







0,前言
在经过接近一个月的从头编写与调试(调了四天),终于实现了与上位机的交互。一共编写了两个测试工程,loopback与speed_test。简单介绍下各自实现的功能。
loopback:
- 上位机修改ip,可进行修改ip后的icmp,arp,udp;
- 添加了vio控制xgmii_resrt,添加vio控制FPGA进行主动arp;
- 基本回环数据测试。
speed_test:
- 发送数据以axi_len == 184(udp的最大长度为1472,我们是8byte(64b))发送,但是尾端last按ff->80的顺序循环你发送,测试个鬼模块中尾端Keep的处理是否达到目的要求;
- 发送数据以axi_len == 184, 尾端keep一直为ff,极限速率。
1,xcku060_10g_ethernet_loopback
1.1,上位机修改ip,可进行修改ip后的icmp,arp,udp。
首先以下为顶层定义的数据:
module xcku060_10g_ethernet_top_speed_test
#(
parameter P_SOURCE_MAC = 48'ha1_b2_c3_d4_e5_f6,
parameter P_TARGET_MAC = 48'hff_ff_ff_ff_ff_ff,
// parameter P_SOURCE_IP = 32'hc0_a8_01_01,
// parameter P_TARGET_IP = 32'hc0_a8_01_0a,
parameter P_SOURCE_IP = {8'd192,8'd168,8'd1,8'd10},
parameter P_TARGET_IP = {8'd192,8'd168,8'd1,8'd100},
parameter P_SOURCE_PORT = 16'd8080 ,
parameter P_TARGET_PORT = 16'd8080
)
(
input i_sys_clk_p ,
input i_sys_clk_n ,
input i_mgtrefclk_p ,
input i_mgtrefclk_n ,
output o_gt_tx_p ,
output o_gt_tx_n ,
input i_gt_rx_p ,
input i_gt_rx_n ,
output o_sfp_disable
