






今天分享下deepseek +本地知识库的部署。
先画个数据流程流程。
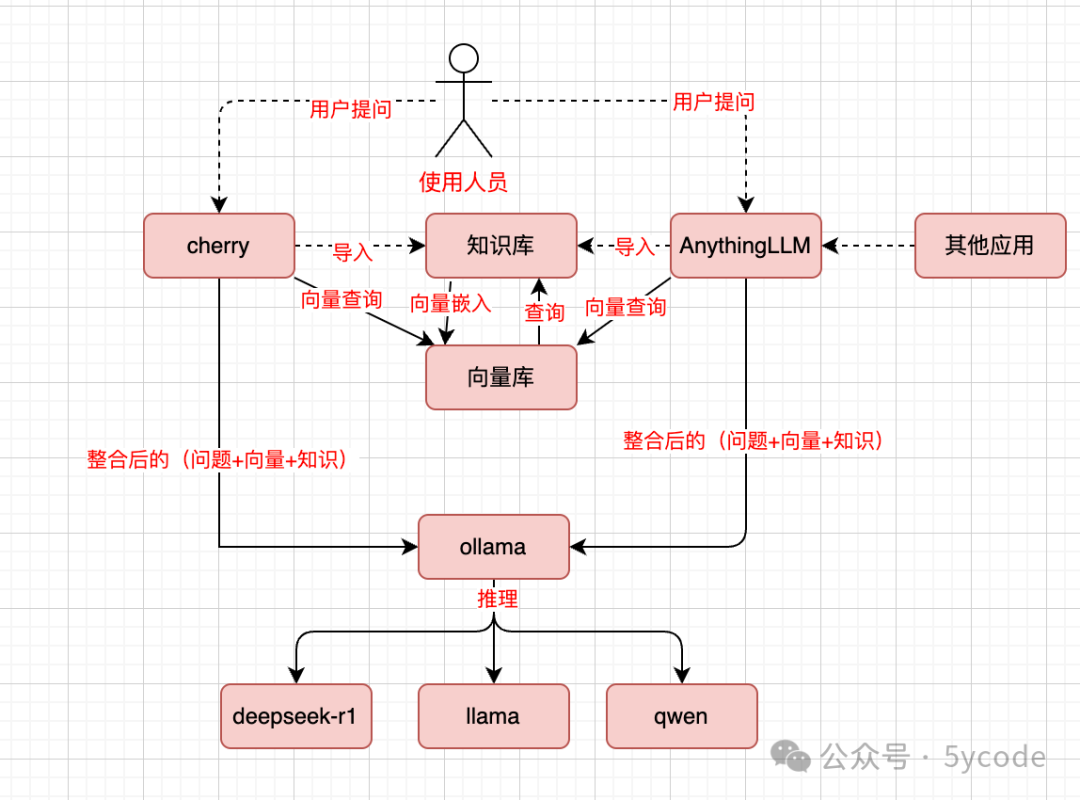
基于Cherry Studio搭建(首选)
基于本地的deepseek搭建个人知识库。 使用本地服务,安装嵌入模型,用于将文本数据转换为向量标识的模型。
#命令行窗口执行拉取下即可。
ollama pull bge-m3
pulling manifest
pulling daec91ffb5dd... 100% ▕████████████████████████████████████████████████████████▏ 1.2 GB
