_p = self.layer2_p(x1_p)
x3_p = self.layer3_p(x2_p)
x4_p = self.layer4_p(x3_p)
x_p = F.relu(F.interpolate(self.decoder1_p(x4_p), scale_factor=(2, 2), mode='bilinear'))
x_p = torch.add(x_p, x4_p)
x_p = F.relu(F.interpolate(self.decoder2_p(x_p), scale_factor=(2, 2), mode='bilinear'))
x_p = torch.add(x_p, x3_p)
x_p = F.relu(F.interpolate(self.decoder3_p(x_p), scale_factor=(2, 2), mode='bilinear'))
x_p = torch.add(x_p, x2_p)
x_p = F.relu(F.interpolate(self.decoder4_p(x_p), scale_factor=(2, 2), mode='bilinear'))
x_p = torch.add(x_p, x1_p)
x_p = F.relu(F.interpolate(self.decoder5_p(x_p), scale_factor=(2, 2), mode='bilinear'))
x_loc[:, :, 32 * i:32 * (i + 1), 32 * j:32 * (j + 1)] = x_p
x = torch.add(x, x_loc) # (b,16,128,128)
x = F.relu(self.decoderf(x))
x = self.adjust(F.relu(x)) # (b,2,128,128)
这里得注意了,这边的值都是写死的。它是直接按输入图片size为128,然后切成4×4个小块,那么每块的大小就是32×32。(注:如果你输入的是其它size的图片,得改一下这边的代码。这是其中之一吧,可能下采样的地方也得改。)
局部部分的代码逻辑其实和全局的一样的,只不过多做了几次卷积,多做了几次Attention。这里的Attention走的是AxialAttention_wopos下的forward,唯一的区别就是这里的qkv没加位置编码的信息,其它和全局是一样的,就不做多讲解了。做完之后上采样还原回原来size,按顺序放回x_loc。
最后将全局的和局部的信息相加,来点卷积,得到最终输出。

















 1196
1196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









