






transformer其实就是一个seq2seq的模型,这个模型的输入是一个向量sequence,输出也是一个向量sequence,对于输入和输出人工不能进行判断的时候,而是让机器来决定输入和输入的长度,最常见的有语音辨识、语音合成、聊天机器人、自然语言处理等领域。
如何实现transformer主要是有encoder和decoder:输入给encoder,encoder再给decoder,通过decoder就能得到输出结果。
一、encoder讲解
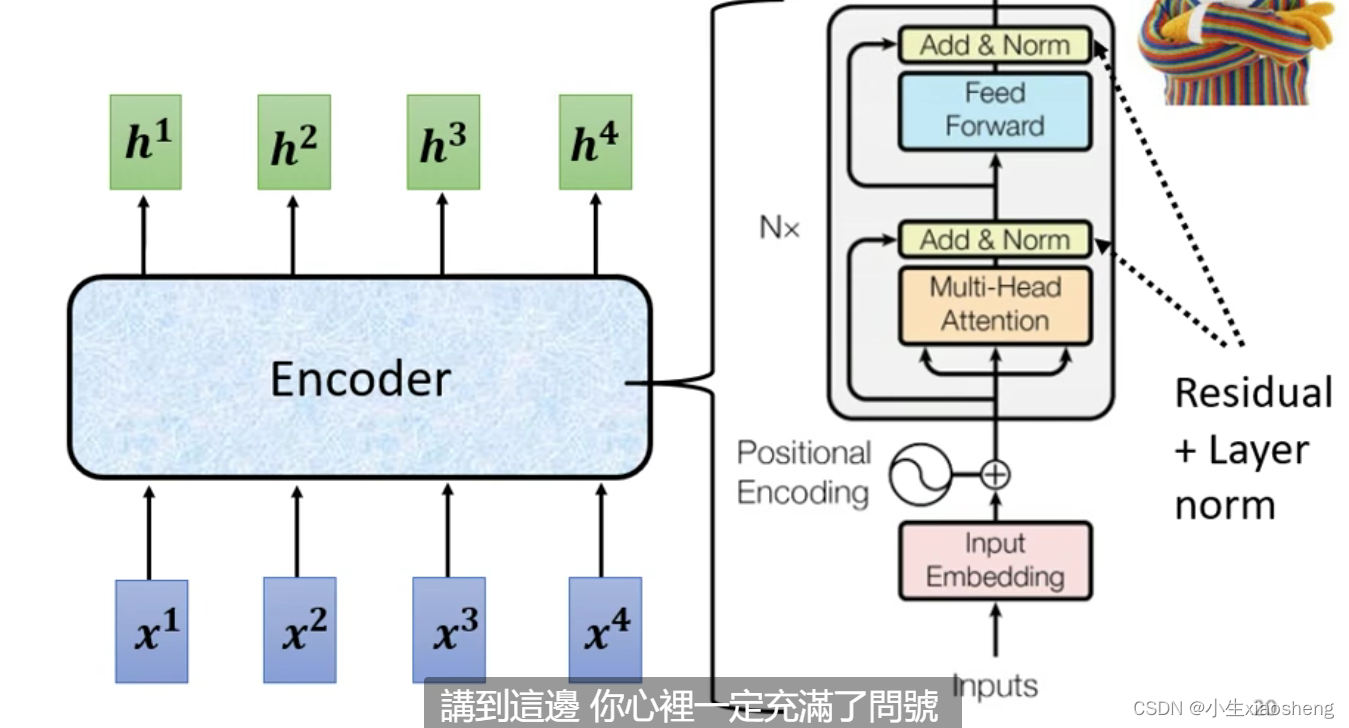
encoder要做的就是输入一排向量通过block再输出一排向量,运用到的有self-attention,循环最后在最终得到一组完美向量,一个block里面做了很多层的事情,layer norm把输入向量经过计算之后变为其他一个向量,positional encoding是输入矩阵的位置资讯,feed forward是fc全连接。
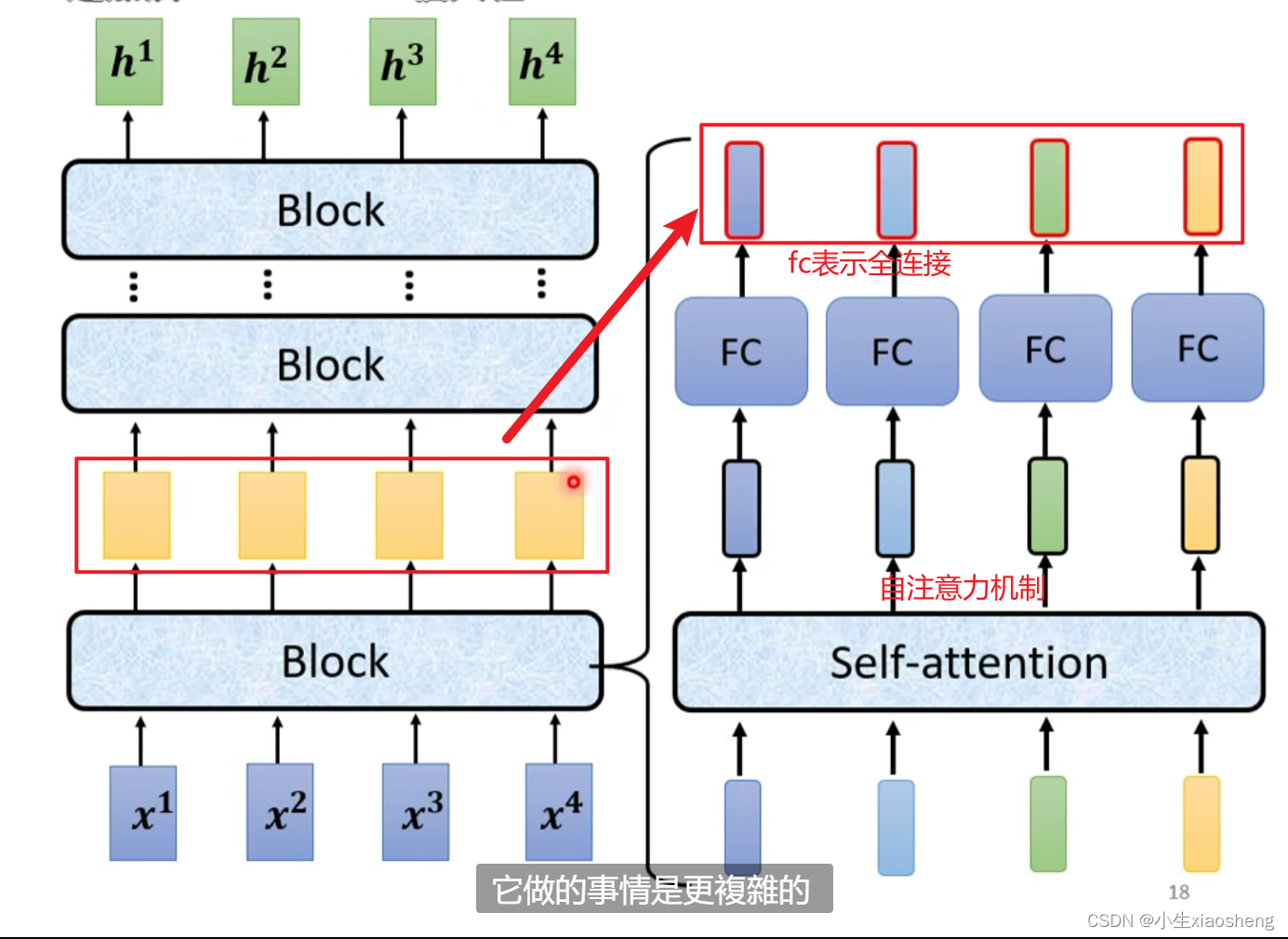