);源IP:192,168.1.10; 目的IP:192.168.1.100。
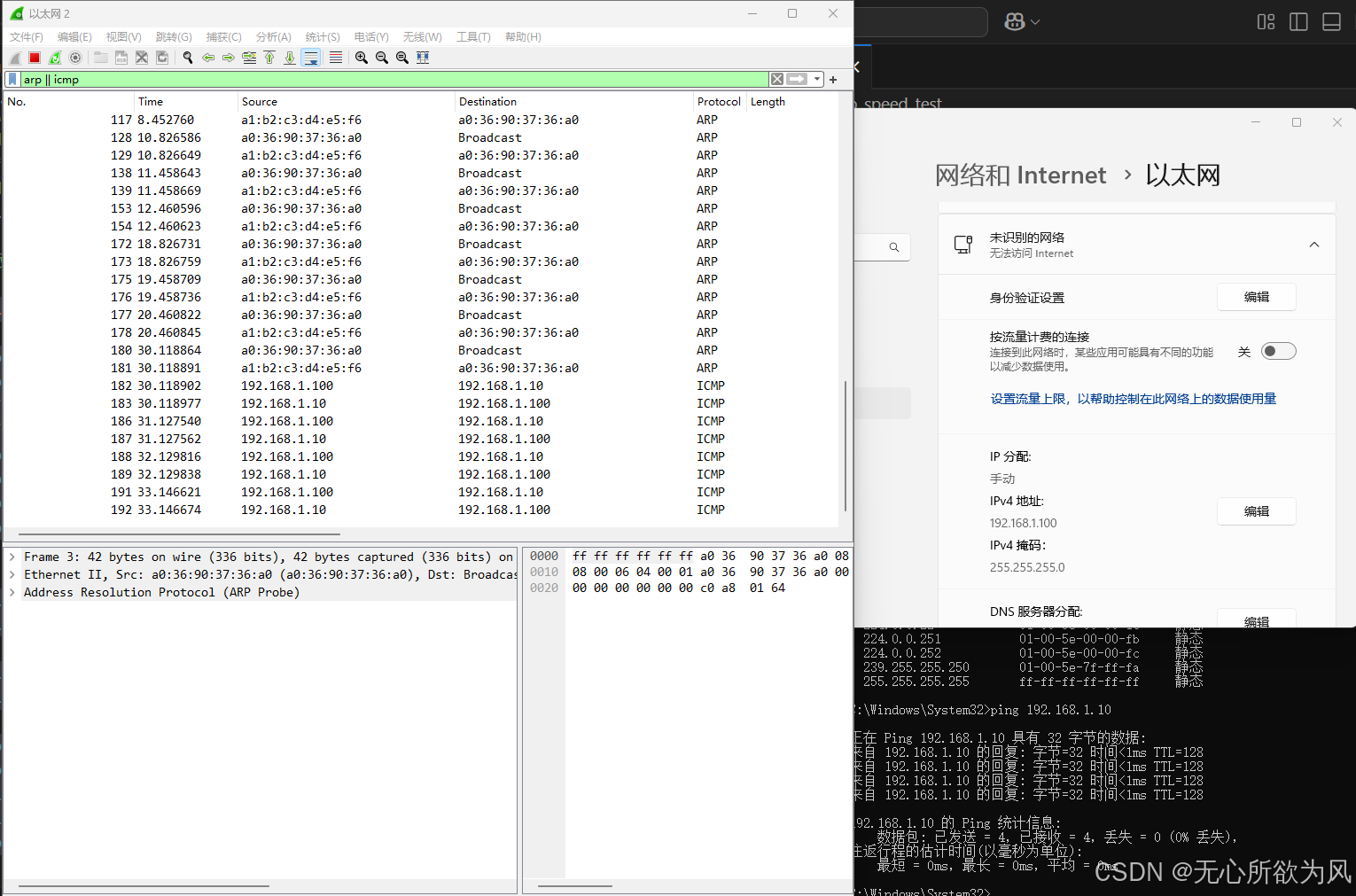
接下来我们修改上位机的IP地址:192.168.1.120。再次ping(不用更新FPGA程序)
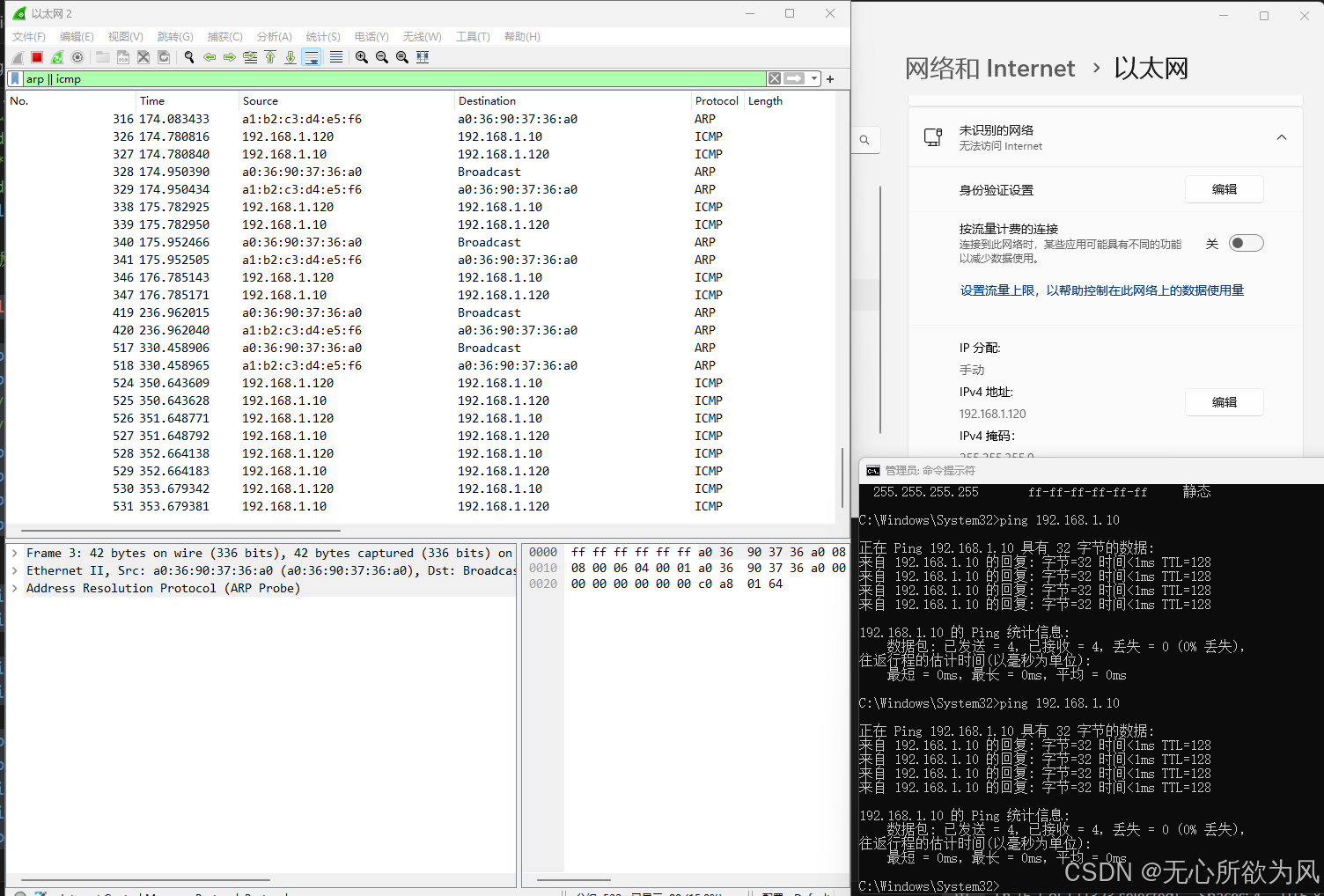
可以看到,在上位修改完IP之后,任然可以ping通。
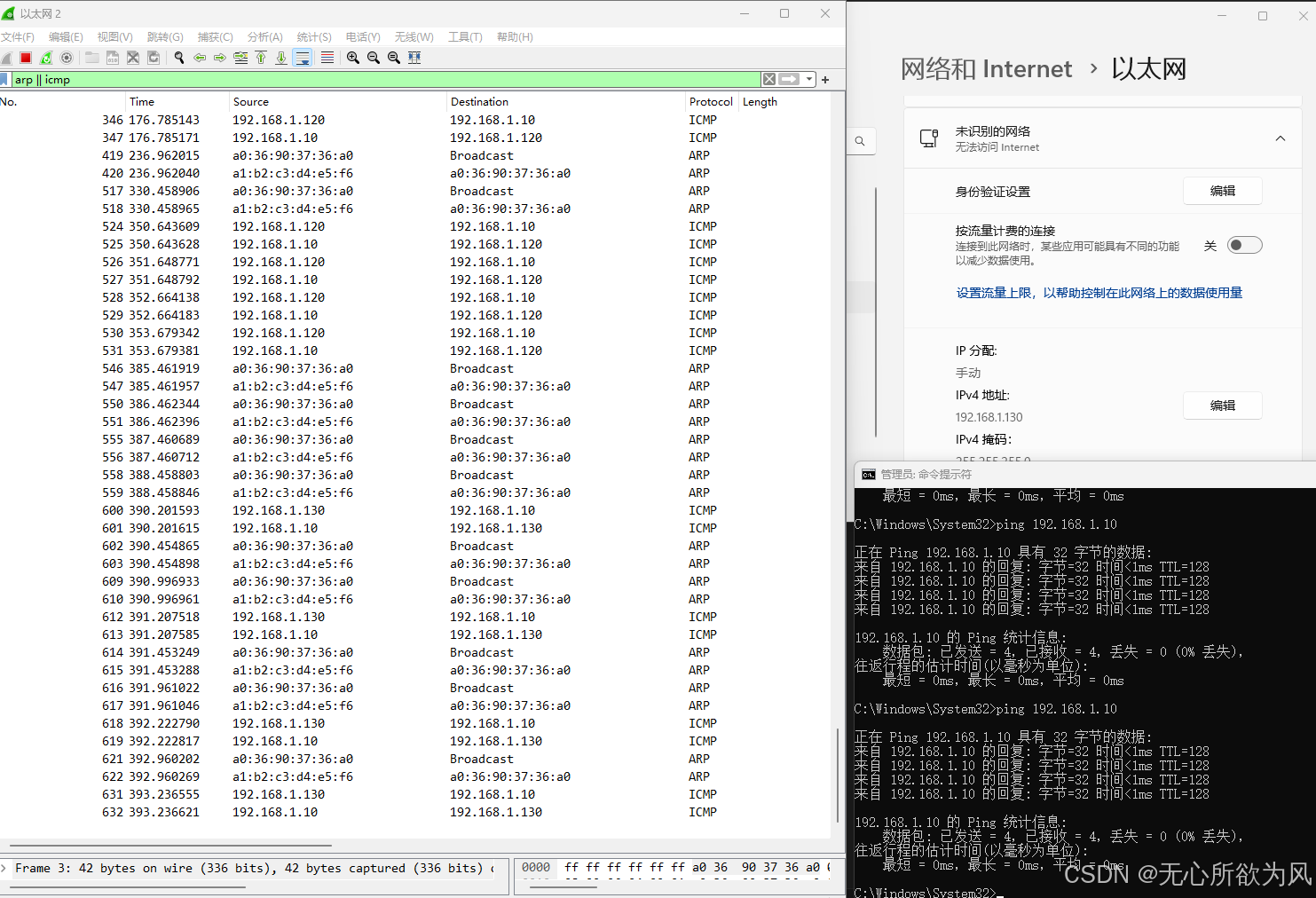
再次修改为192.168.1.130,任然可以ping通。
1.2,添加了vio控制xgmii_resrt,添加vio控制FPGA进行主动arp。
添加了vio用与控制复位与主动arp。

vio_reset:
用与复位FPGA板卡的udp_stack模块。拉高可以看到以太网2断开。
vio_arp_active
拉高触发一次主动arp:
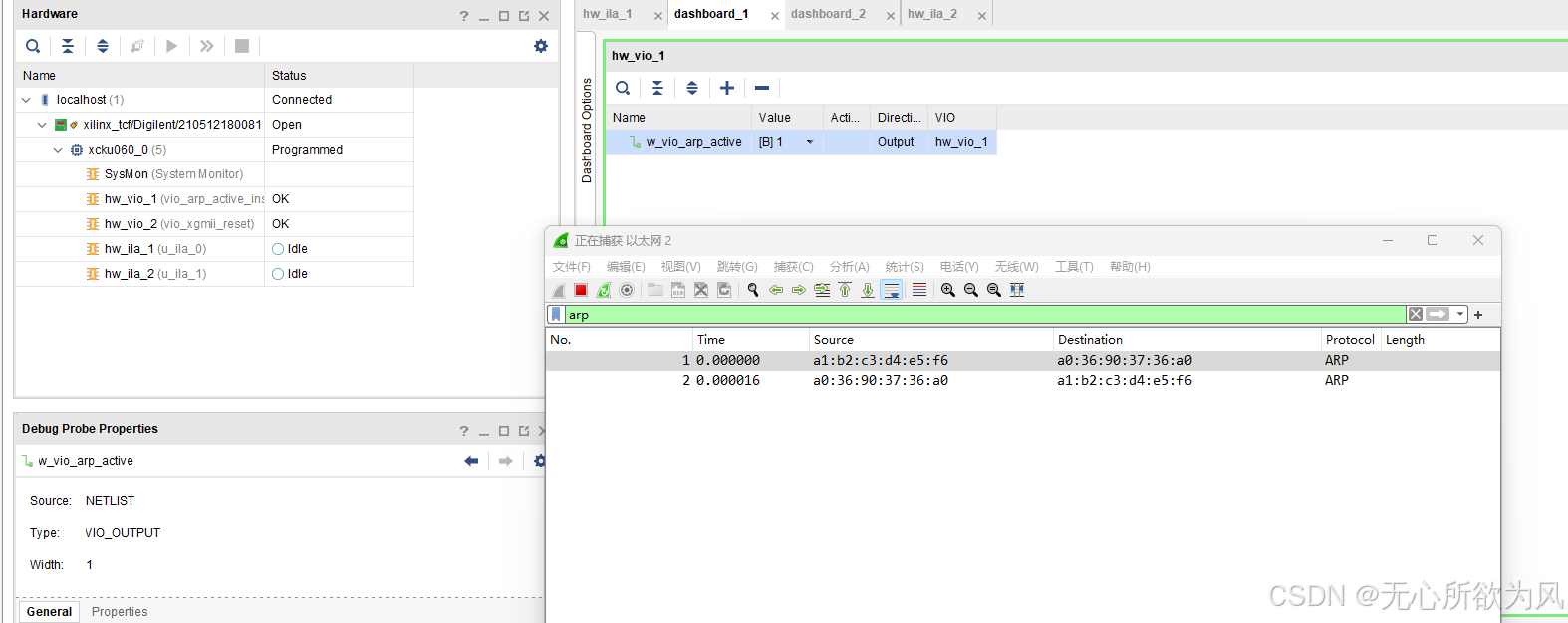
ila抓取:
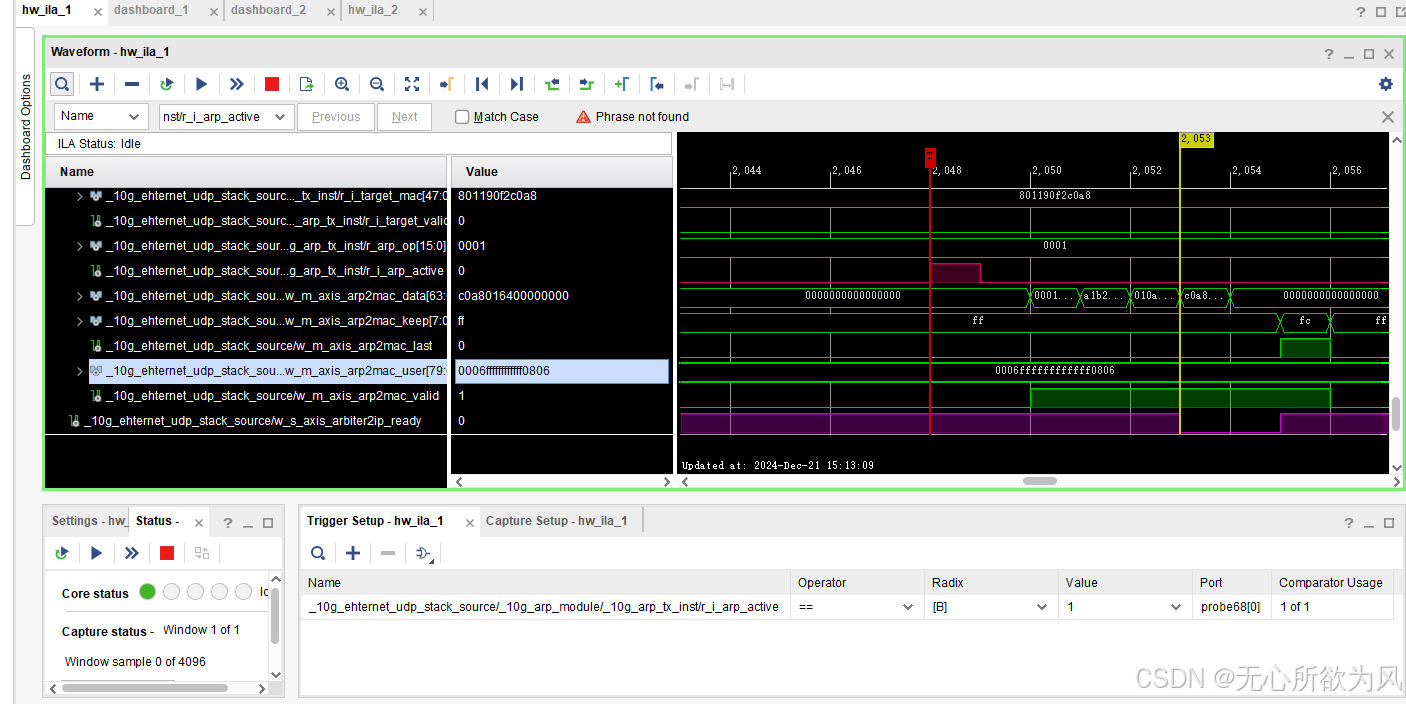
3,基本回环数据测试。
