







大语言模型本地部署
一、本地大语言模型软件
1. Ollama
Ollama1是一个用于本地部署大语言模型的开源工具,其部署主要采用命令行的方式,通过文末的官网链接下载对应的Ollama工具,下载完成后会自动打开命令行,只需输入你想要运行的模型,便可以自动从Docker拉取,并运行模型,例如ollama run deepseek-r1:8b
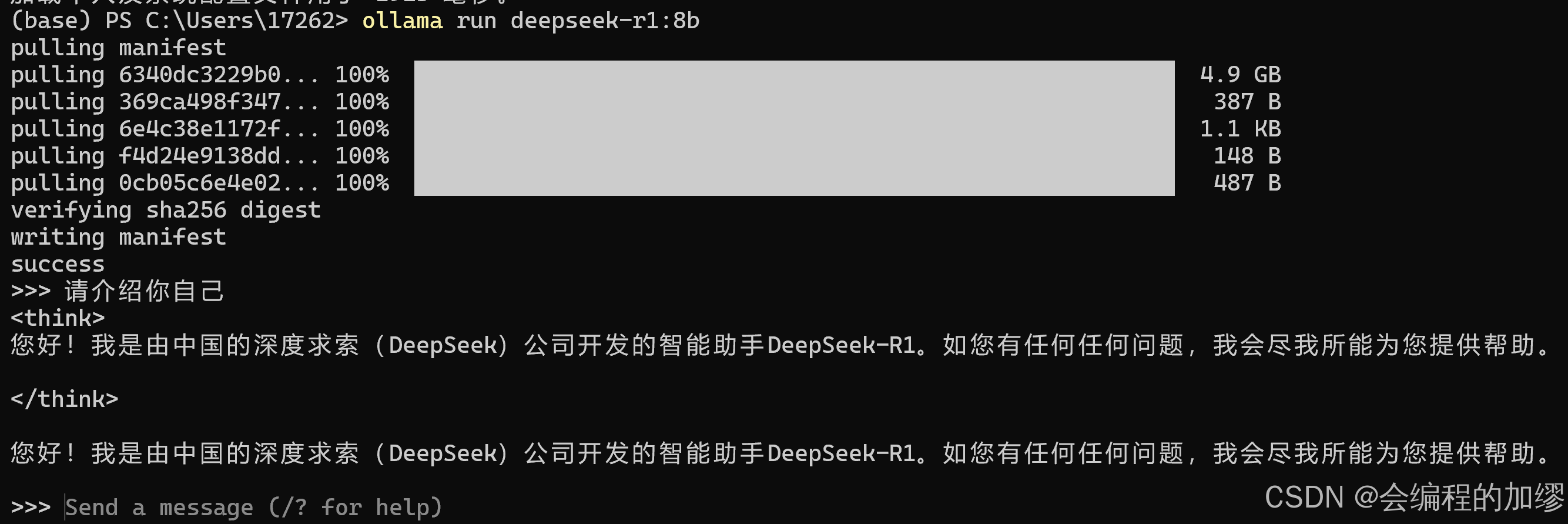
但是由于命令行界面看着没那么舒服,可以结合Anything LLM使用
2. LM Studio
LM Studio2是一款桌面应用程序,用于在计算机上本地开发和试验大语言模型(LLMs),可以直接从文末的官方链接中下载LM Studio。