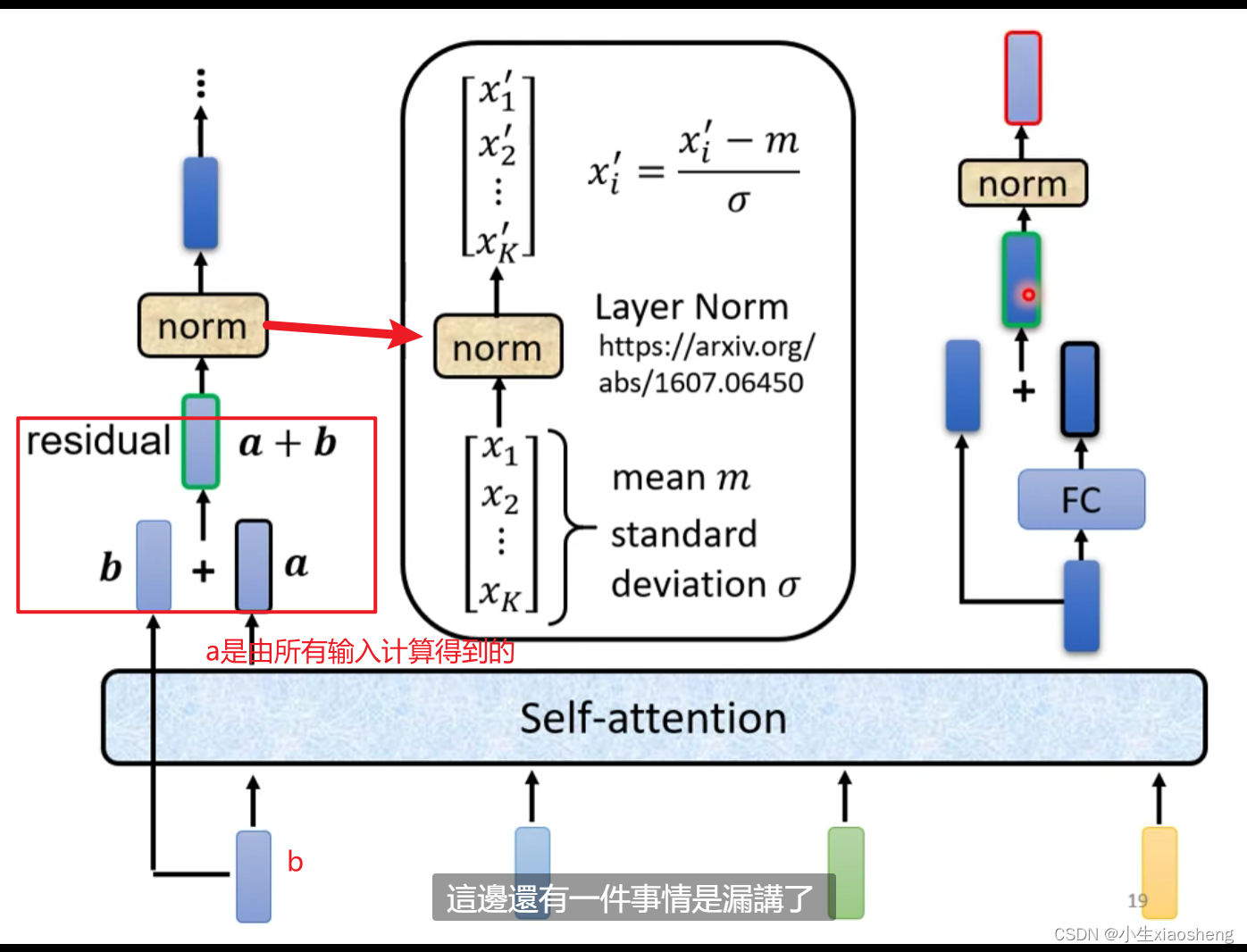
encoder的总体结构:
二、decoder讲解
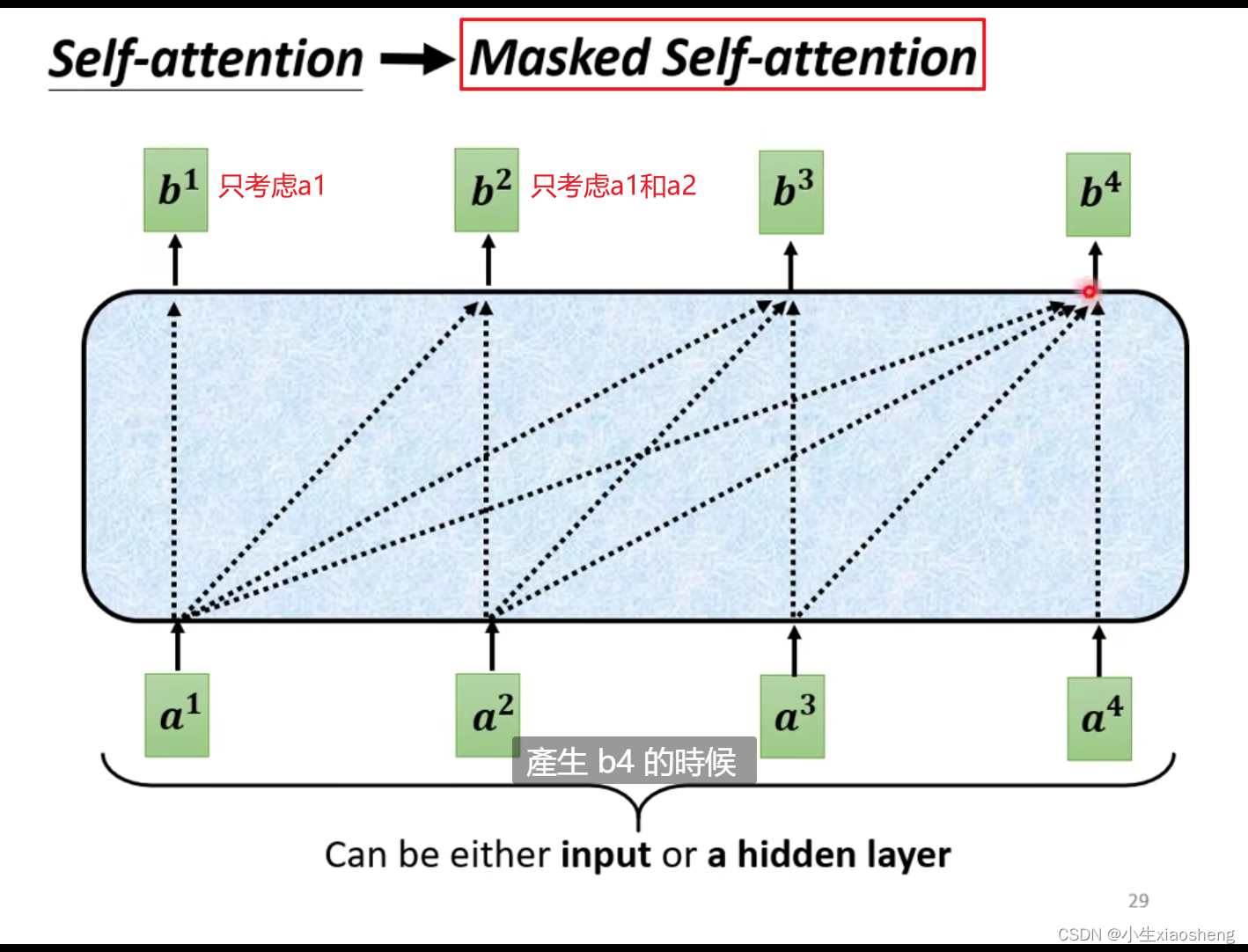
decoder是如何输出我们想要的结果呢:首先把encoder输出的向量作为decoder的输入,再把一些特殊符号(begin)作为decoder的输入,然后decoder就有一个输出向量,softmax是要让输出结果估计值的总和要为1,通过比较估计值的大小来确定这