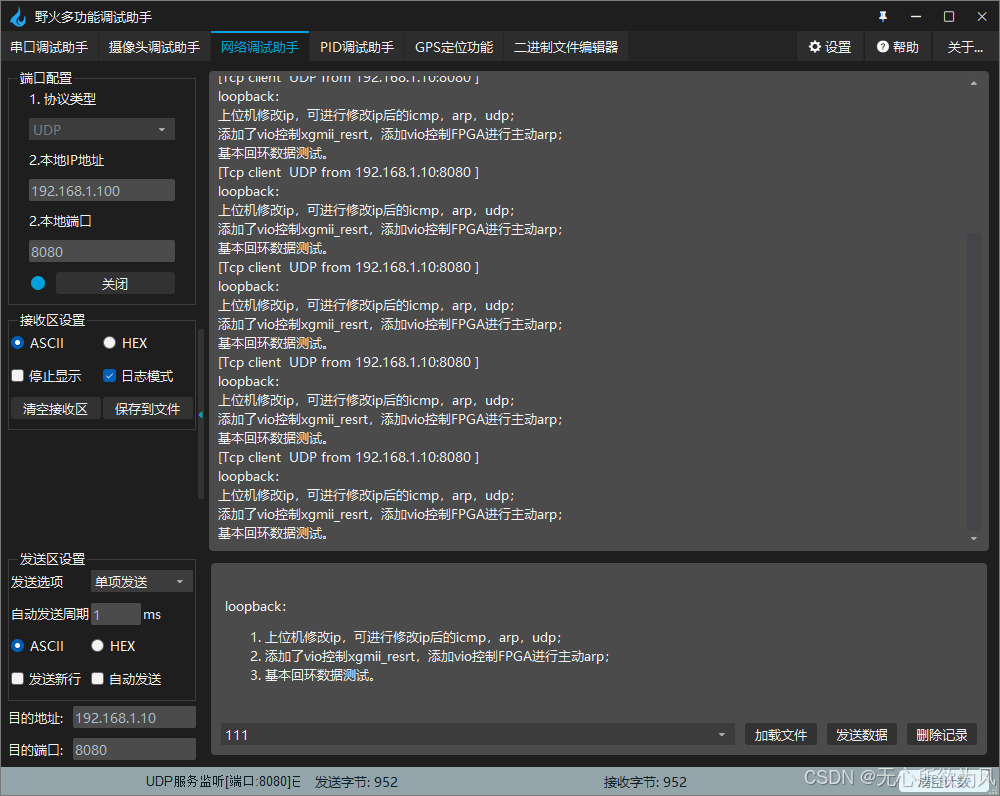
使用任意一个网络助手,设置好ip与端口号。
进行回环测试:
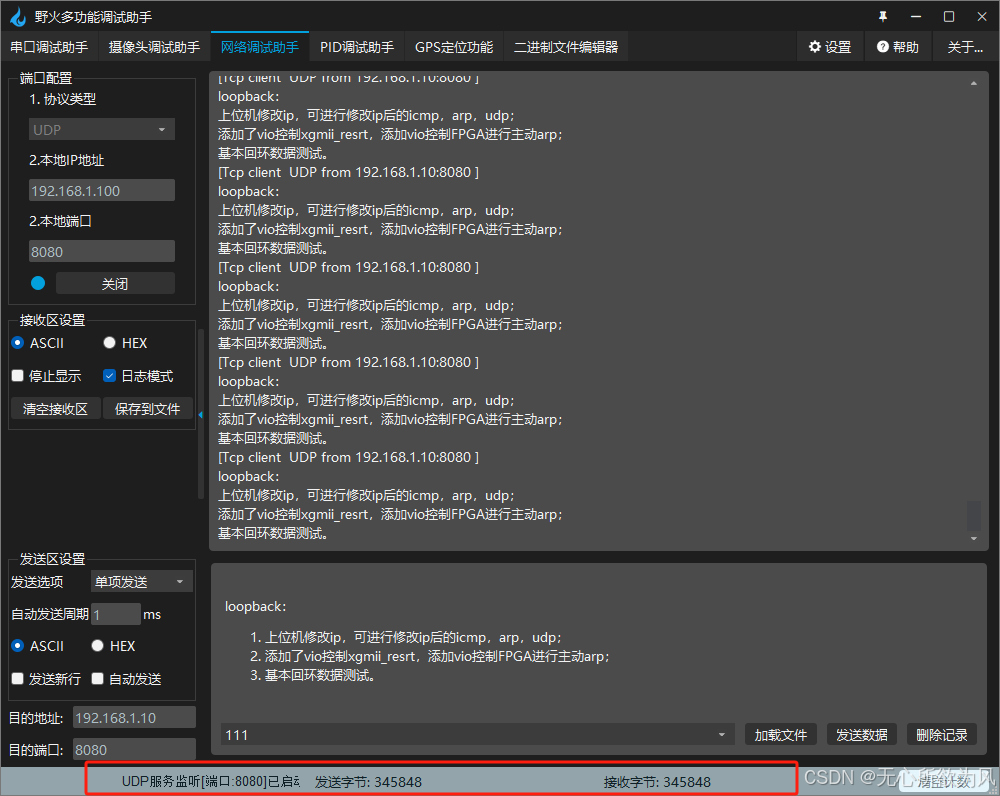
长时间传递后,数据接受数目与发送数目一致,并未出现数据丢失情况
2,xcku060_10g_ethernet_speed_test
2.1,last_keep循环
生成的原理如下:
/************** 循环发送,验证last_keep处理 *********************/
always @(posedge i_clk) begin
if (i_rst) begin
r_m_axis_keep <= 'd0;
end
//循环测试last_keep
else if(r_send_cnt == P_SEND_LEN + 1) begin
case (r_loop_last_cnt)
0 : r_m_axis_keep <= 8'b1000_0000 ;
1 : r_m_axis_keep <= 8'b1100_0000 ;
2 : r_m_axis_keep <= 8'b1110_0000 ;