与Ollma相比,其最大的特点便是已经拥有较好的可视化界面,不必再通过Anything LLM来连接。主要功能包括:
- 一款用于运行本地大语言模型的桌面应用程序
- 一个熟悉的聊天界面 搜索与下载功能(通过 Hugging Face 🤗)
- 一个可以监听类似 OpenAI 端点的本地服务器
- 一个管理和配置本地模型的系统
LM Studio的使用界面如下:
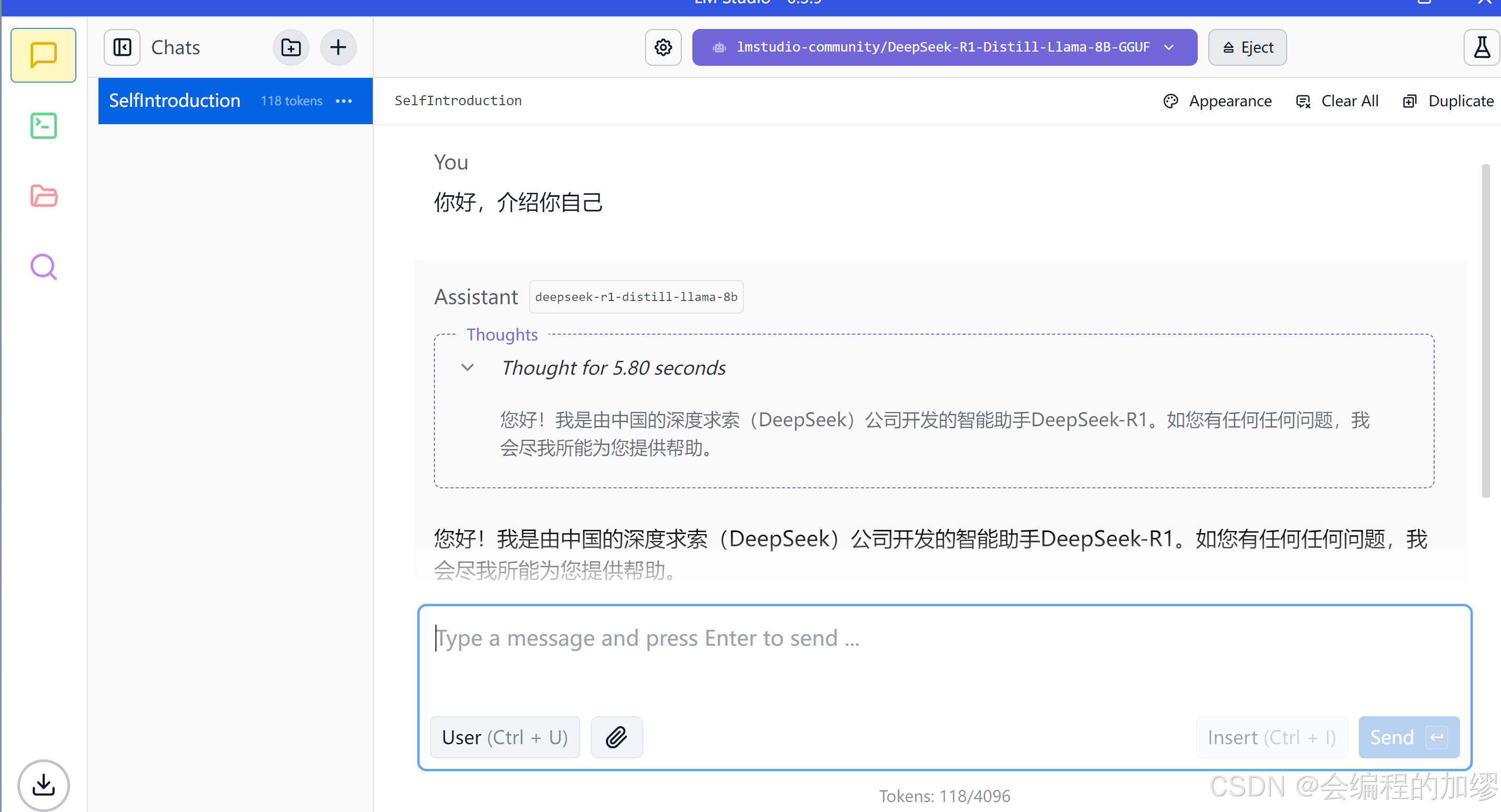
图中的演示模型采用的DeepSeek-R1-Distill-Llama-8B-GGUF,在使用过程中,可以通过左侧工具栏的搜索🔍图标来查找并下载你感兴趣的模型,在下载过程中会遇到链接打不开或者下载慢的问题,有博主提供了一些解决办法:
具体解决办法参考博客LM-Studio无法搜索以及下载失败的问题对策,
由于更改之后下载速度还是很慢,我选择的方法是通过梯子直接到hugging face下载对应的GGUF文件,例如,下载guangy10/Llama-3.2-1B-Q4_K_M-GGUF,一定要下载.gguf结尾的文件

下载好之后,从lm studio左侧的工具栏可以打开lm studio的模型文件夹
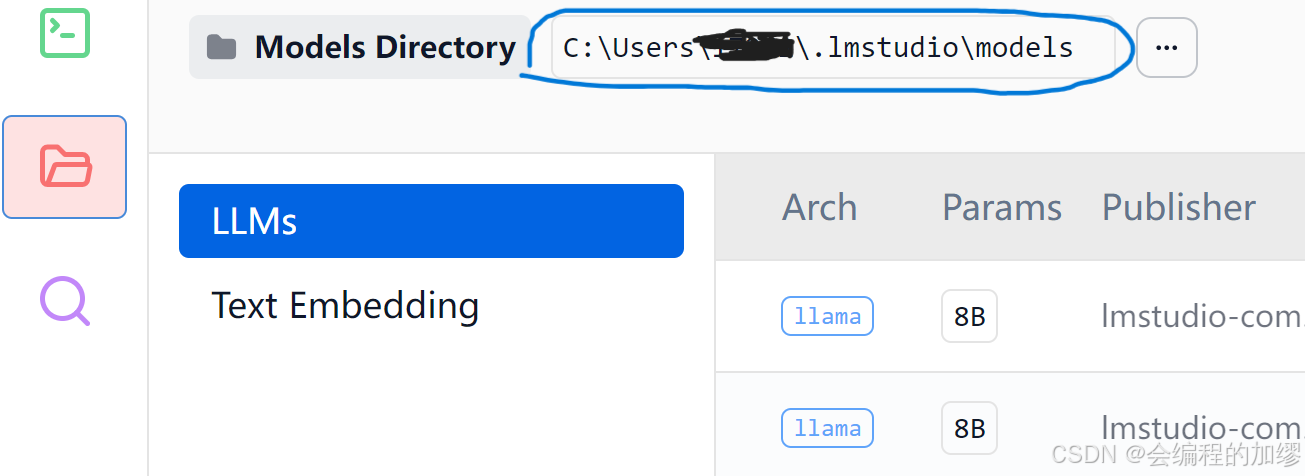
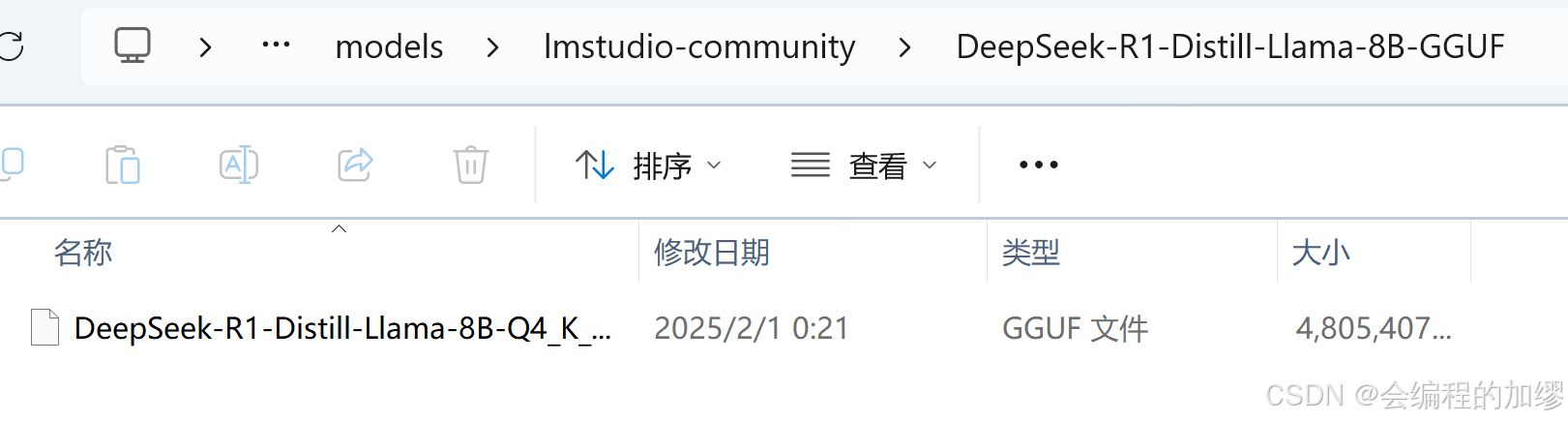
最后,将模型文件放到该文件夹下面,便可以加载该模型了。注意文件路径还需要设置新的文件夹名字——lmstudio-community/DeepSeek-R1-Distill-Llama-8B-GGUF