个输出到底是什么,把这个输出再作为decoder的输入,一直循环,直到完成所有输出。masked attention的意思是以前做self attention的时候是要考虑所有的输入但是现在只能是考虑前面的输入,这个输入是一个一个进入输入的而不是一次性全部输入,那如何停止下来?准备特殊符号(end)在输出的向量里面,这样就结束了。
decoder的总体结构:
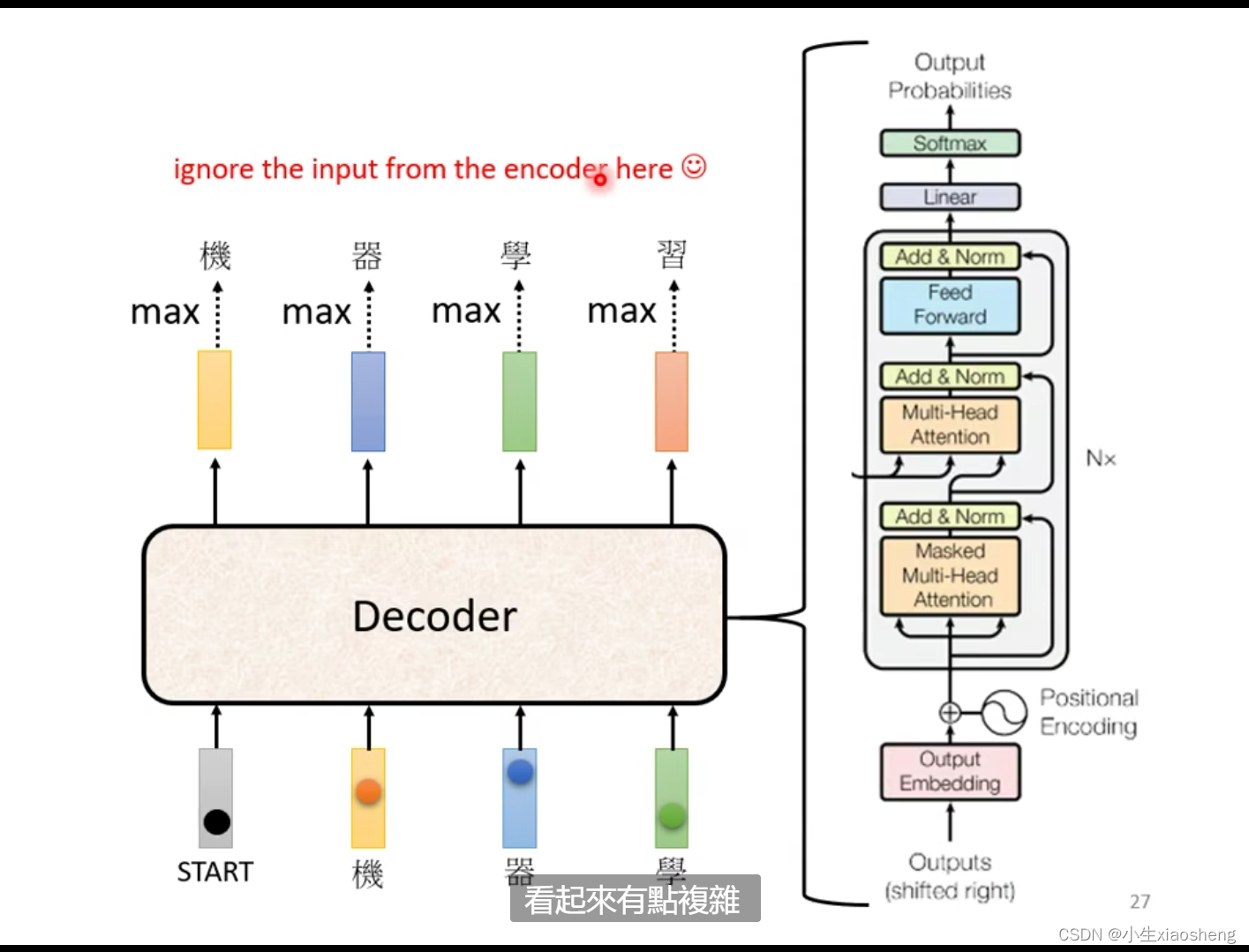