3 : r_m_axis_keep <= 8'b1111_0000 ;
4 : r_m_axis_keep <= 8'b1111_1000 ;
5 : r_m_axis_keep <= 8'b1111_1100 ;
6 : r_m_axis_keep <= 8'b1111_1110 ;
7 : r_m_axis_keep <= 8'b1111_1111 ;
default : r_m_axis_keep <= 8'b1111_1111 ;
endcase
// r_m_axis_keep <= P_LAST_KEEP;
end
else begin
r_m_axis_keep <= 8'b1111_1111;
end
end
always @(posedge i_clk) begin
if (i_rst) begin
r_data_len <= 'd0;
end
else if(r_send_cnt == 1) begin
case (r_loop_last_cnt)
0 : r_data_len <= (P_SEND_LEN - 1)* 8 + 1 ;
1 : r_data_len <= (P_SEND_LEN - 1)* 8 + 2 ;
2 : r_data_len <= (P_SEND_LEN - 1)* 8 + 3 ;
3 : r_data_len <= (P_SEND_LEN - 1)* 8 + 4 ;
4 : r_data_len <= (P_SEND_LEN - 1)* 8 + 5 ;
5 : r_data_len <= (P_SEND_LEN - 1)* 8 + 6 ;
6 : r_data_len <= (P_SEND_LEN - 1)* 8 + 7 ;
7 : r_data_len <= (P_SEND_LEN - 1)* 8 + 8 ;
default : r_data_len <= P_SEND_LEN * 8 ;
endcase
end
else begin
r_data_len <= r_data_len;
end
end
上板ila抓取波形如下:
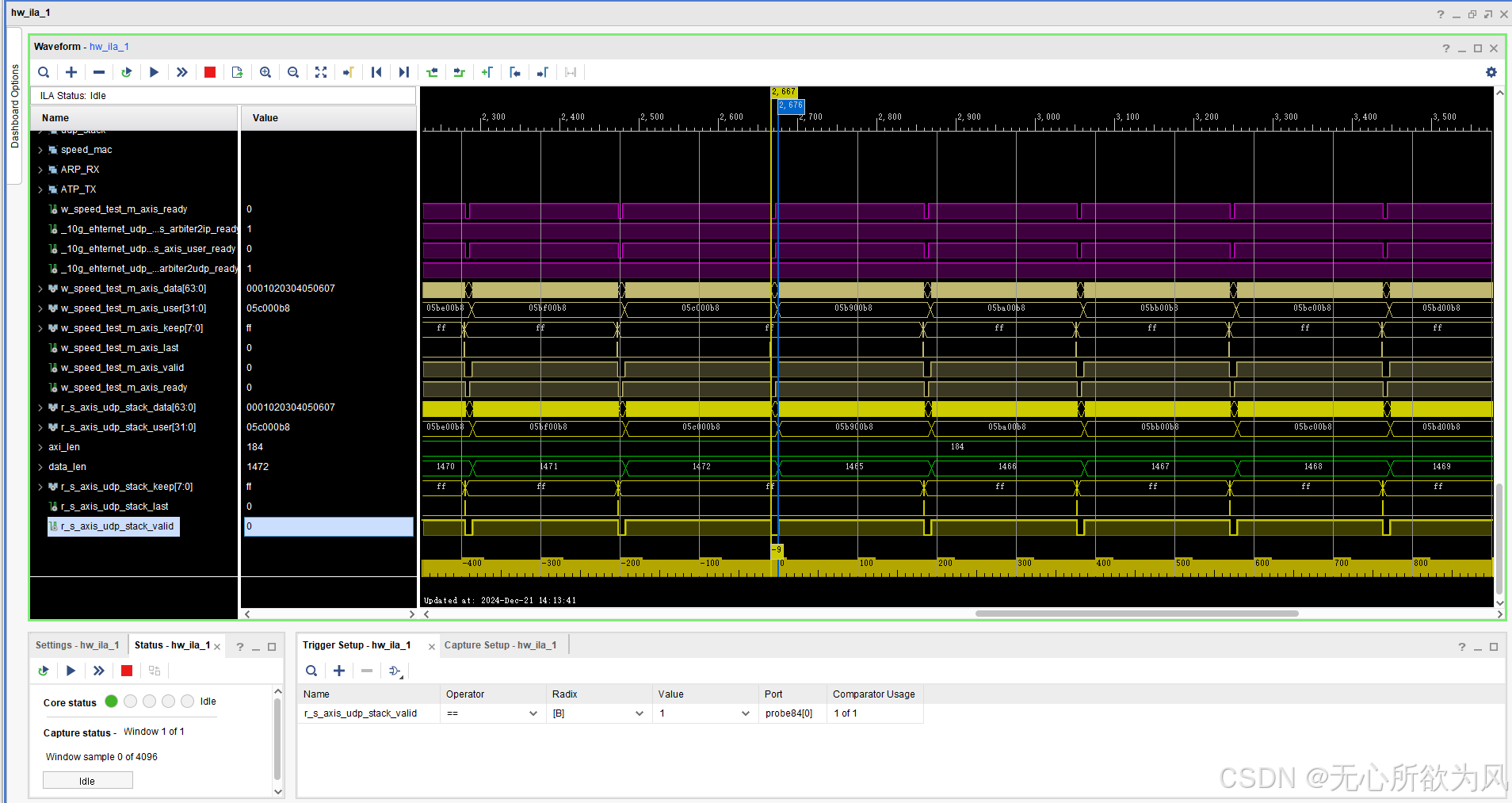
可以看到发送的数据长度(data_len)在一直改变,从1464->1472。
此时的网卡速率为9.6Gbps.