pulling a406579cd136... 100% ▕████████████████████████████████████████████████████████▏ 1.1 KB
pulling 0c4c9c2a325f... 100% ▕████████████████████████████████████████████████████████▏ 337 B
verifying sha256 digest
writing manifest
success
下载cherry studio
根据自己的环境下载cherry studio
安装的时候,注意安装到其他磁盘,不要在c盘安装。
本地模型知识库
配置本地ollama
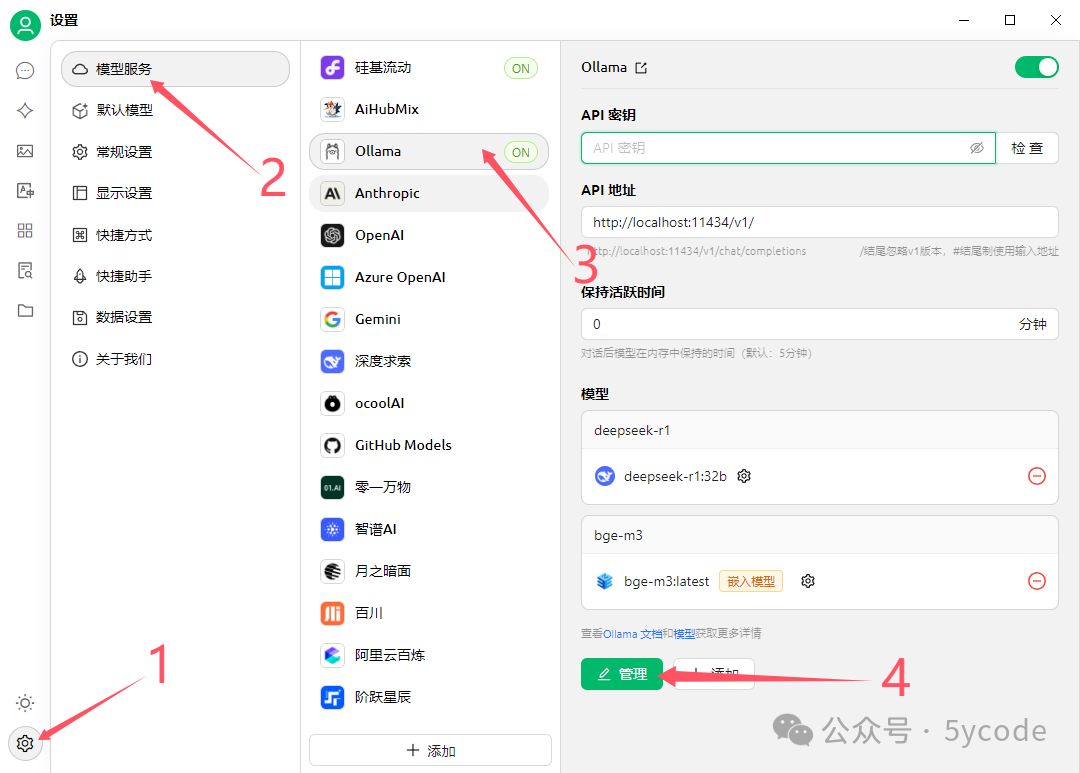
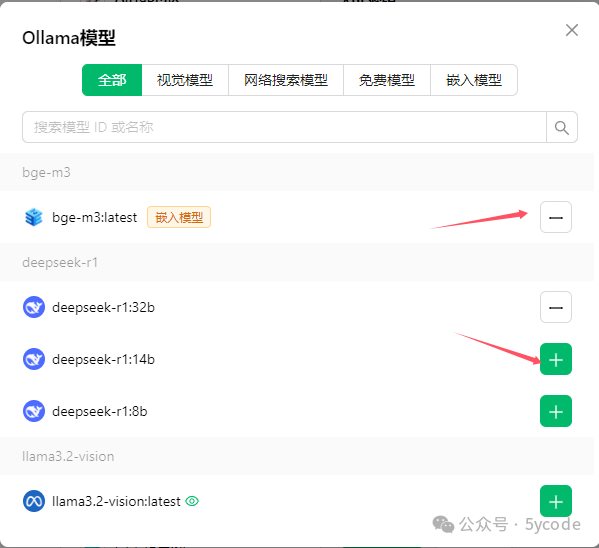