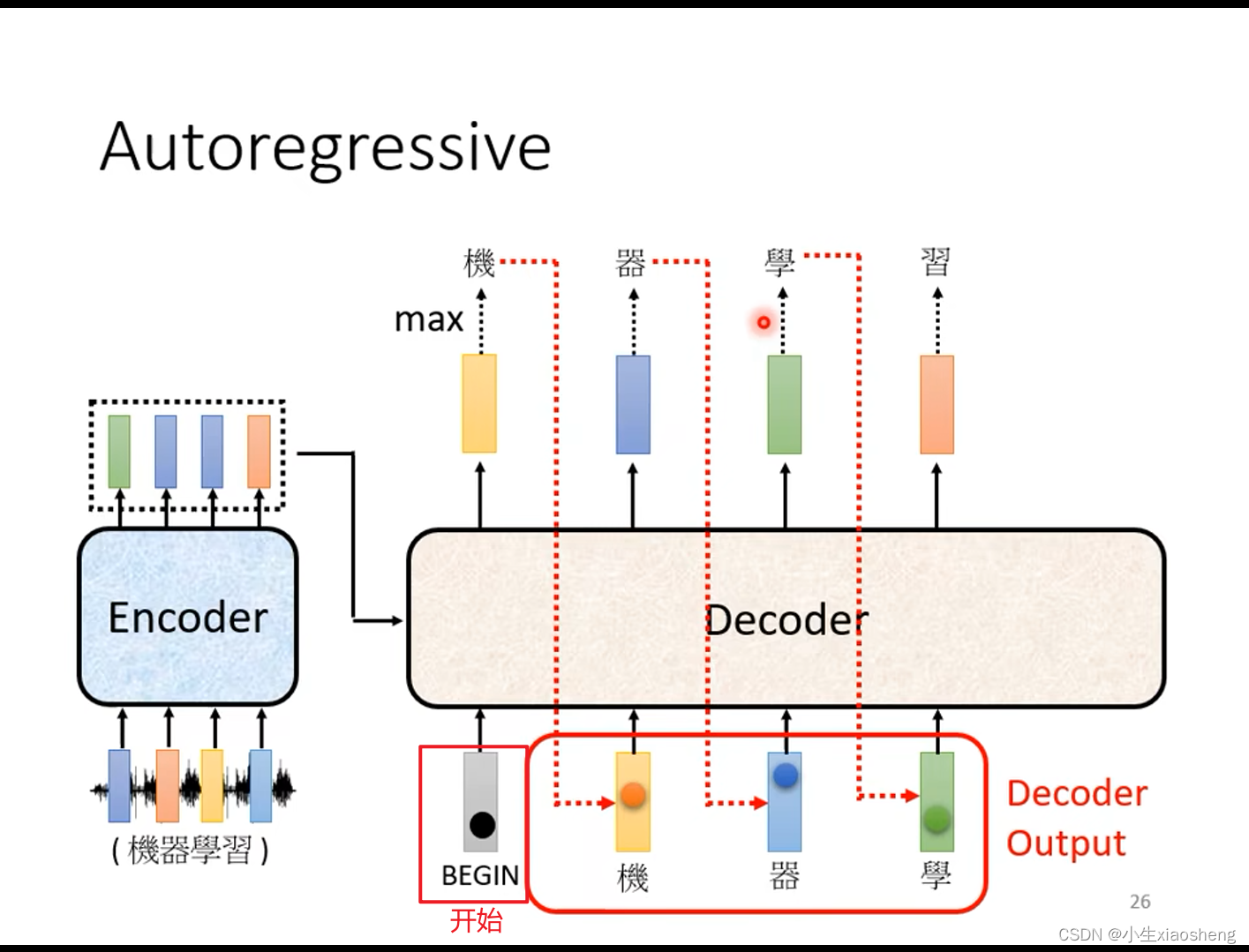
以上就是AT decoder的实验过程,改进有NAT decoder,就是说一次性全部输入(begin)这样就能里面得到所有的输出,和AT可以理解为串行和并行的区别,但是存在参数难以得到的问题(多模态是热门话题)。
三、encoder和decoder的连接
cross attention(交叉注意)是连接encoder和decoder的桥梁,这个部分是在decoder的feed forward下面
