






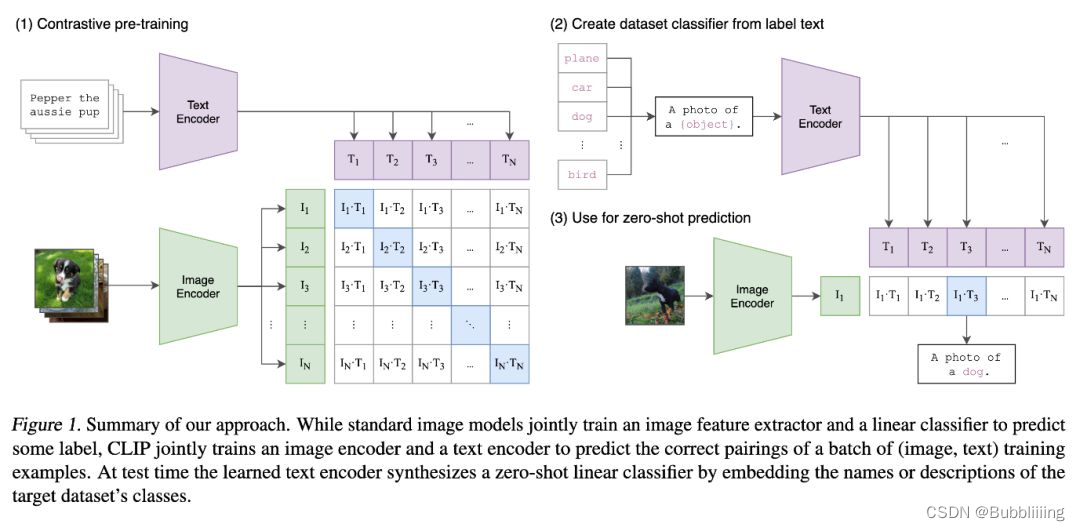
- CLIP的全称是Contrastive Language-Image Pre-Training,中文是对比语言-图像预训练,是一个预训练模型,简称为CLIP。
- CLIP一共有两个模态,一个是文本模态,一个是视觉模态,分别对应了Text Encoder和Image Encoder。
- Text Encoder用于对文本进行编码,获得其Embedding;Image Encoder用于对图片编码,获得其Embedding。
- 然后进行相乘,可以获取图像文本矩阵,代表的就是图片与文本的相似程度,目标函数就是最大化对应的相似性系数,即基于比对学习让模型学习到文本-图像的匹配关系
https://blog.csdn.net/weixin_38252409/article/details/133828294

















 544
544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