操作步骤:
-
找到左下角设置图标
-
选择模型服务
-
选择ollama
-
点击管理
-
点击模型后面的加号(会自动查找到本地安装的模型)
-
减号表示已经选择了
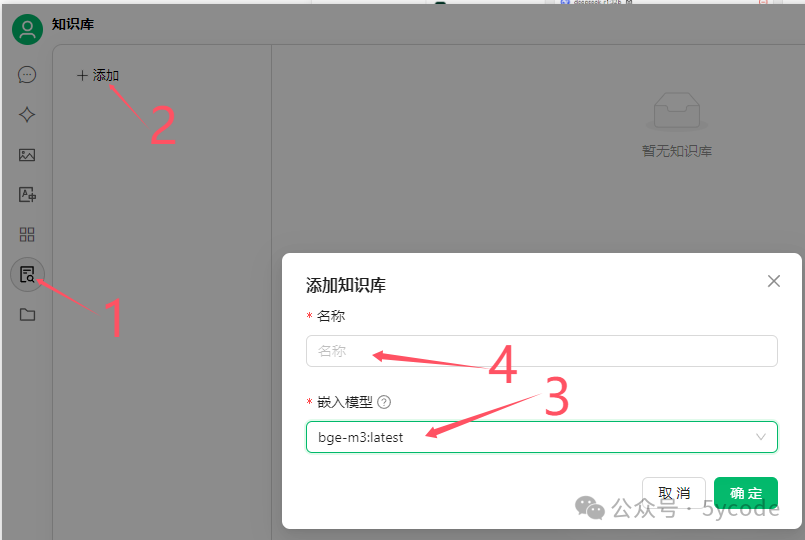
知识库配置
-
选择知识库
-
选择添加
-
选择嵌入模型
-
填写知识库名称
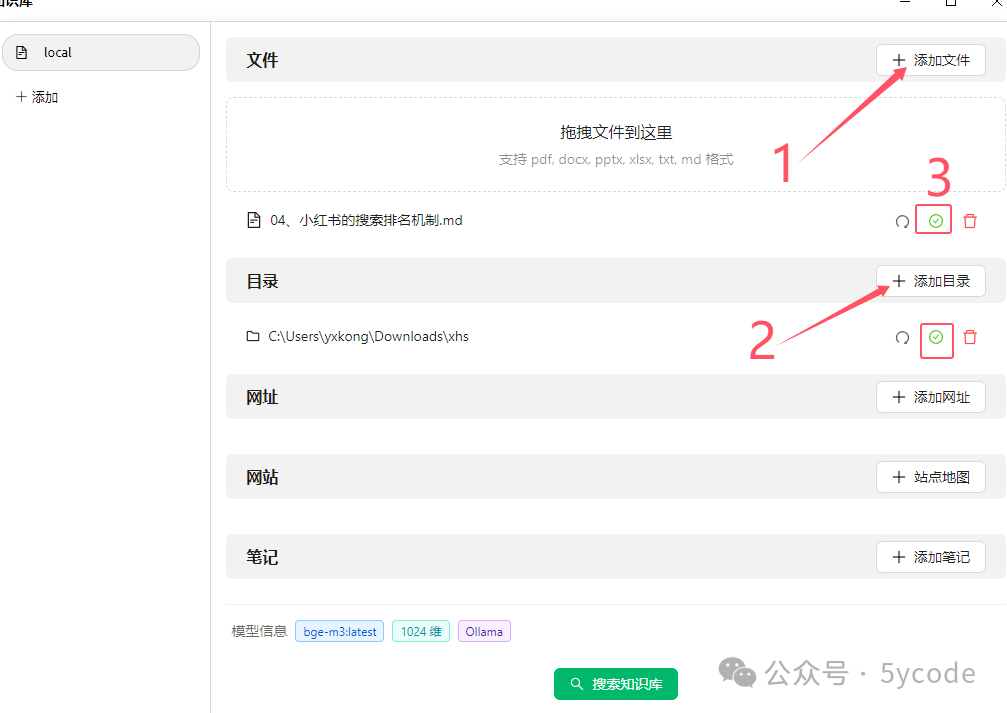
添加知识文档
cherry可以添加文档,也可以添加目录(这个极其方便),添加完以后出现绿色的对号,表示向量化完成。
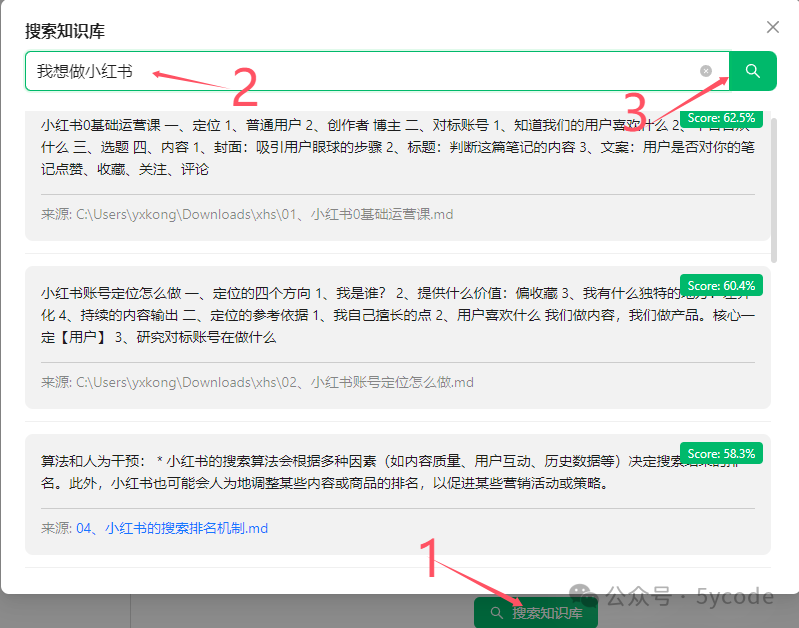
搜索验证
-
点击搜索知识库
-
输入搜索顺序