C:\Users\xxxx\.lmstudio\models\lmstudio-community\DeepSeek-R1-Distill-Llama-8B-GGUF
二、本地大模型部署平台——Anything LLM
Anything LLM不仅可以调用本地的模型,还可以通过API接口调用网页模型,具体操作可以参考博客AnythingLLM:基于RAG方案构专属私有知识库(开源|高效|可定制), 本文主要介绍的是Anything LLM与Ollama和LM Studio的结合,以及我在该过程中遇到的一些问题
1. 聊天功能
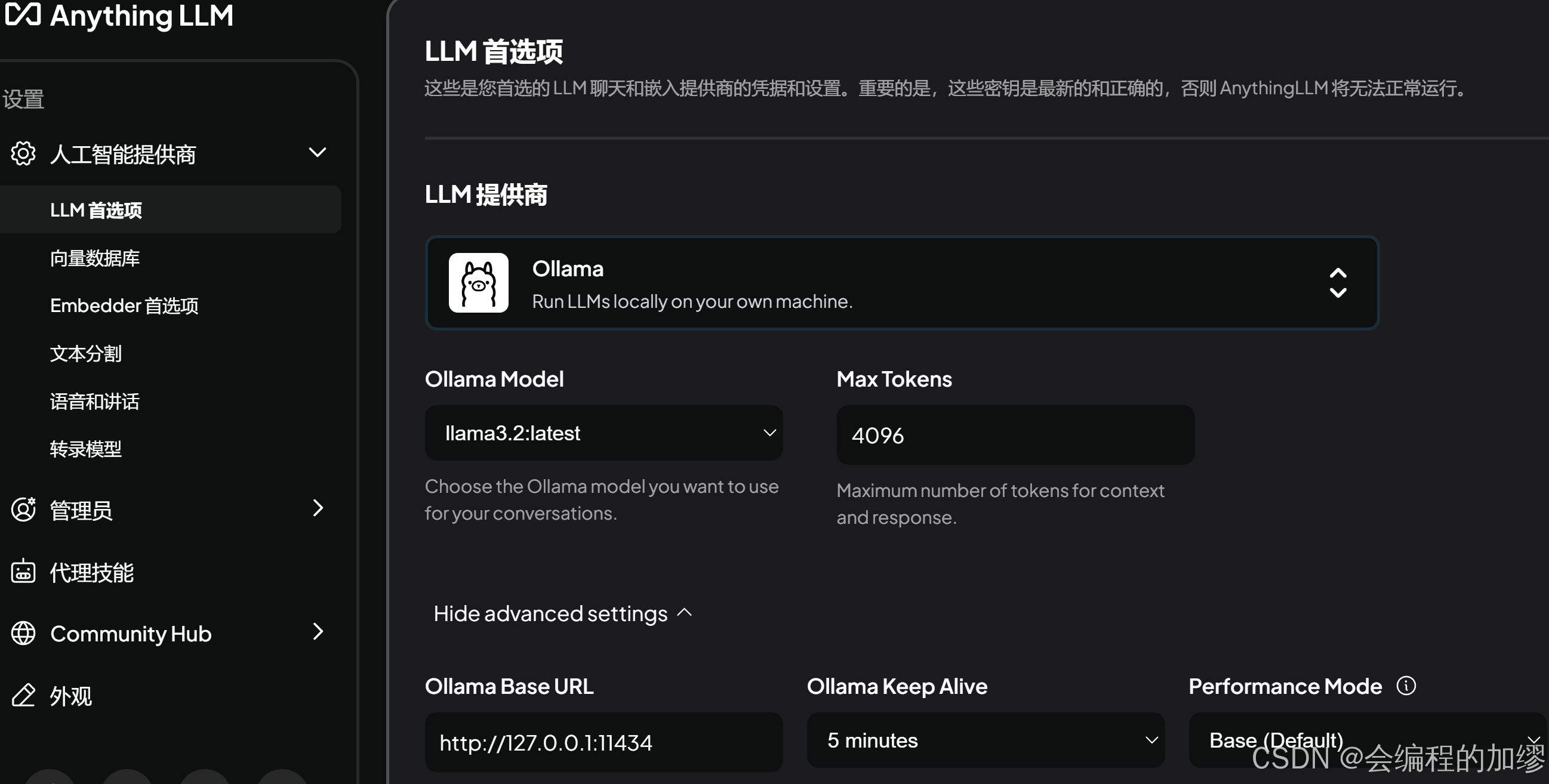
(1)Ollama
