







论文链接:ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
出处:ECCV 2018 | 旷世 清华
1.摘要
目前衡量模型复杂度的一个通用指标是FLOPs,具体指的是multiply-add数量,但是这却是一个间接指标,只是一个估计的指标,因为它不完全等同于速度或延迟(这是我们直接观察的指标),速度还取决于其他的因素,例如存储器存取成本(memory access cost)和平台特性(platform characterics)。所以本文就提出了我们应该使用更直接的效率度量方法(如速度和延迟)。
2.引言
目前大部分的模型加速和压缩文章在对比加速效果时用的指标都是FLOPs(float-point operations),这个指标主要衡量的就是卷积层的乘法操作。但是这篇文章通过一系列的实验发现FLOPs并不能完全衡量模型速度,如下图所示:具有相同的FLOPs却有不同的速度,因此,使用FLOPs作为计算复杂度的唯一指标是不够的,可能会导致次优化设计。
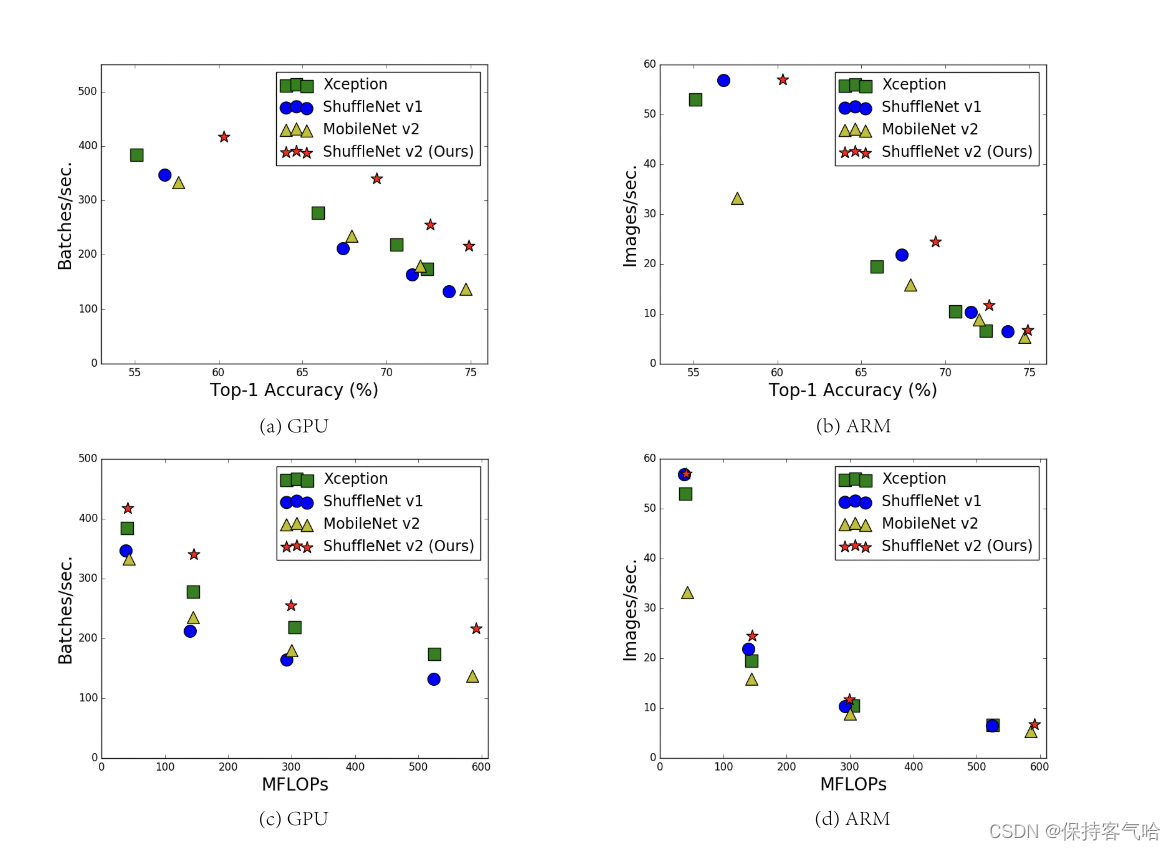
FLOPs 和 speed 之间的不对等可能有以下两个原因:
- 首先影响速度的不仅仅是FLOPs,如
内存使用量(memory access cost, MAC),这不能忽略,对于GPU来说可能会是瓶颈。另外模型的并行程度也影响速度,并行度高的模型速度相对更快 - 模型在不同平台上的运行速度是有差异的,如GPU和ARM,而且采用不同的库也会有影响

如上图所示,我们注意到FLOPs度量只考虑了卷积部分。虽然这一部分消耗的时间最多,但其他操作包括data I/O、data shuffle和element-wise operations(AddTensor、ReLU等)也占用了相当多的时间。因此,FLOPs并不是对实际运行时的足够准确的估计。
据此,作者在特定的平台下研究ShuffleNetv1和MobileNetv2的运行时间,并结合理论与实验得到了4条实用的指导原则
3. ShuffleNet四条实用指南