-
点击搜索 大家可以看下我搜索的内容和并没有完全匹配,不过已经和意境关联上了。
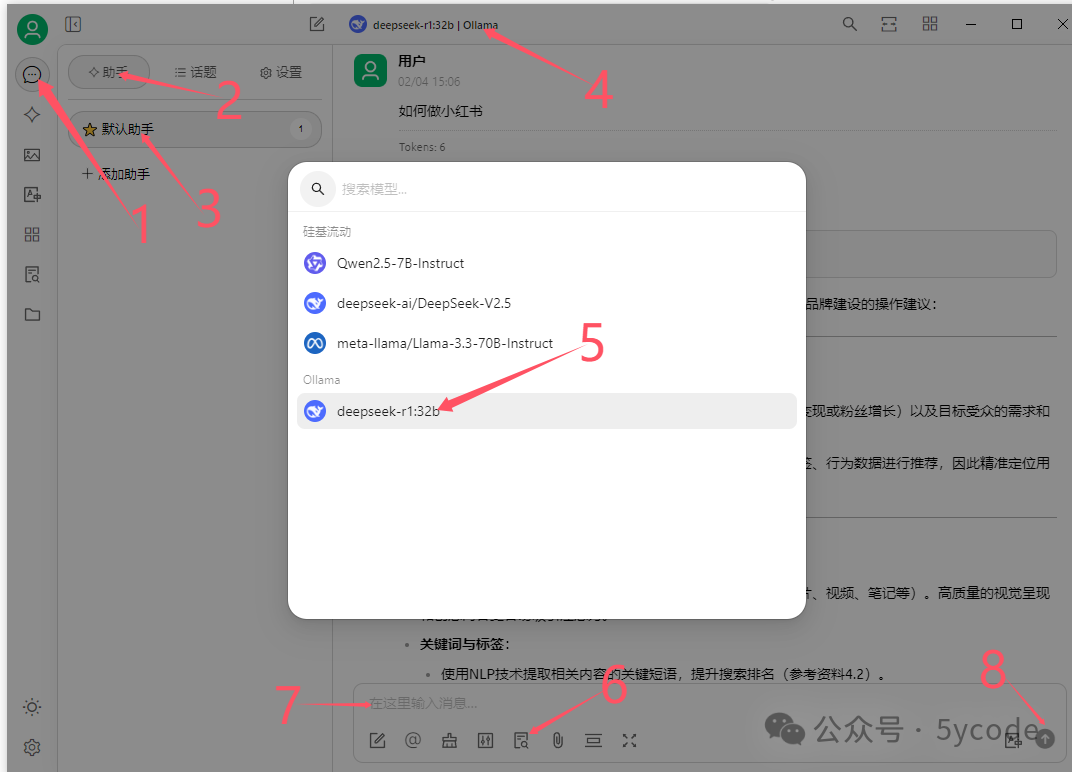
大模型处理
-
点击左上角的聊天图标
-
点击助手
-
点击默认助手(你也可以添加助手)
-
选择大模型
-
选择本地deepseek,也可以选择自己已经开通的在线服务
-
设置知识库(不设置不会参考)
-
输入提问内容
-
发问
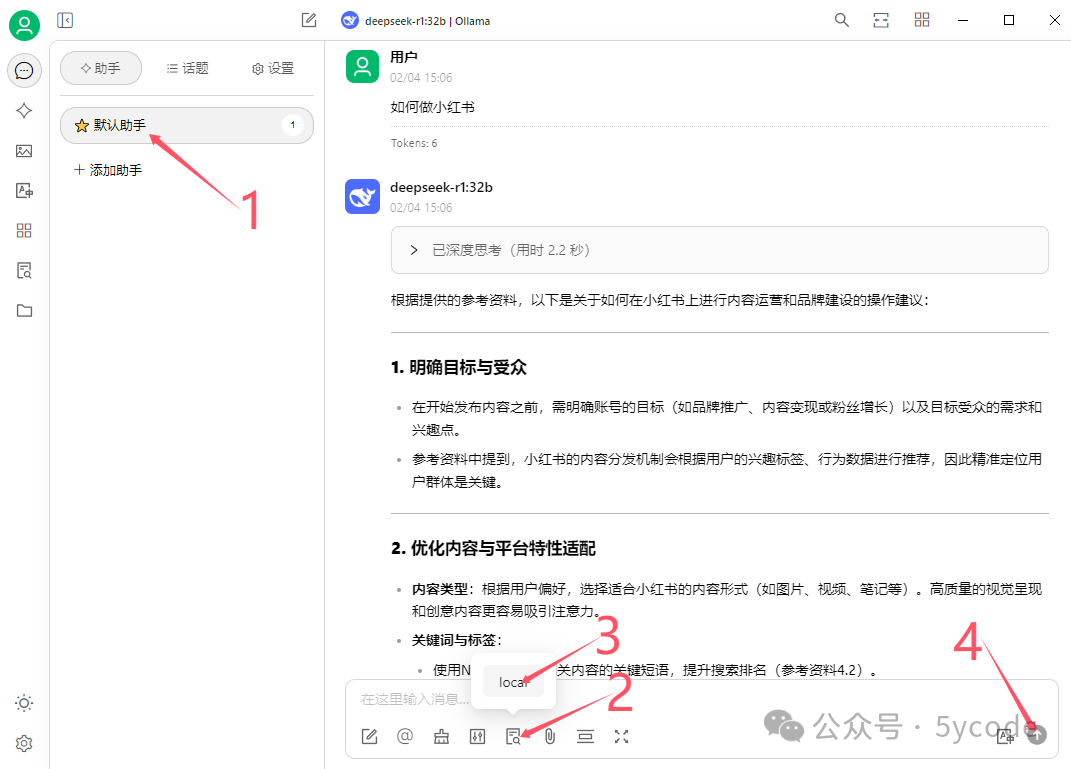
大家可以看到deepseek已经把结果整理了,并告诉了我们参考了哪些资料。
满血版
差别就是大模型的选择,在模型服务里配置下在线的deepseek服务即可。
如果你的知识库有隐私数据,不要联网!不要联网!不要联网!