首先打开Ollama服务,确保其在运行;随后,通过设置,直接选择Ollama,找到已下载的模型,设置好后可以直接使用
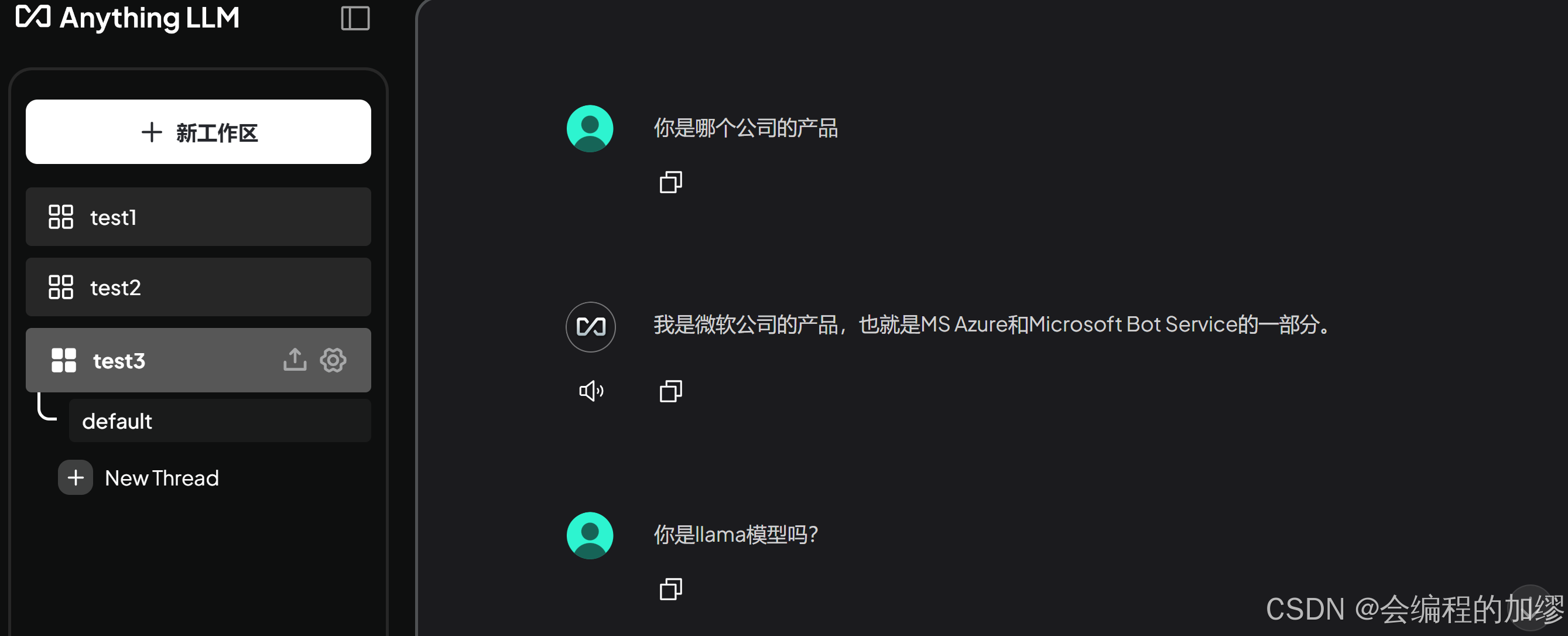
结合Ollama聊天功能可以正常使用:
(2)LM Studio
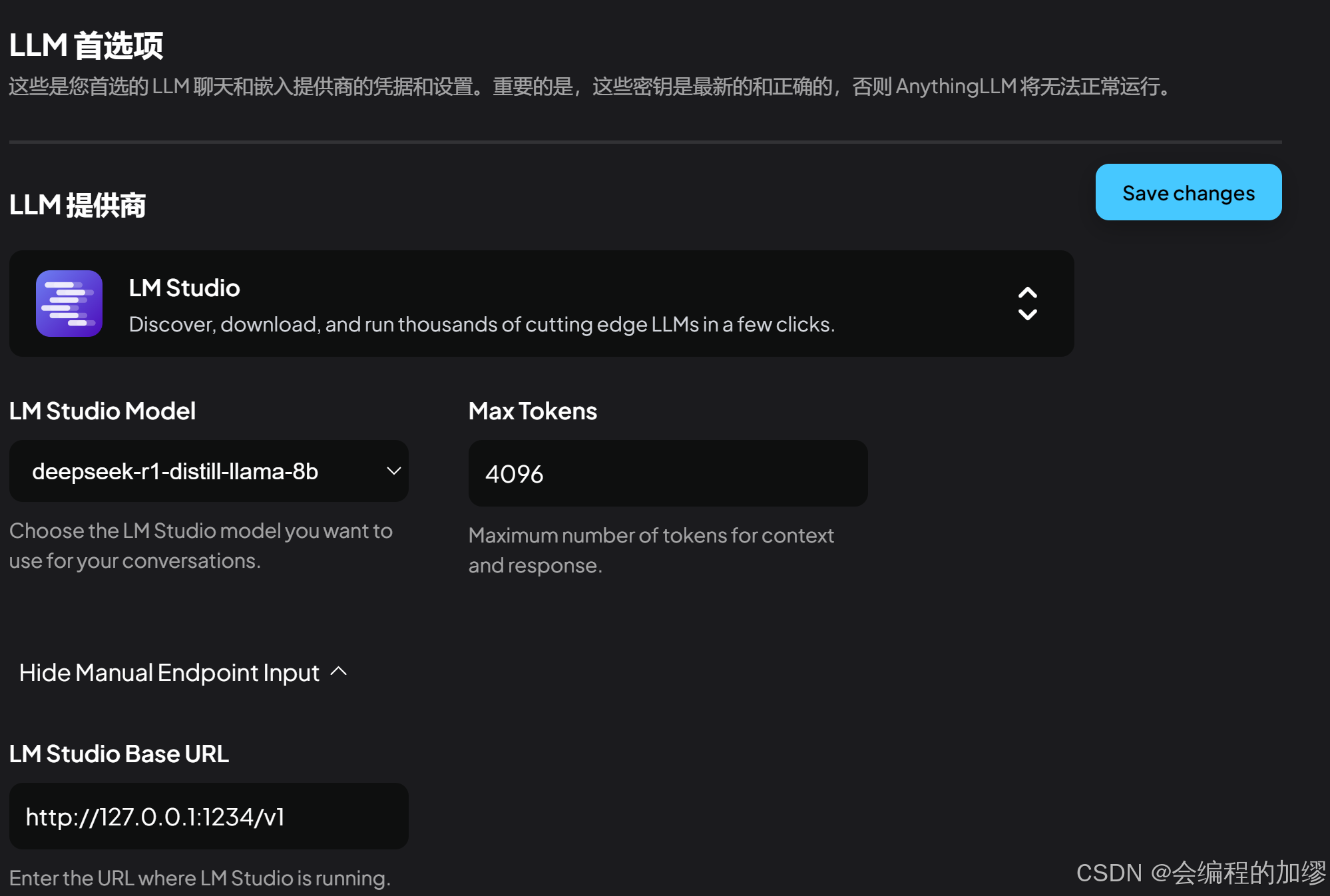
在配置LM Studio的服务时,首先应打开LM Studio,确保其在运行,然后应在左侧点击像命令行一样的标识,打开服务。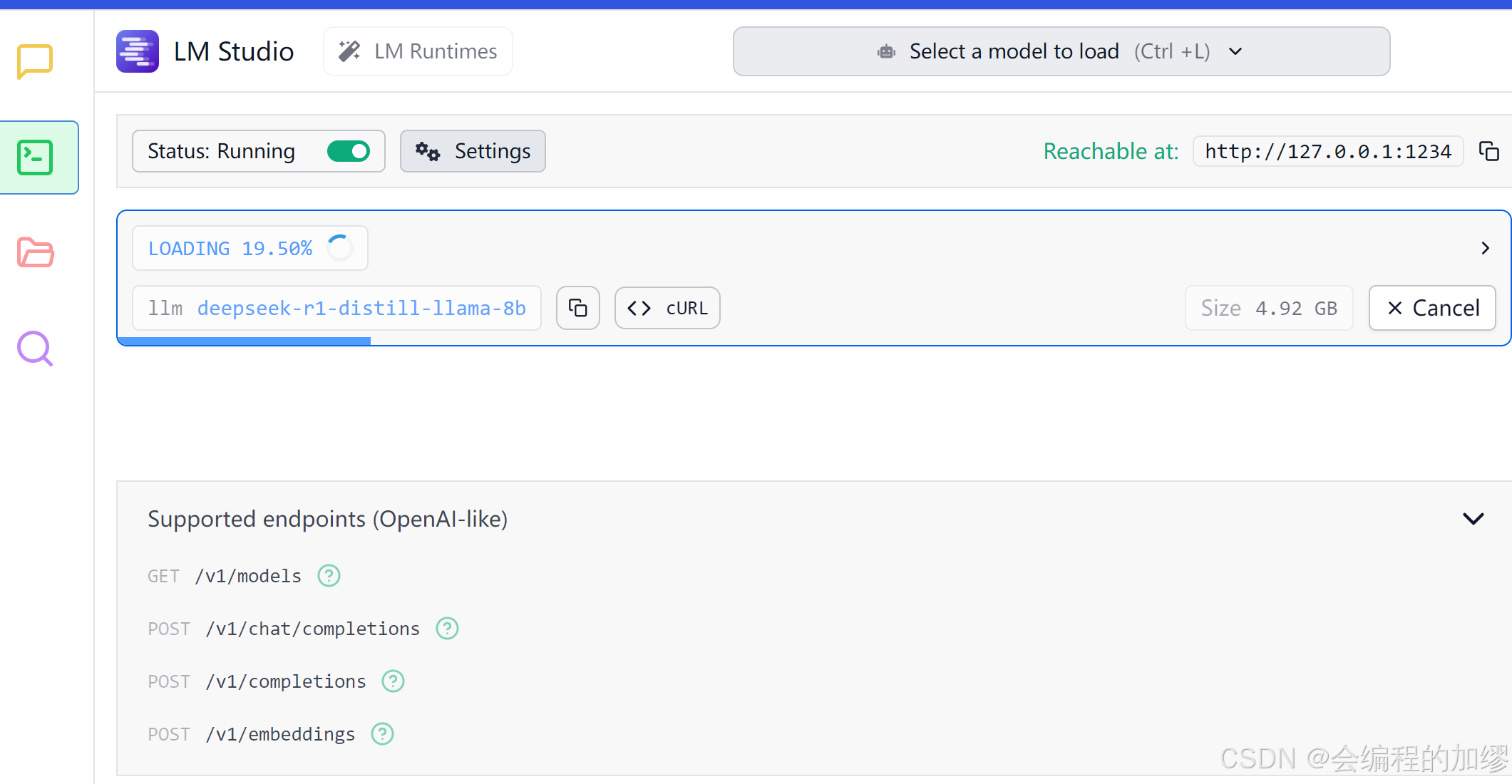
随后,在Anything LLM的设置中,输入端口网址,并加上/v1,如我的是http://127.0.0.1:1234/v1