2.2,last_keep == ff
速率任然为9.6Gbps,打拍与仲裁模块应该还需改进。
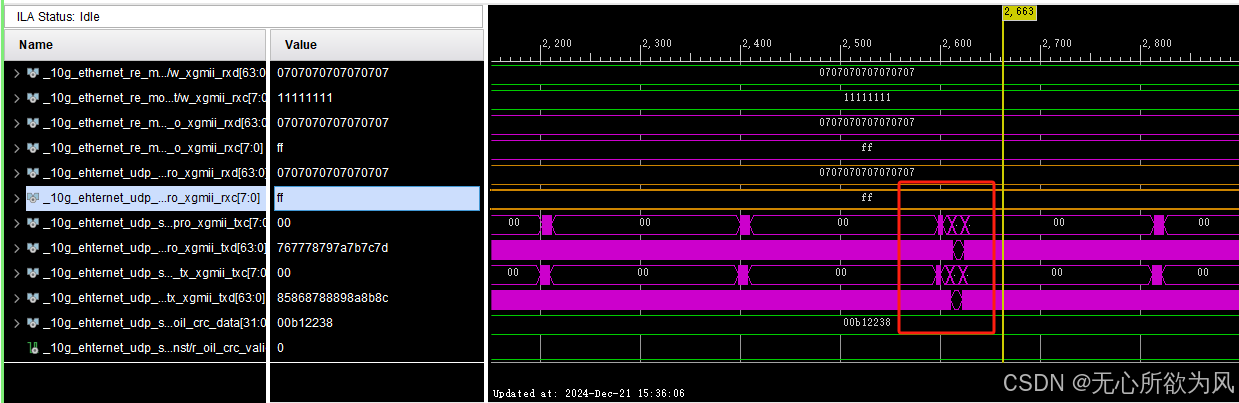
ila抓取波形:
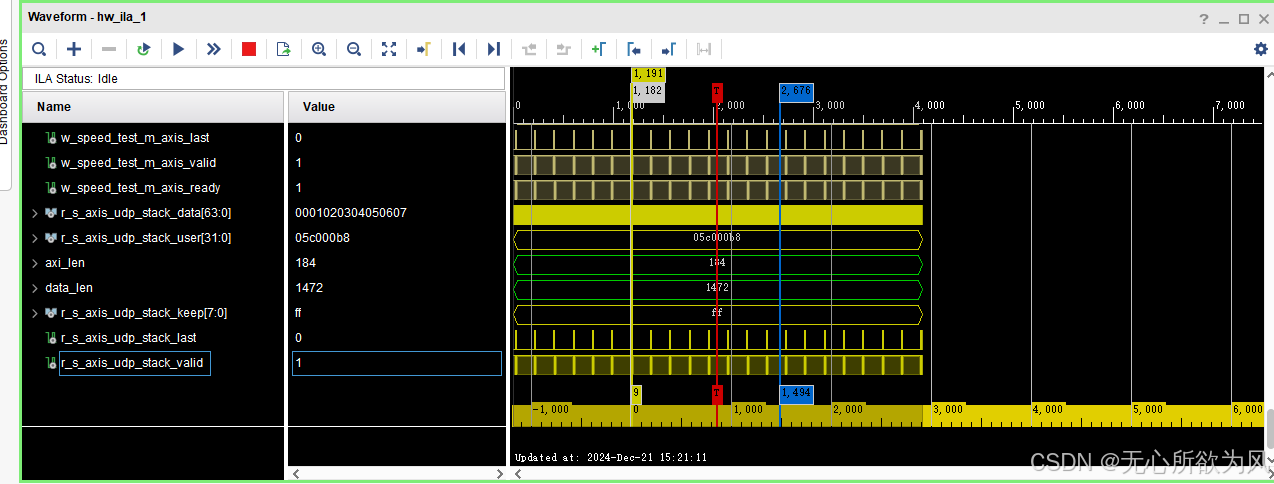
可以看到数据产生间隔为9(理想的间隔为2,因为以太网协议的最小数据间隔为12个byte,我们使用万兆以太网传输,用户时钟为156.25Mhz,6.4ns。每个周期传递8byte数据,平均8ns一个数据,所以万兆以太网的最小间隔理想为9.6ns。但是时钟周期只能取到整数,所以万兆以太网最小周期间隔为2,就可达到10Gbps):
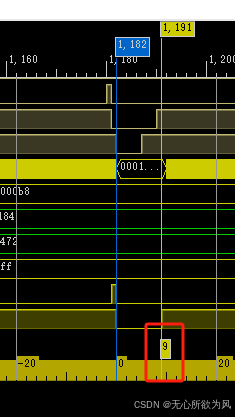
在高速传输中,任然能够实现ICMP功能:
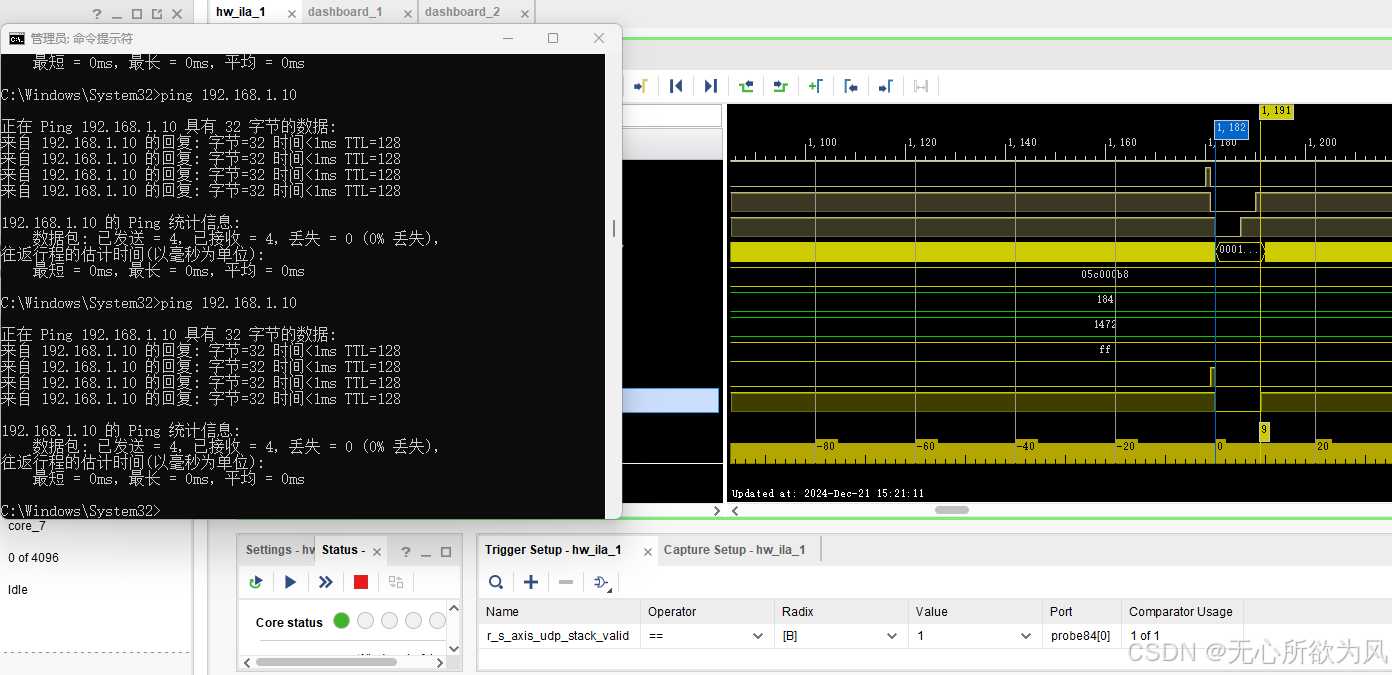
其中1为pc的icmp请求,2为FPGA板卡的icmp回应。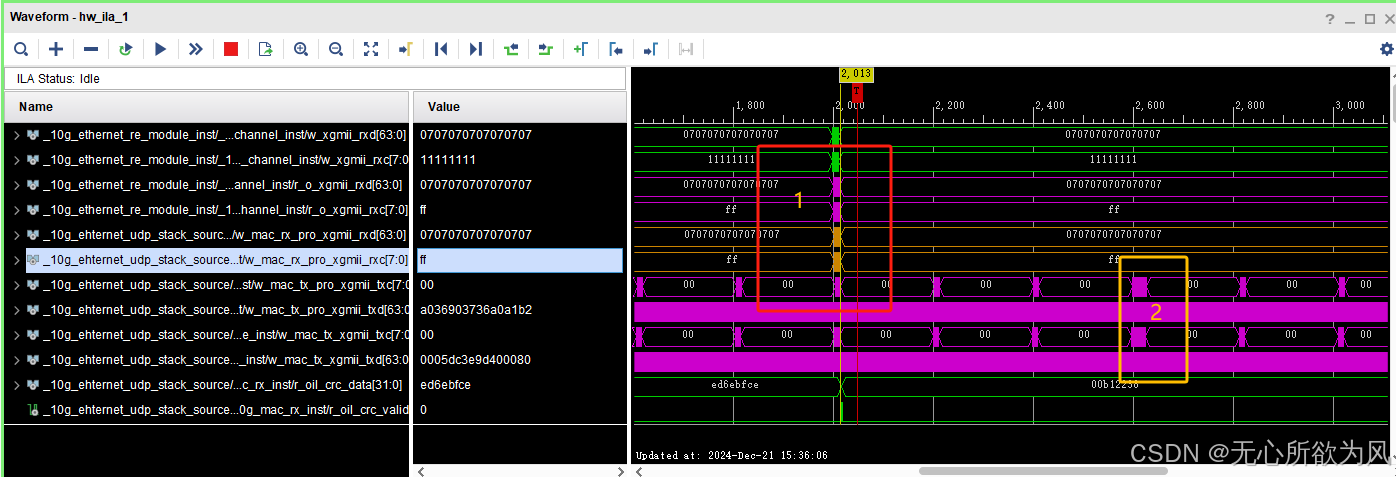
与我另一篇文章的10G_ethernet学习记录(2): MAC层编写中相比,我添加了arbiter模块,并对多个ready信号进行了与操作(防止数据冲突),这可能是降低速率的原因。