方案二 基于AnythingLLM搭建
下载AnythingLLM Desktop
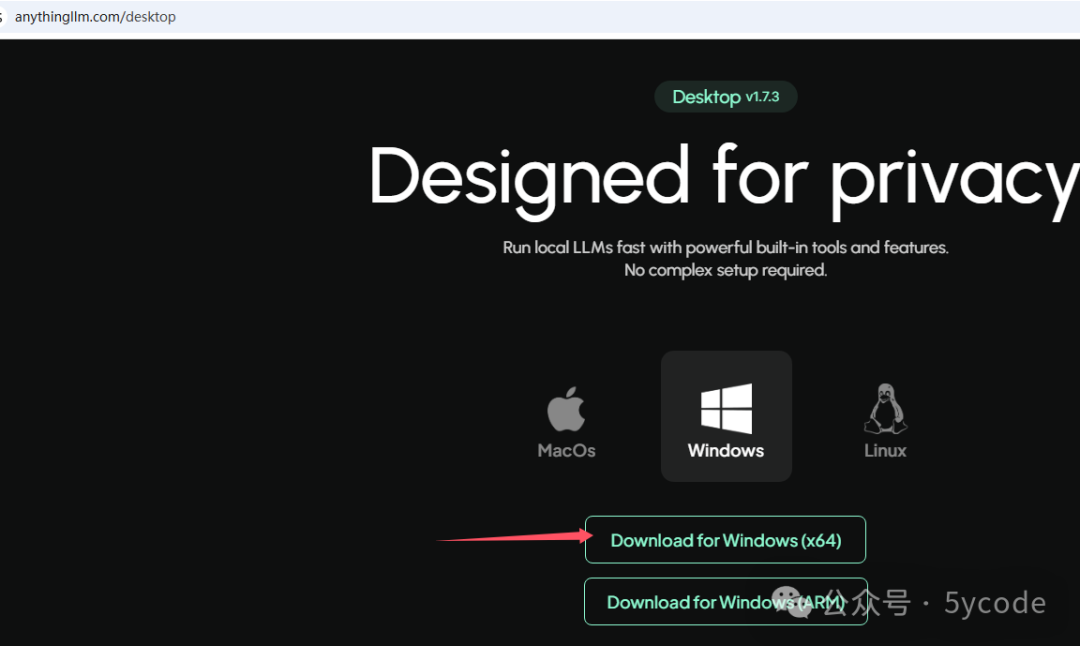
下载以后,安装的时候,注意安装到其他磁盘,不要在c盘安装。
AnythingLLM 配置
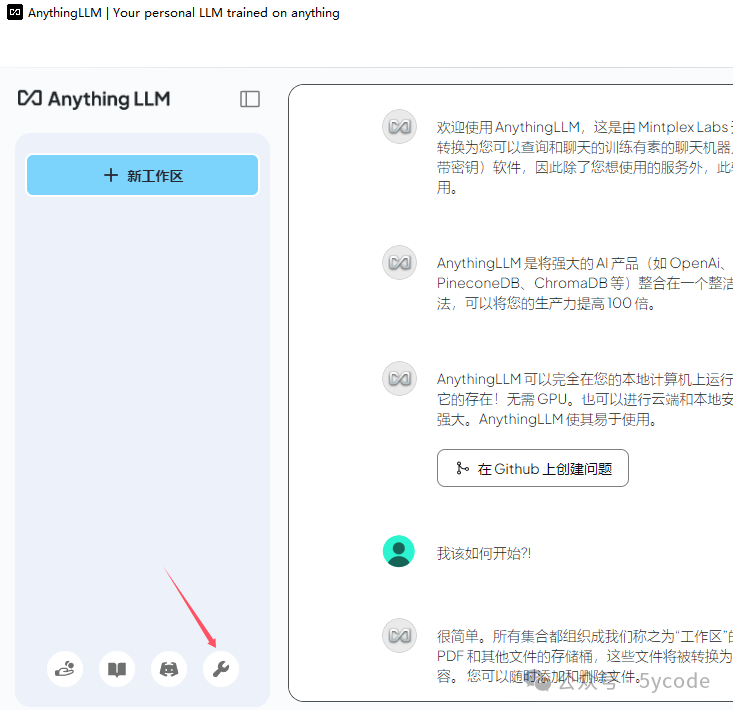
点击左下角的设置
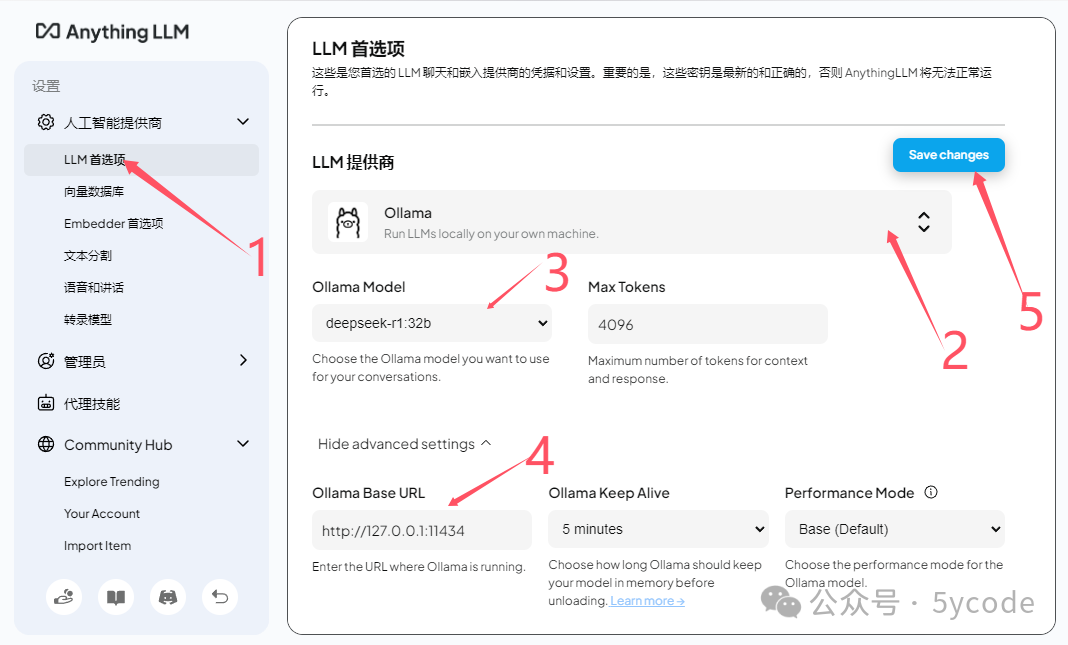
1. 点击 LLM首选项
2. 选择ollama作为模型提供商
3. 选择已安装的deepsek 模型
4. 注意下地址
5. 保存