3.1 G1:Equal channel width minimizes memory access cost (MAC)
当卷积层的输入特征矩阵与输出特征矩阵channel相等时MAC最小(保持FLOPs不变时)
对于轻量级CNN网络,常采用深度可分割卷积(depthwise separable convolutions),其中点卷积( pointwise convolution)即1x1卷积复杂度最大。这里假定输入和输出特征的通道数分别为
c
1
c_1
c1 和
c
2
c_2
c2,特征图的空间大小为
h
×
w
h×w
h×w ,那么1x1卷积的
F
L
O
P
s
B
=
h
w
c
1
c
2
FLOPs B=hwc1c2
FLOPsB=hwc1c2,对应的MAC为
h
w
(
c
1
+
c
2
)
+
c
1
c
2
hw(c_1+c_2)+c_1c_2
hw(c1+c2)+c1c2(这里假定内存足够),根据均值不等式,固定 B 时,MAC存在下限(令
c
2
=
B
/
h
w
c
1
c2=B/hwc1
c2=B/hwc1):
M
A
C
≥
2
h
w
c
1
c
2
+
c
1
c
2
MAC \geq 2hw\sqrt{c_1c_2}+c_1c_2
MAC≥2hwc1c2+c1c2
≥
2
h
w
B
+
B
h
w
\quad \quad \geq \sqrt{2hwB}+\frac{B}{hw}
≥2hwB+hwB
因此就有了下面的这个实验,这些实验的网络是由10个block组成,每个block包含2个1*1卷积层,第一个卷积层的输入输出通道分别是c1和c2,第二个卷积层相反。4行结果分别表示不同的c1:c2比例,但是每种比例的FLOPs都是相同的,可以看出在c1和c2比例越接近时,速度越快,尤其是在c1:c2比例为1:1时速度最快。这和前面介绍的c1和c2相等时MAC达到最小值相对应。

3.2 G2: Excessive group convolution increases MAC
当 GConv 的 groups 增大时(保持FLOPs不变时),MAC 也会增大,所以建议针对不同的硬件和需求,更好的设计对应的分组数,而非盲目的增加,论文中给出的公式证明如下:
B
=
h
w
c
1
c
2
/
g
\color{red}{B=hwc_1c_2/g}
B=hwc1c2/g (其中每个卷积核都只和
c
1
/
g
c_1/g
c1/g个通道的输入特征做卷积,所以多个一个除数g。
M
A
C
=
h
w
(
c
1
+
c
2
)
+
c
1
c
2
/
g
=
h
w
c
1
+
B
g
/
c
1
+
B
/
h
w
\color{red}{MAC = hw(c_1+c_2)+c_1c_2/g = hwc_1+Bg/c_1+B/hw}
MAC=hw(c1+c2)+c1c2/g=hwc1+Bg/c1+B/hw(B不变时,g越大,MAC也越大)
下图是实验情况,可以看出使用大量的组数会显著降低运行速度。例如,在GPU上使用8group比使用1group(标准密集卷积)慢四倍以上(x1情况下),在ARM上慢30%。这主要是由于MAC的增加。所以使用比较大组去进行组卷积是不明智的。对速度会造成比较大的影响。

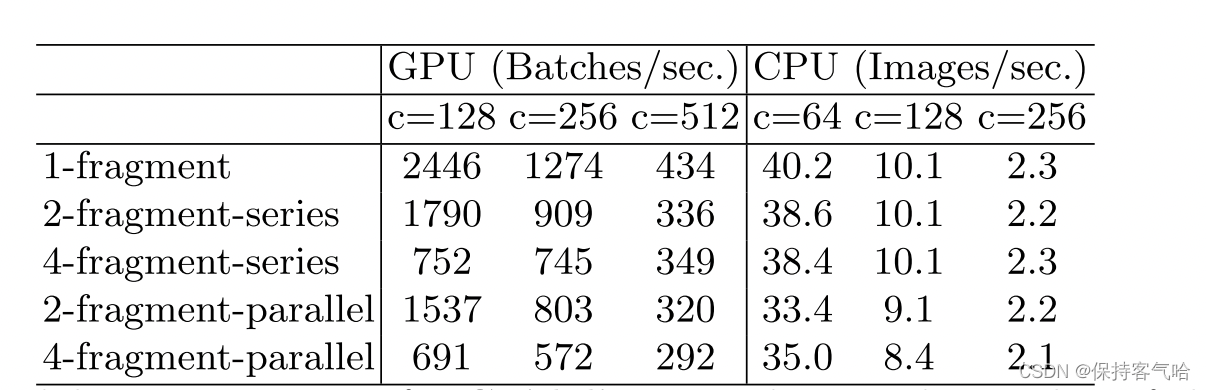
3.2 G3: Network fragmentation reduces degree of parallelism
网络设计的碎片化程度(或者说并行的分支数量)越高,速度越慢。如下图的实验:其中2-fragment-series表示一个block中有2个卷积层串行,也就是简单的叠加;4-fragment-parallel表示一个block中有4个卷积层并行,类似Inception的整体设计。可以看出在相同FLOPs的情况下,单卷积层(1-fragment)的速度最快。因此模型支路越多(fragment程度越高)对于并行计算越不利,这样带来的影响就是模型速度变慢,比如Inception、NASNET-A这样的网络。
3.4 G4: Element-wise operations are non-negligible