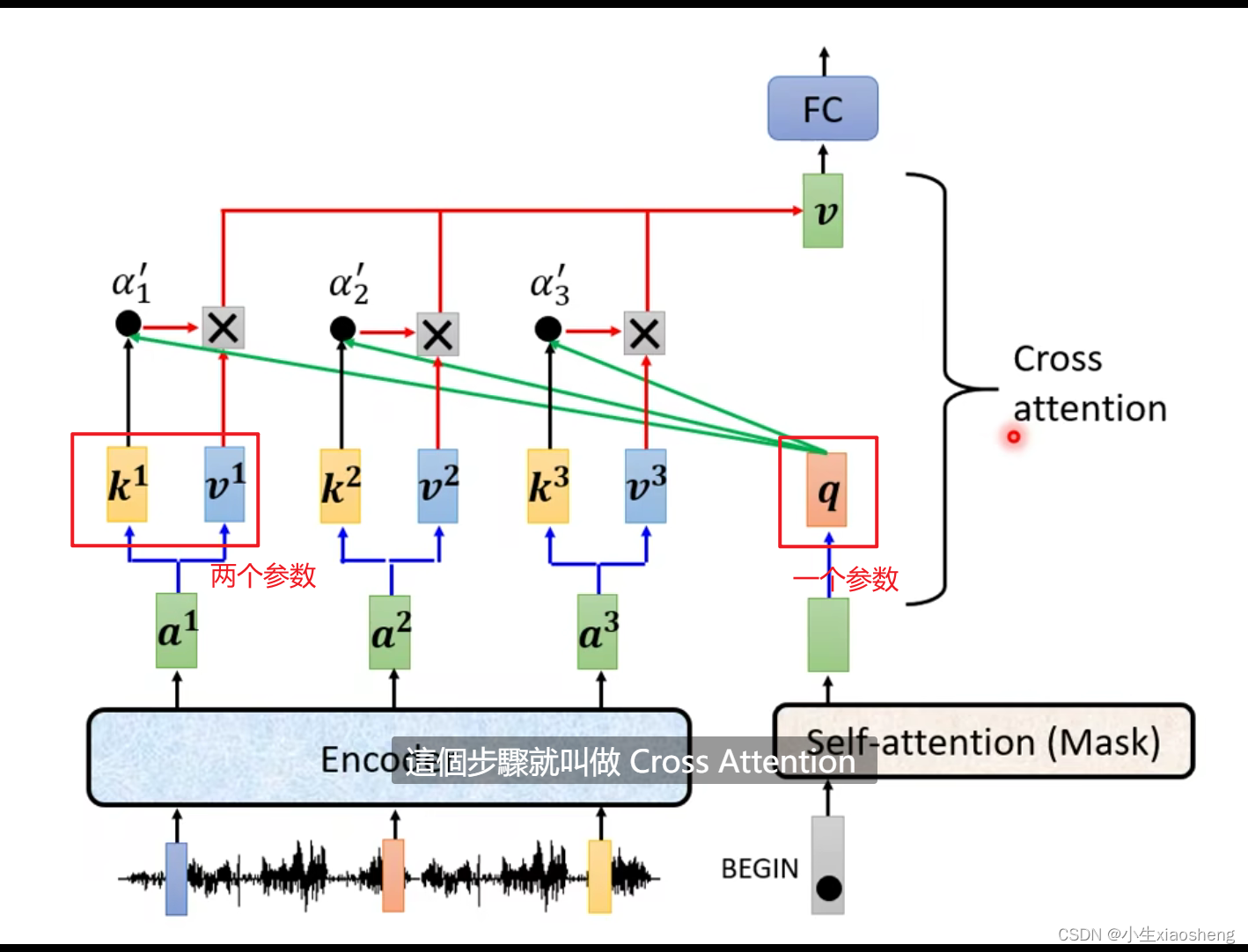
四、细节
teacher forcing:把正确答案当作decoder的输入
copy mechanism:对于对话能力,就是让机器不用对于输入再创造出输出,而是可以用部分相同的输入当作输出。
guided attention:让机器在做attention的时候有一个固定的过程,比如在语音合成的时候。
greedy decoding: 如何找到最好的路径(因为即使是当前这个最好但是后面的文字可能越来越不行),每次找分数最高的token来当作输出
beam search:找一个好的路径,但是不一定一直很有用,而且可能出现不好的问题(当要让机器具有创造力的时候)
bleu score:输出要和正确的结果进行比较(RL)
训练跟预测是不一致的,因为训练的时候只看到了正确的信息,但是在预测的时候可能出现一个输出的错误,那么整个结果可能就错误了。















 1128
1128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