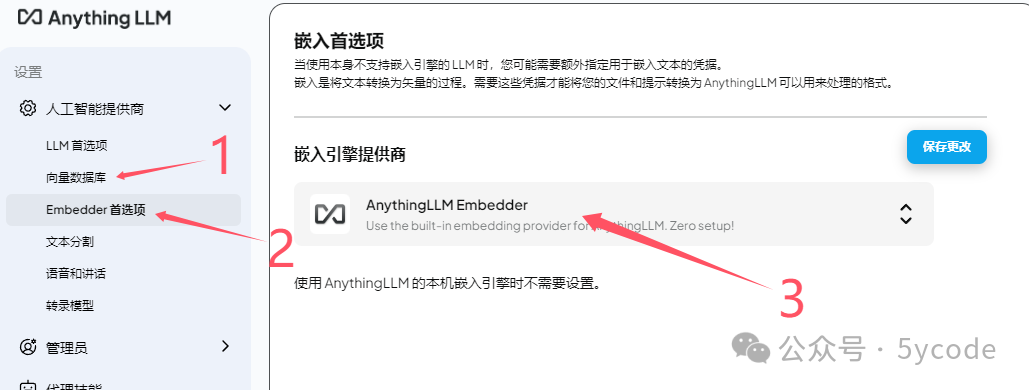
1. 向量数据库不用动即可,使用自带的(ps:如果没有选择安装目录,默认在c盘,如果后续有需要可以挪走)
2. 嵌入模型配置
3. 可以使用自带的,也可以使用ollama安装好的
4. 配置完点击左下角的返回即可
配置工作区
-
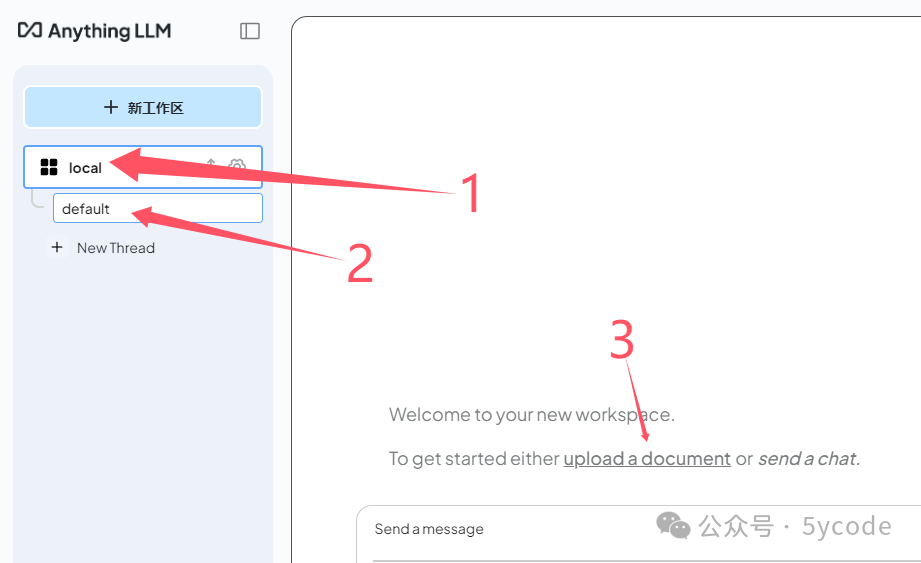
新建的工作区
-
默认会话
-
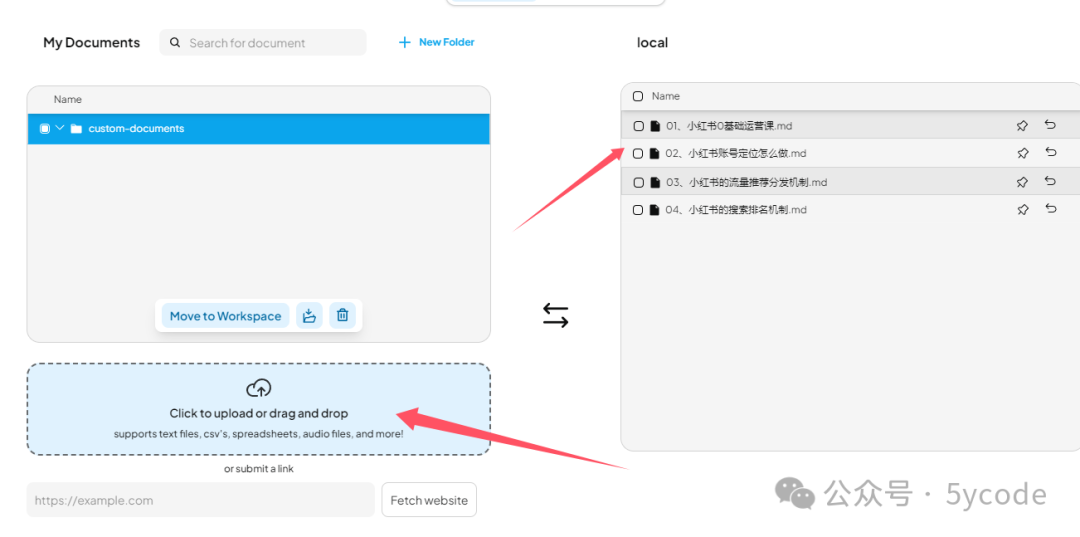
上传知识库文档
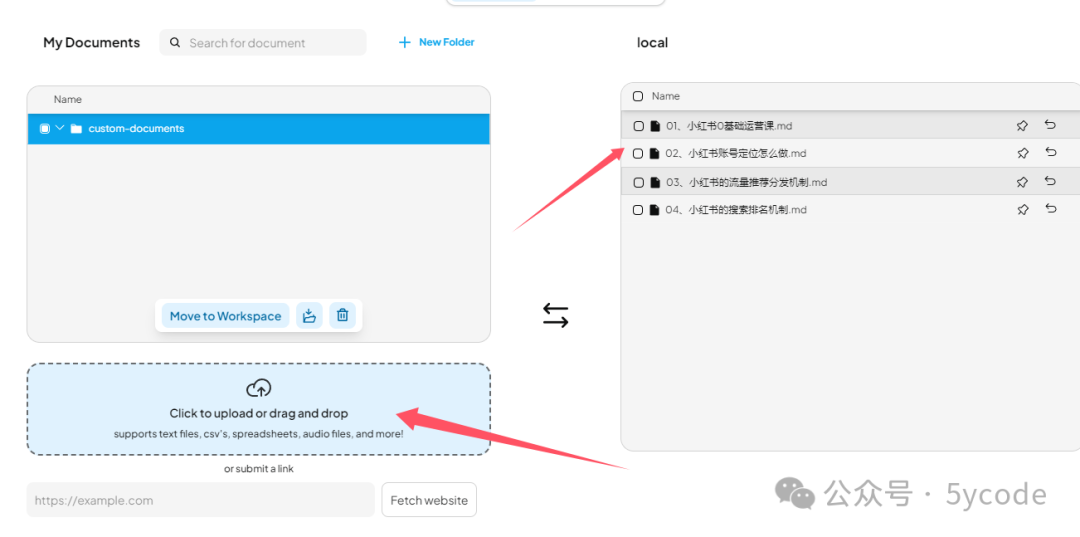
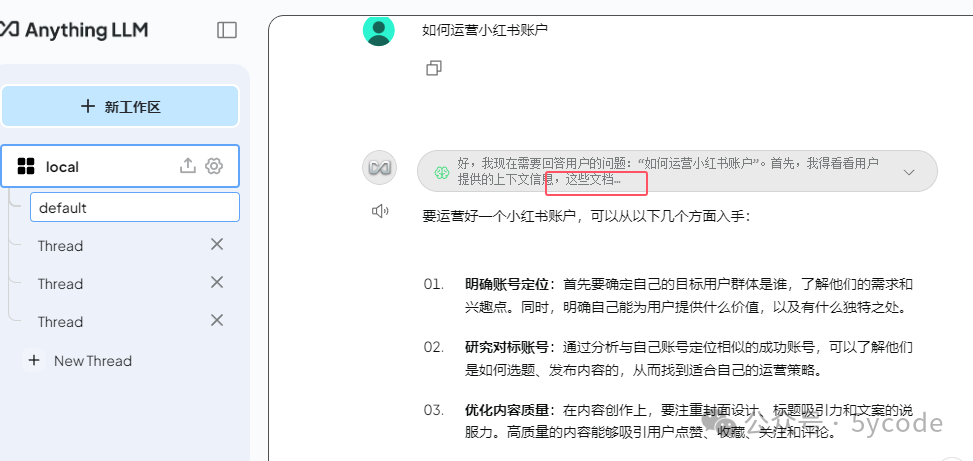