Element-wise操作,即逐点运算,带来的影响是不可忽视的,轻量级模型中,元素操作占用了相当多的时间,特别是在GPU上。这里的元素操作符包括 ReLU、AddTensor、AddBias 等。将 Depthwise Convolution 作为一个 element-wise operator,因为它的 MAC/FLOPs 比率也很高。作者对ShuffleNet v1和MobileNet v2的几种层操作的时间消耗做了分析,常用的FLOPs指标其实主要表示的是卷积层的操作,而element-wise操作虽然基本上不增加FLOPs,但是所带来的时间消耗占比却不可忽视。如下图所示:

Table4的实验,Table4的实验是基于ResNet的bottleneck进行的,short-cut其实表示的就是element-wise操作。这里作者也将Depthwise Convolution归为element-wise操作,因为Depthwise Convolution也具有低FLOPs、高MAC的特点。移除ReLU和shortcut后,GPU和ARM都获得了大约20%的加速。这里主要突出的是,这些操作会比我们想象当中的要耗时

4.ShuffleNetV2网络结构
由上面的四条实用指南我们得出结论,设计一个高效的网络应该:
- 使用输入输出通道相同的卷积
- 了解使用分组卷积的代价,合理的设定分组格式
- 降低网络并行的分支
- 减少逐点运算
在之前的 S h u f f l e N e t V 1 的设计中: \color{black}{在之前的ShuffleNet V1的设计中:} 在之前的ShuffleNetV1的设计中:
- Pointwise 分组卷积和 bottleneck 结构会提升 MAC(G1 和 G2),其计算消耗是不可忽略的,尤其是小模型。
- 使用大的分组数会不符合 G3
- 残差连接中的逐点相加操作也会带来大量计算,不符合 G4
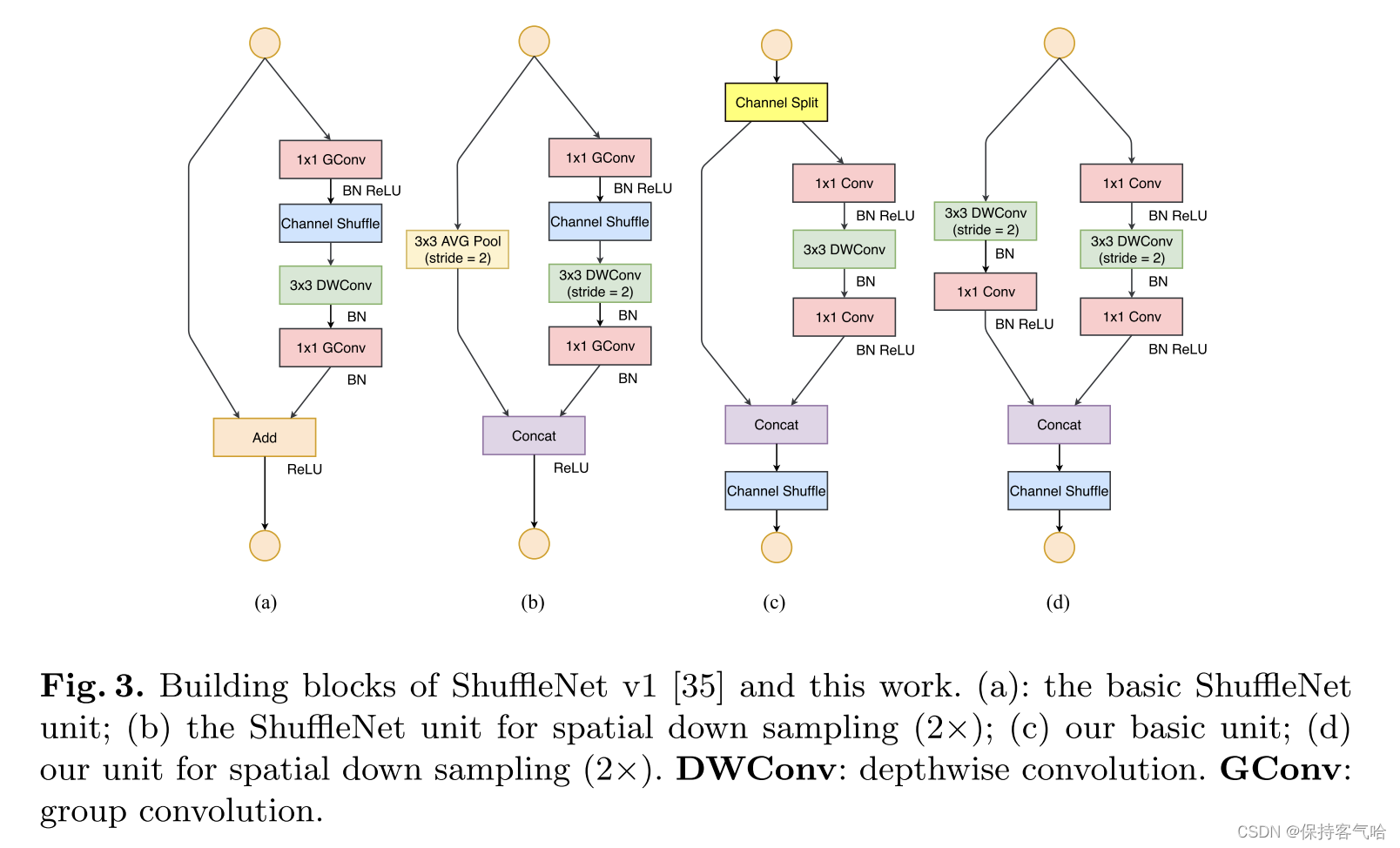
为了改善v1的缺陷,v2版本引入了一种新的运算:channel split。
- 在开始时先将输入特征图在通道维度分成两个分支:左边分支做同等映射,右边的分支包含3个连续的卷积,并且输入和输出通道相同,这符合G1。
- 两个1x1卷积不再是组卷积,因为分成两个分支,原理上已经进行了分组,这符合G2