注意:我在10G_ethernet学习记录(2): MAC层编写中的MAC测试的是为按照以太网格式的数据,wireshark只会接受,不会进行解析。而我们现在是按照正统格式发送的udp报文,会是wireshark进行工作,导致数据激增(接近10Gbps),会导致电脑卡死。所以速度测试时一定要关掉wireshark,以及其他的任何网络端口连接,不然会卡死,亲身经历!!!
3,the_last
从万兆以太网的ip开始,到最后上板回环与测试实现。实属是一个漫长的学习过程。 本想着将这个项目放入秋招简历中,但总拖着。直到秋招四处碰壁,才慢慢动起来关于高速接口相关的内容,并将其用博客记录下来(看到好多大佬都有展示自己部分,我就决定将学习过程记录下来放在博客上,也放在了建立上),完成了万兆以太网这个项目的板上实现。果然压力才是推动人前进的动力。
但是这个项目任然有些尚未完成的部分:
- 最大速度卡在了9.6Gbps,需要接近9.8Gbps,9.9Gbps才比较稳妥,所以有些模块需要进行改进;
- UDP层中的巨帧操作,只需要对UDP的udp_rx,udp_tx进行改进,以及IP首部的mf,offset,这些都在ip模块,udp模块的user中进行了预留,应该可以进行的比较快。
接下来的目标是pcie,利用pcie与万兆以太网合并开发一个高速接口的项目放在简历上,备战春招!!!

















 5314
5314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









