







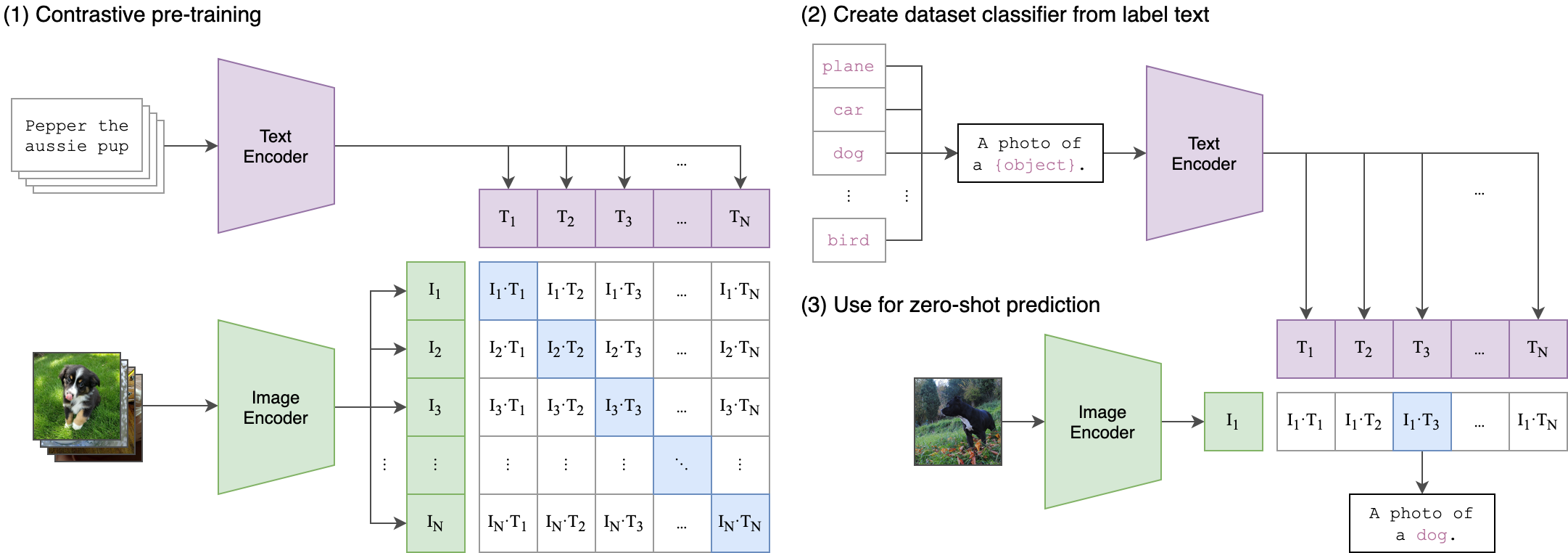
CLIP的全称是Contrastive Language-Image Pre-Training,中文是对比语言-图像预训练。
CLIP的主要目标是通过对比学习,学习匹配图像和文本。在训练过程中,模型学会了将图像和文本编码成统一的向量空间,这使得它能够在语言和视觉上理解它们之间的关系。通过这种方式,CLIP可以识别图像中的物体、场景、动作等元素,同时也能够理解与图像相关的文本,例如标签、描述、标题等。
CLIP的基本原理是对比学习,即让模型学习区分正样本(匹配的图像和文本对)和负样本(不匹配的图像和文本对)。为了实现这一目标,CLIP使用了一个多模态编码器,它由两个子编码器组成:一个用于图像,一个用于文本。图像编码器可以是基于卷积神经网络(CNN)或者视觉变换器(ViT)的模型,文本编码器则是一个基于Transformer的模型。这两个编码器都可以将输入转换为一个固定长度的向量表示,然后通过计算向量之间的余弦相似度来衡量图像和文本之间的匹配程度。
CLIP模型在各种图像分类任务上表现优异,包括对一般图像、细粒度分类、检索任务和少样本学习的支持。同时,它还能够识别和理解图像中的复杂概念,比如人类行为、建筑物和文化符号等,这对于各种视觉应用非常有用。
CLIP的应用非常广泛,包括图像检索、视觉问答、视觉导航、图像生成等等。此外,OpenAI还推出了一个名为DALL-E的模型,它是在CLIP模型的基础上开发的一种生成模型,能够基于自然语言描述生成图像。
使用示例:
import torch
import clip
from PIL import Image
# 加载预训练模型
model, preprocess = clip.load('ViT-B/32', device='cpu')
# 加载图像
image = Image.open('image.jpg')
# 对图像进行预处理
image_input = preprocess(image).unsqueeze(0)
# 运行模型
with torch.no_grad():
image_features = model.encode_image(image_input)
# 加载类别标签
class_labels = ['cat', 'dog', 'flower', 'food', 'car']
# 加载类别描述
class_descriptions = clip.tokenize(class_labels).to(model.device)
