







Abstract

图1所示。我们使用我们的方法和LangSplat[30]从稀疏、无posefree输入呈现语义渲染。我们的方法在多视图一致性和渲染质量上都优于LangSplat,产生更准确和视觉连贯的结果。
最近,一些研究将3D高斯与语言嵌入相结合,以获得用于开放词汇3D场景理解的场景表示。虽然这些方法表现良好,但它们本质上需要非常密集的多视角输入,这限制了它们在现实场景中的适用性。在这项工作中,我们提出了SparseLGS,以解决使用无姿态和稀疏视角输入图像进行3D场景理解的挑战。我们的方法利用基于学习的密集立体模型来处理无姿态和稀疏输入,并采用三步区域匹配方法来解决多视角语义不一致问题,这对于稀疏输入尤为重要。与直接学习高维CLIP特征不同,我们提取低维信息并建立双射,以避免过高的学习和存储成本。我们在语义训练期间引入重建损失,以改善高斯位置和形状。据我们所知,我们是第一个使用稀疏无姿态输入解决3D语义场问题的。实验结果表明,与之前使用密集输入的最先进方法相比,SparseLGS在使用较少输入(3 - 4个视角)重建语义场时能达到相当的质量。此外,当使用相同的稀疏输入时,SparseLGS在质量上明显领先,并且大幅提高了计算速度(加速5倍)。项目页面:[https://ustc3dv.github.io/SparseLGS](https://ustc3dv.github.io/SparseLGS)
1. Introduction
在本文中,我们提出稀疏视图语言嵌入式高斯飞溅(SparseLGS)来解决从稀疏视图输入获取3D语言字段的挑战。为了克服传统的现有方法(如COLMAP)在极度稀疏的视图下常常无法进行点云重建的局限性,我们采用了基于学习的密集立体方法MASt3R来估计相机姿势并生成初始点云。
随后,我们利用SAM和CLIP获得对象级语义结果。在具有密集视图输入的场景中,可以纠正多视图语义中的不一致性,因为视图的丰富性允许准确的信息掩盖少数不正确的信息。
然而,使用稀疏输入(例如,只有3-4个视图),不正确的结果可能会扭曲正确的结果。为了解决这个问题,我们采用了一种三步多视图语义对齐方法,利用像素匹配和区域融合等技术来实现精确的对齐。为了减轻原始特征重建过程中的信息损失,我们在低维结果和原始CLIP特征之间建立了双射。这允许我们使用基于tile的呈现来获得呈现的语义结果,然后利用双向映射来恢复原始的CLIP特性,从而启用开放语言查询。
由于语义掩码提供了区域化信息,同一掩码区域内部除边界信息外相同,仅使用语义作为真实值并不能提供足够的几何约束。因此,我们首先使用 RGB 图像训练高斯参数来初始化高斯分布。随后,我们引入语义损失来指导语义场的训练并微调高斯参数。总之,本文的贡献包括:
- 我们提出了SparseLGS,据我们所知,这是首个探索从稀疏无姿态视图输入重建3D语言场的工作。
- 我们提出“三步语义多视图匹配”来解决输入视图间语义和掩码的不一致性。此外,我们在原始CLIP特征和降维特征之间建立双射,以防止在原始特征重建过程中出现退化。
- 在使用RGB图像监督优化高斯参数后,我们在语义场学习过程中保留这种监督,以更好地约束场景几何。这种策略有效地保证了在稀疏输入下所学语义场的3D一致性。
3. Method
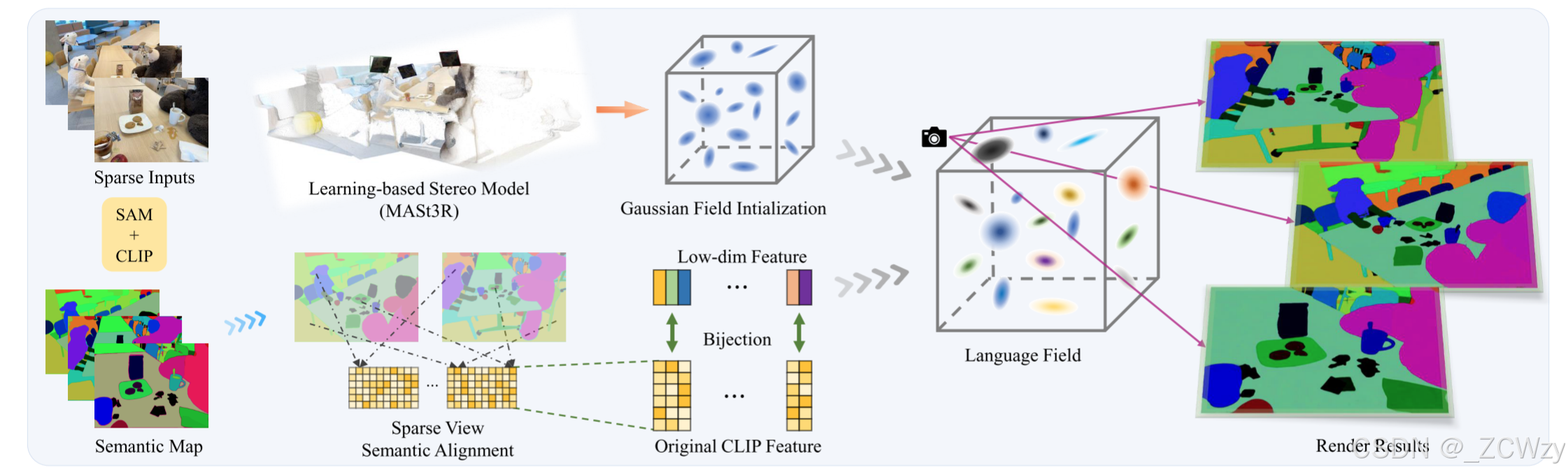 图2。我们的方法SparseLGS能够在几分钟内从无姿态的稀疏视图输入生成高质量的语言字段。我们首先利用SAM和CLIP获得对象语义图,然后使用基于学习的立体模型从稀疏输入中导出相机姿势和点云。为了解决视图之间的语义不一致,我们采用了三步多视图语义对齐策略。为了更好地将语义与高斯飞溅相结合,我们在原始CLIP特征和降维特征之间建立了一个双射。在培训过程中,我们结合RGB监督来增强我们所学语言领域的3D一致性。
图2。我们的方法SparseLGS能够在几分钟内从无姿态的稀疏视图输入生成高质量的语言字段。我们首先利用SAM和CLIP获得对象语义图,然后使用基于学习的立体模型从稀疏输入中导出相机姿势和点云。为了解决视图之间的语义不一致,我们采用了三步多视图语义对齐策略。为了更好地将语义与高斯飞溅相结合,我们在原始CLIP特征和降维特征之间建立了一个双射。在培训过程中,我们结合RGB监督来增强我们所学语言领域的3D一致性。
整个管道如图2所示。我们将简要介绍3d高斯,并在3.1节中描述如何获得用于语义场训练的面向对象的语义特征。在第3.2节中,我们介绍了多视角立体模型,以准确估计相机姿态并生成初始点云。我们将在3.3节中解决稀疏输入下的多视图不一致问题。最后,我们在3.4节阐述了我们的两步训练思路和具体做法。
3.1. Preliminary
为了实现语义3d高斯 splatting,每个高斯额外分配一个语义特征
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1305
1305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