将文档拖拽到上传框。ps: 只需要拖拽一次就行了,它在聊天框能看到。不知道为什么,我这拖拽以后,没看到上传成功,然后又拖拽了几次。然后聊天框就好多份。
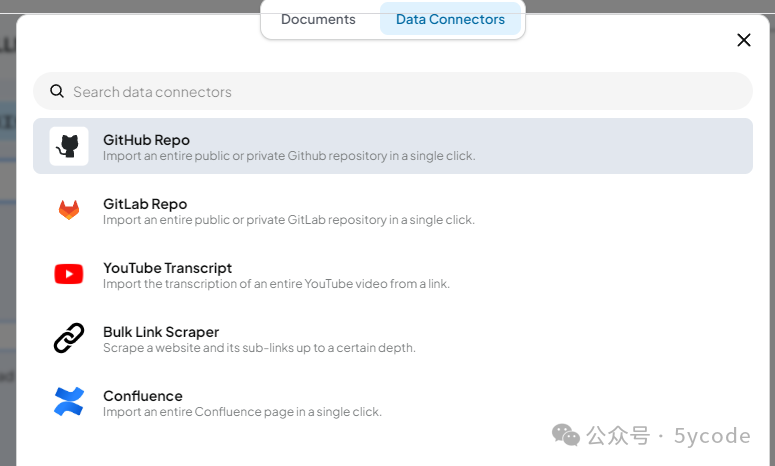
当然你可以配置远程文档,confluence、github都可以。
ps: 需要注意的是文档在工作区间内是共用的。
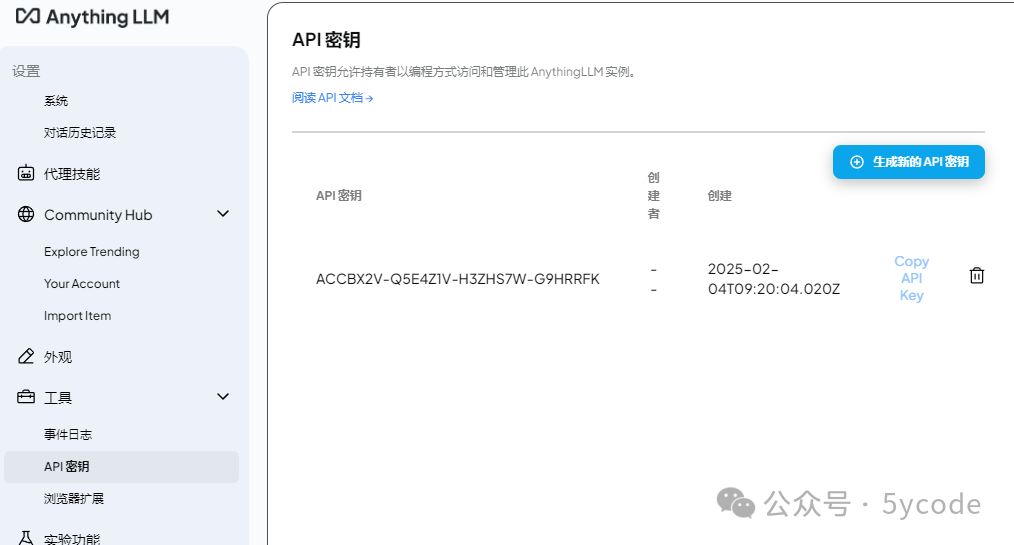
api功能
AnythingLLM 可以提供api访问的功能,这个可以作为公共知识库使用。
总结
整个操作下来,AnythingLLM 的体验没有cherry好。AnythingLLM就像一个包壳的web应用(后来查了下,确实是)。AnythingLLM 得具备一定的程序思维,给技术人员用的。非技术人员还是使用cherry吧。作为喜欢折腾的开发人员,我们可以结合dify使用。
最后
个人知识库+本地大模型的优点
-
隐私性很好,不用担心自己的资料外泄、离线可用
-
在工作和学习过程中对自己整理的文档,能快速找到,并自动关联
-
在代码开发上,能参考你的开发习惯,快速生成代码

















 335
335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