# 计算图像与类别描述之间的相似度
logits_per_image, logits_per_text = model(image_input, class_descriptions)
probas = logits_per_image.softmax(dim=-1).cpu().numpy()
# 输出预测结果
for i, class_label in enumerate(class_labels):
print(f"{class_label}: {probas[0][i]}")网络结构
Image encoder
第一部分
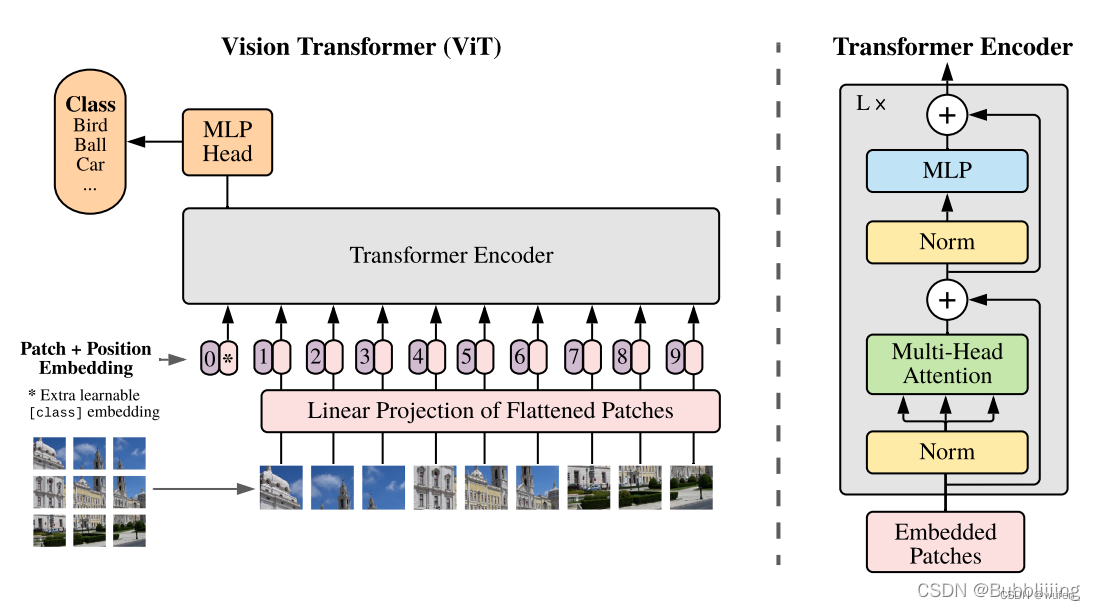
先卷积,卷积后添加class token,获得序列信息
class VisionTransformer(nn.Module):
def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
super().__init__()
self.input_resolution = input_resolution
self.output_dim = output_dim
#-----------------------------------------------#
# 224, 224, 3 -> 196, 768
#-----------------------------------------------#
self.conv1 = nn.Conv2d(in_channels=3, out_channels=width, kernel_size=patch_size, stride=patch_size, bias=False)
scale = width ** -0.5
#--------------------------------------------------------------------------------------------------------------------#
# class_embedding部分是transformer的分类特征。用于堆叠到序列化后的图片特征中,作为一个单位的序列特征进行特征提取。
#
#  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