再次和在聊天框中和模型聊天,发现模型变成了LM Studio中的Deepseek模型,多了思考的流程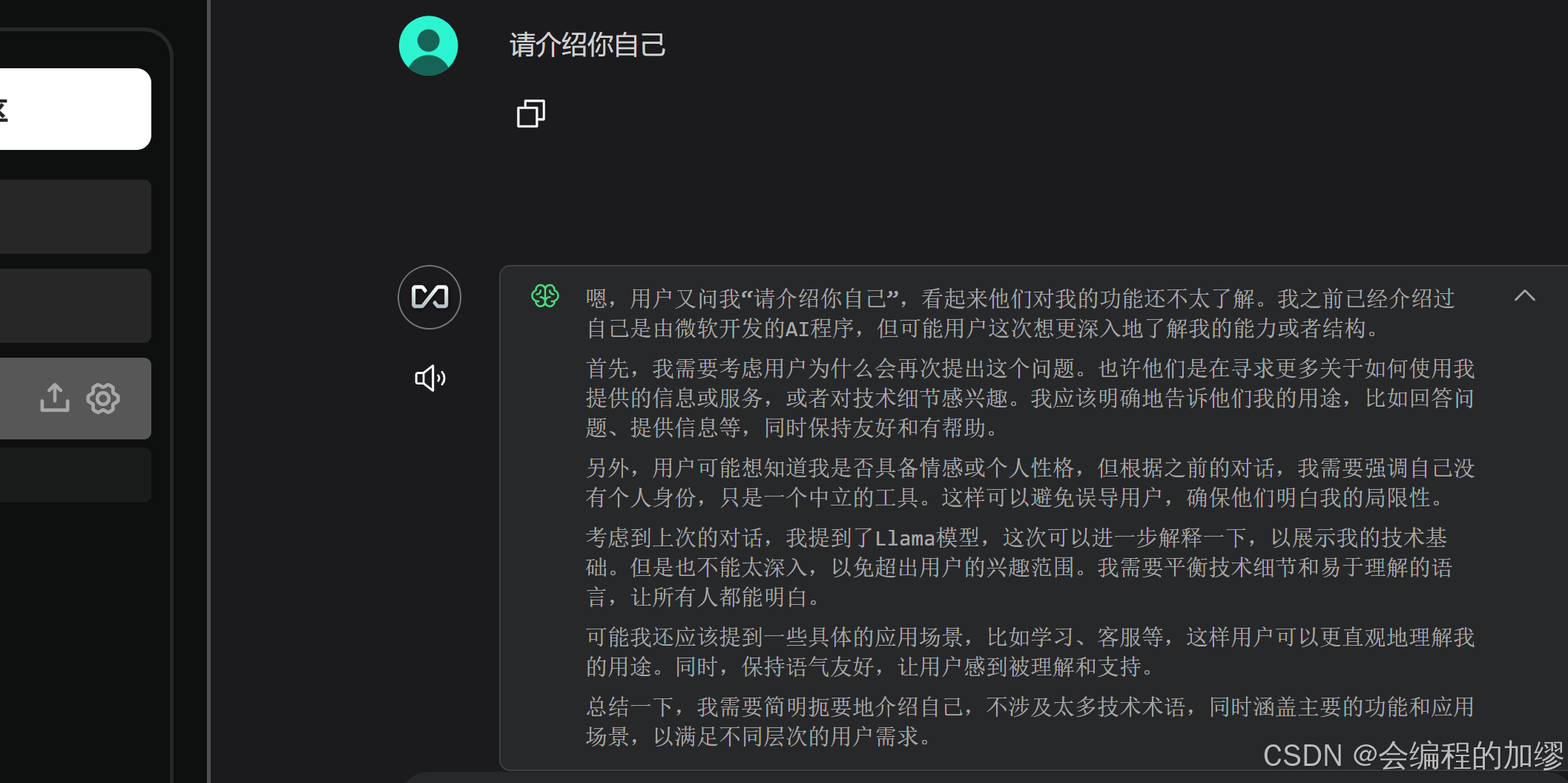
2. 本地知识嵌入
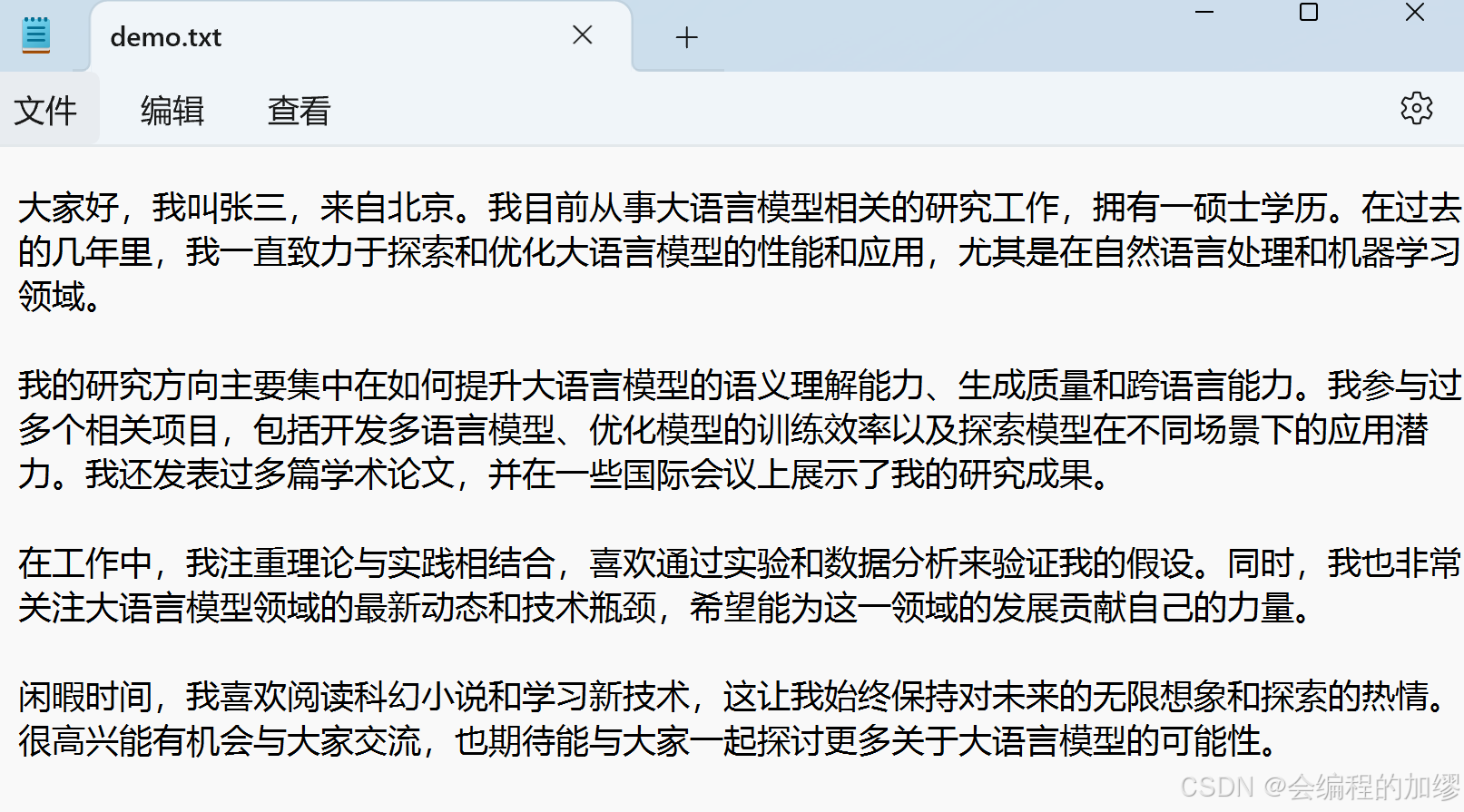
先准备一个文档,我让其他语言模型生成了一个关于张三的自我介绍
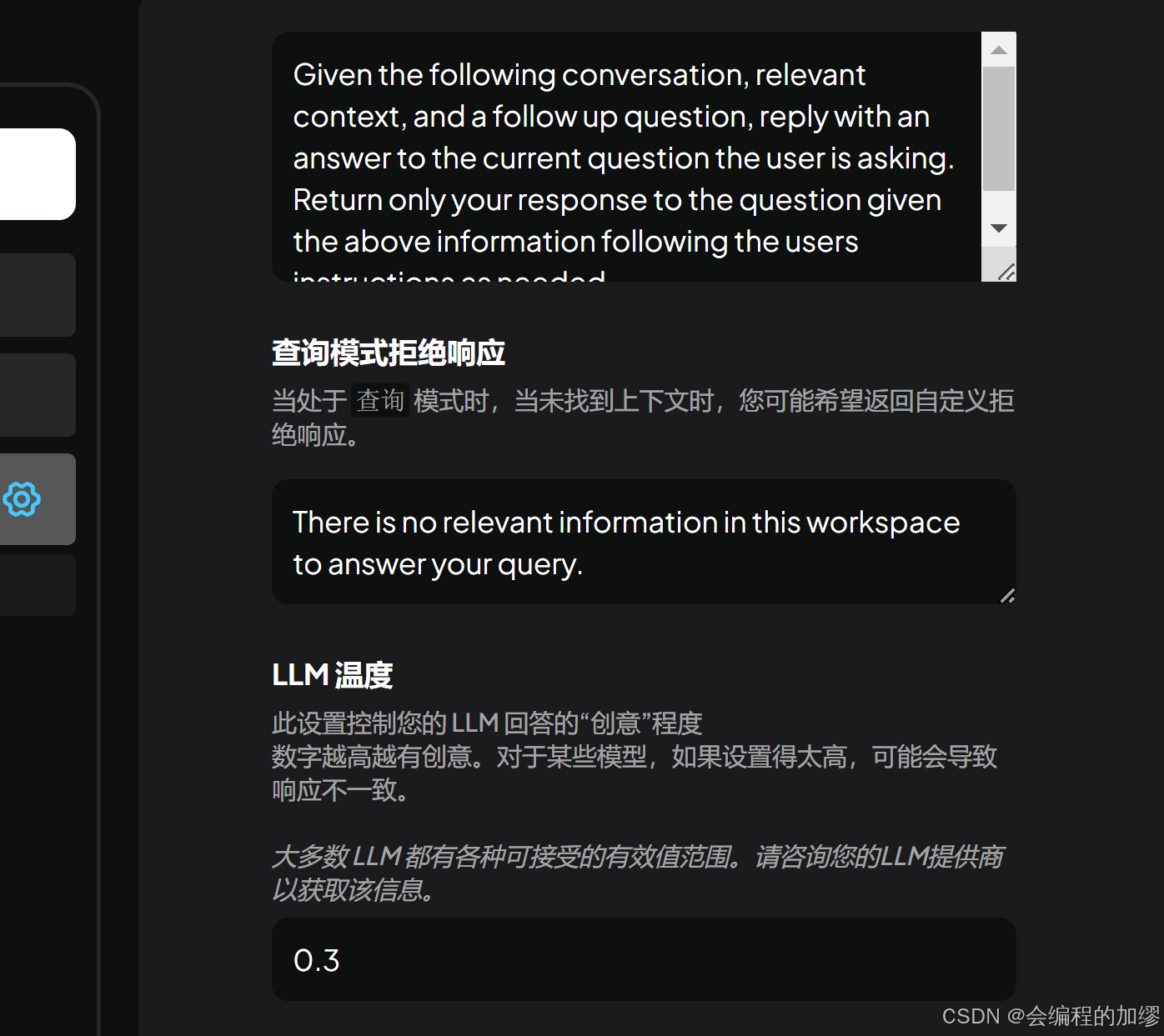
进行知识嵌入时,可以提前设置大模型的温度,设置的越低,回答越靠谱
(1)Ollama
在设置中Embedder首选项一栏选择Ollama作为嵌入引擎
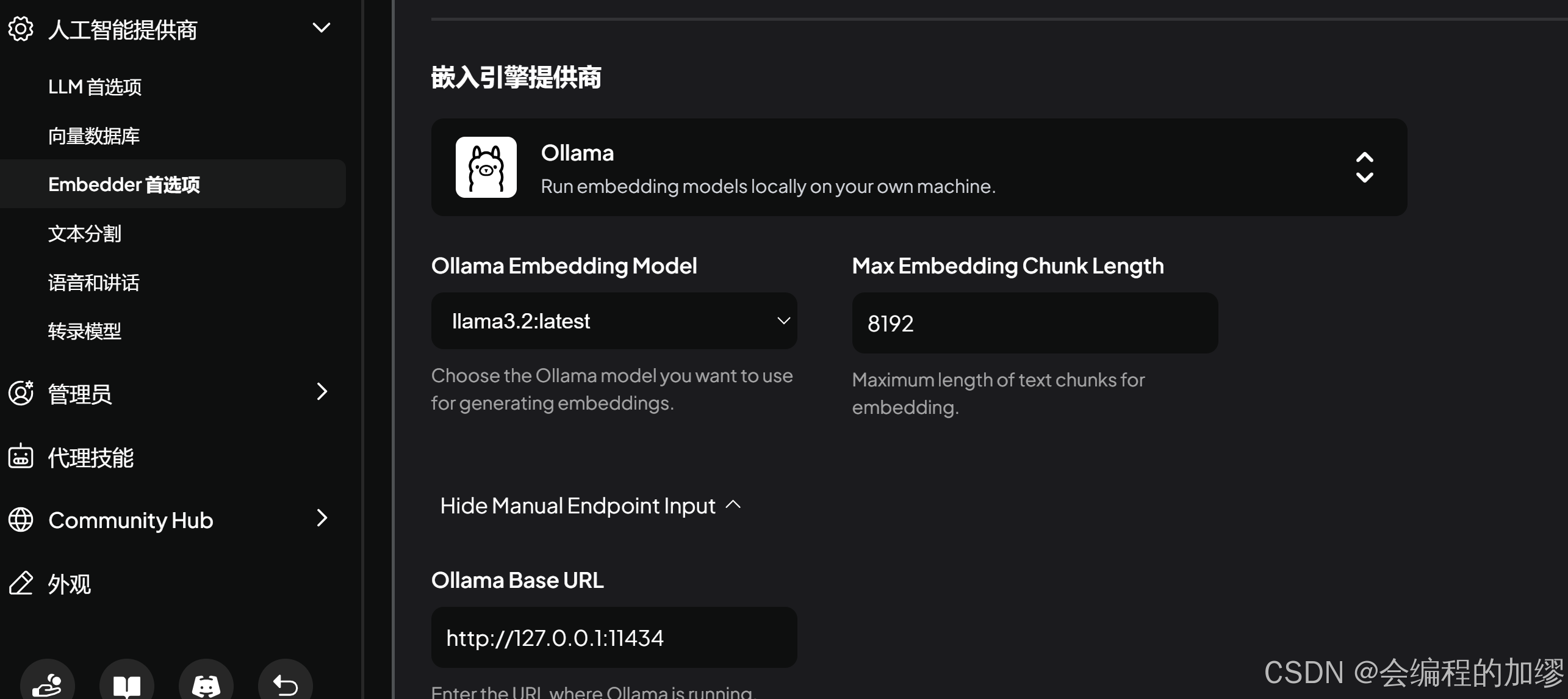
在没有嵌入本地知识之间,让大模型介绍一下张三:

通过上传按钮,为大模型嵌入刚才设置的demo: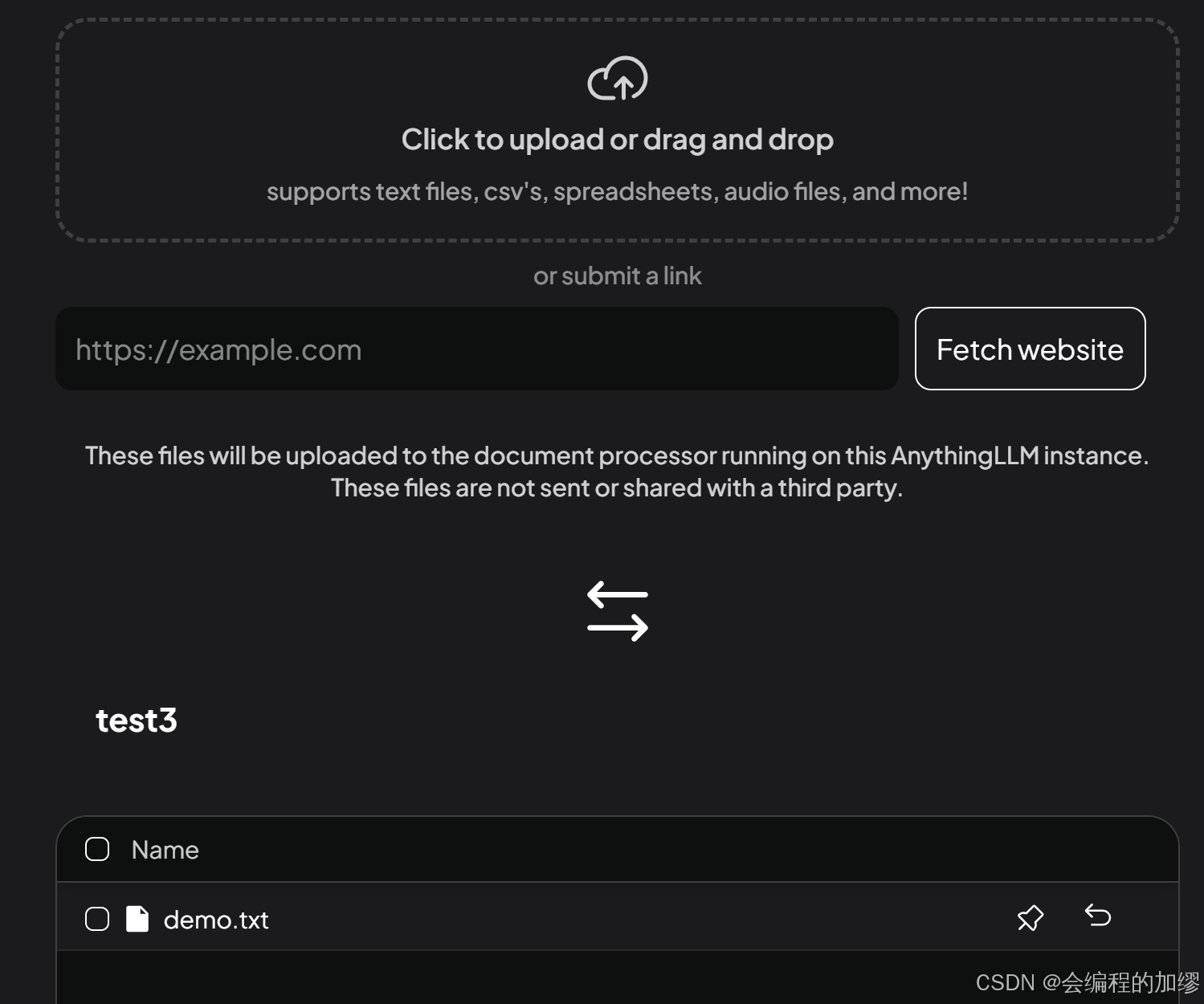
可以看到,在test3的工作空间中,已经嵌入了demo.txt文件,然后再让大模型介绍一下张三,可以看到大模型引用了我们的demo文件:
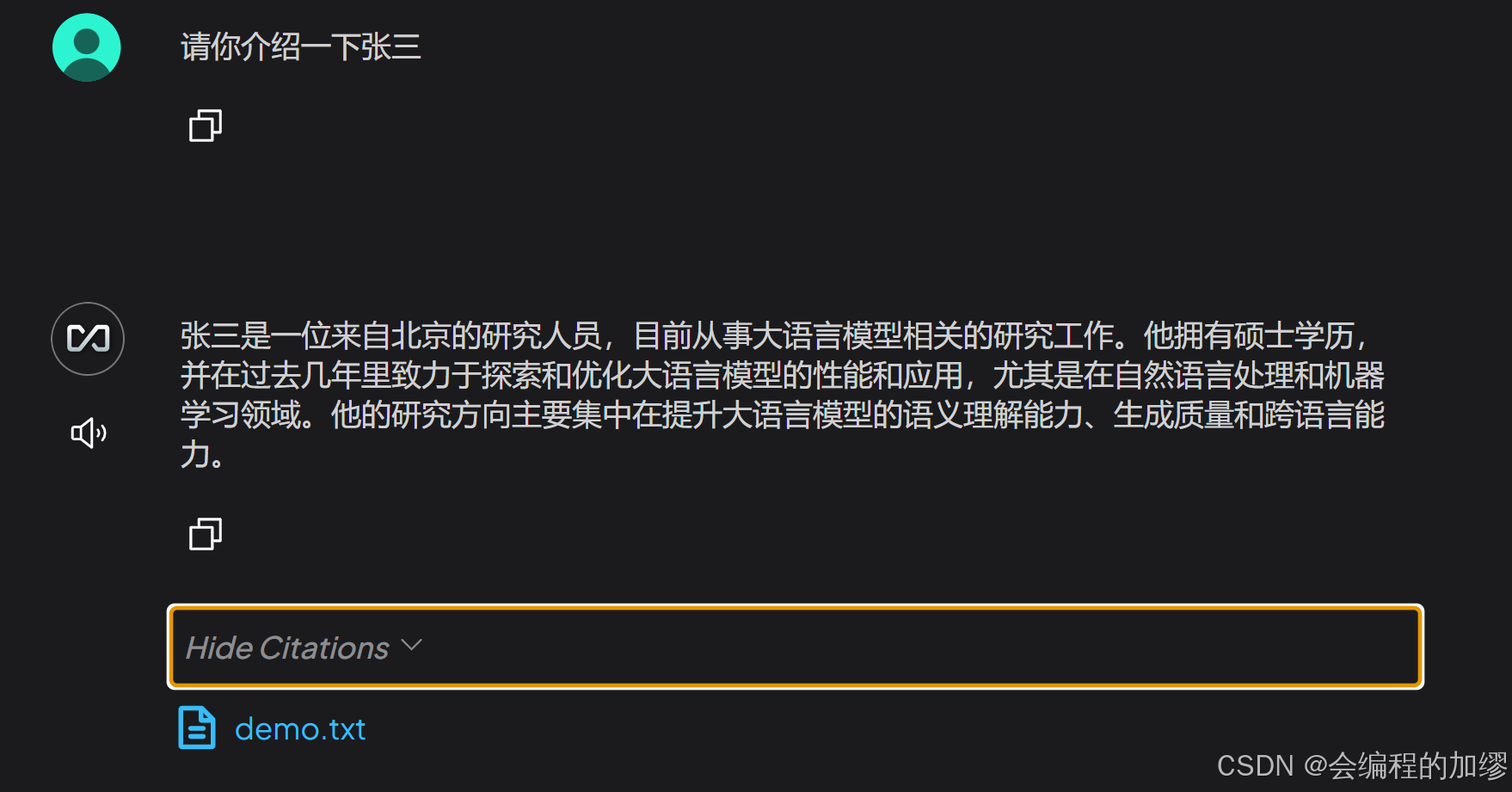
(2)LM Studio
在设置中将模型改为LM Studio,为了保持对比一直,选用的模型是meta-llama-3.1-8b-instruct,我之前试过了deepseek-r1-distill-llama-8b在anything llm 里面嵌入本地知识会显示模型加载失败,因此,在这里我先展示llama感兴趣的朋友可以去实验一下deepseek-r1。果然又报错了:

该问题暂时没有找到解决办法,我的解决办法是用Ollama+anything llm组合,但是LM Studio软件本身就可以传入文件,只不过不像anything llm一样可以持久保存本地知识(打开新的对话,依旧能为我介绍张三是谁)
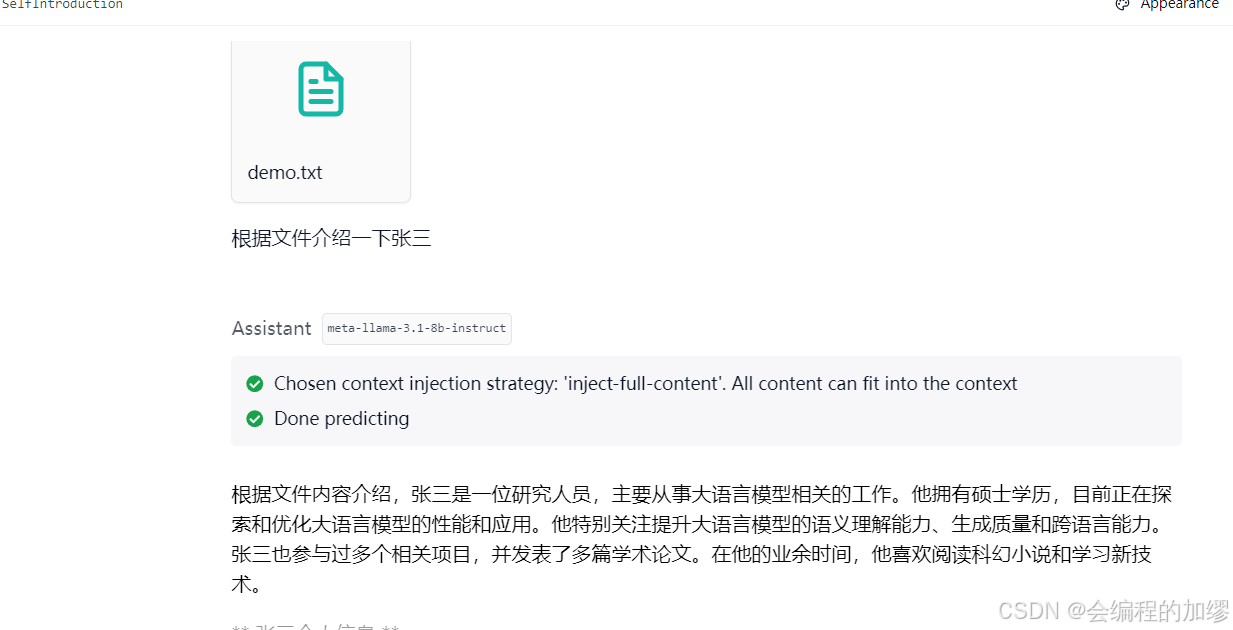
Ollama官网链接: https://ollama.com/ ↩︎
LM Studio官网链接: https://lmstudio.ai/ ↩︎


















 1780
1780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