- 另外两个分支相当于已经分成两组。两个分支的输出不再是Add元素,而是concat在一起,紧接着是对两个分支concat结果进行channle shuffle,以保证两个分支信息交流。其实concat和channel shuffle可以和下一个模块单元的channel split合成一个元素级运算,这符合原则G4。
- 对于下采样模块,不再有channel split,而是每个分支都是直接copy一份输入,每个分支都有stride=2的下采样,最后concat在一起后,特征图空间大小减半,但是通道数翻倍。
ShuffleNetV2 不仅仅高效,而且准确性也有保证,主要有两个原因:
- 每个 block 都是高效的,这就允许网络使用更大的 channel 数量
- 每个 block 中,只使用约一半的 channel 经过本个 block 的层进行特征提取,另外一半的 channel 直接输入下一个 block,可以看做特征重用
整个 V2 的网络结构是重复的堆叠起来的,整个网络结构和 V1 也很类似,只有一个不同点,就是在 global average pooling 之前加了一个 1x1 卷积(下图的Conv5),用于特征混合,其中设定每个block的channel数,如0.5x,1x,可以调整模型的复杂度

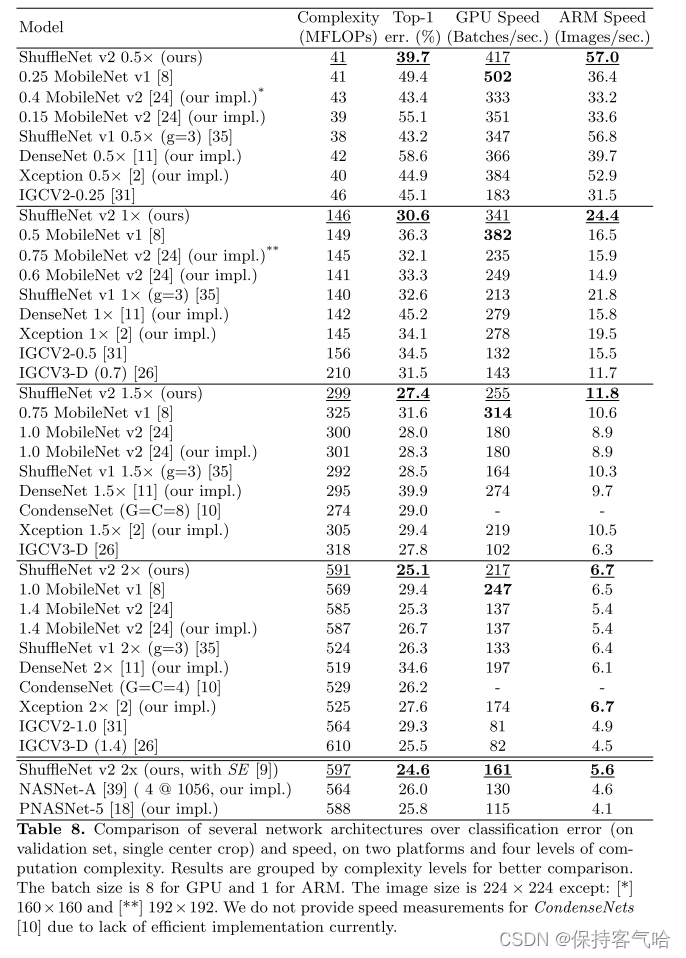
最终的模型在ImageNet上的分类效果如下图所示,可以看到,在同等条件下,ShuffleNetv2相比其他模型速度稍快,而且准确度也稍好一点。同时作者还设计了大的ShuffleNetv2网络,相比ResNet结构,其效果照样具有竞争力。从一定程度上说,ShuffleNetv2借鉴了DenseNet网络,把shortcut结构从Add换成了Concat,这实现了特征重用。但是不同于DenseNet,v2并不是密集地concat,而且concat之后有channel shuffle以混合特征,这或许是v2即快又好的一个重要原因。















 642
642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









