锥形束ct (Cone beam computed tomography, CBCT)已广泛应用于临床,尤其是牙科诊所,但其成像中x射线捕获时的辐射剂量一直是CBCT成像中关注的问题。一些研究工作已经提出了从稀疏视图2D投影重建高质量的CBCT图像,但目前的技术水平受到人工制品和缺乏精细细节的影响。在本文中,我们通过学习神经衰减场提出SNAF用于稀疏视图CBCT重建,其中我们发明了一种新的视图增强策略,以克服稀疏输入视图数据不足带来的挑战。我们的方法在高重建质量(即30+ PSNR)方面实现了卓越的性能,只有20个输入视图(比临床收集少25倍),优于最先进的技术。我们进一步进行了全面的实验和烧蚀分析来验证我们方法的有效性。
锥形束计算机断层扫描(CBCT)已成为牙科诊所的主要成像技术(见图1)。与传统CT相比,它提供的三维信息质量更高,扫描时间更短。这些优点,特别是高重建质量,不仅使其在临床实践中广泛应用于诊断和治疗计划,也极大地促进了CBCT图像自动分析(如牙齿和牙槽骨分割[4-6])的研究进展。然而,由于需要捕获数百个视图以确保成像质量,因此x射线的辐射剂量一直是CBCT成像中关注的问题。为了在保持高成像质量的同时减少投影数量,人们提出了几种传统的稀疏视图重建方法——典型的滤波反向投影(FBP)[8],基于SART的迭代方法[2,19][1]。这些方法可以产生良好的侦察效果CBCT图像的结构,但仍然存在局限性,如条纹伪影和缺乏细节引入不足的数据。
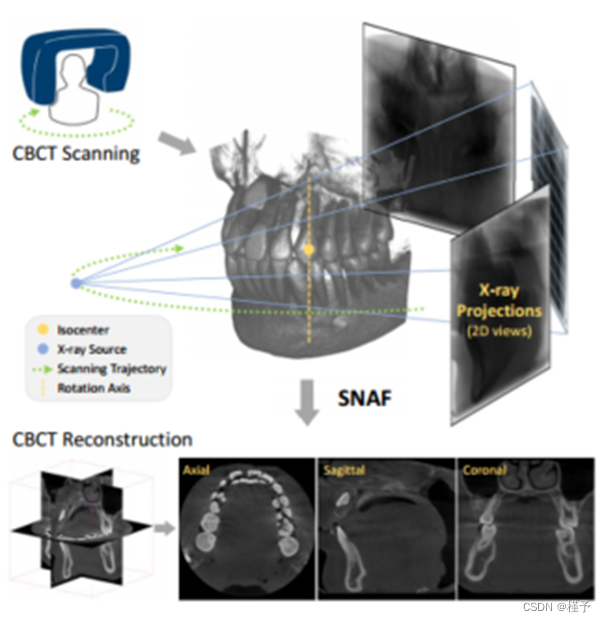
图1所示。基于神经衰减场的稀疏视图CBCT重建综述。x射线源均匀地围绕感兴趣的区域移动,并在对面的平板探测器(上)生成稀疏投影,而我们提出SNAF通过学习衰减场(下)从这些稀疏的2D视图重建精确的CBCT。
近年来,神经渲染因其结构紧凑的隐式表示而成为一种有效的新视图合成和三维场景重建技术。与CBCT重建类似,这些方法利用RGB图像来学习底层神经辐射场(nerf),在三维几何感知和多视图一致性方面表现出很大的优势。后续工作进一步提高了其快速重构能力[11,12,14]和稀疏视图重构能力[7,9,15,22]。人们高度期望这些属性有利于稀疏视图CBCT重建。然而,与使用体绘制近似表面渲染的nerf不同,CBCT重建回到真实的体绘制。在这个独特的场景中,没有自然场景中特定的物体表面,人体器官的整个空间都是信息性的,这极大地扩大了解决的空间,使问题变得复杂。此外,稀疏视图nerf中引入的流行的正则化和泛化技术,例如,利用额外的深度信息[7],也不适用。
受我们观察结果的启发,我们通过学习衰减场,提出了一种名为SNAF的新框架,用于稀疏视图CBCT重建,该框架仅使用20个输入视图(比普通临床收集少25倍),在高重建质量(即30+ PSNR)方面取得了优异的性能。从技术上讲,我们的方法建立在具有多分辨率哈希表[14]的最先进的NeRF框架之上。为了将该框架扩展到CBCT重建中,我们去掉了原有的重要采样分量,并设计了一种等步推进的光线投射策略,以更好地整合整个空间的信息。最重要的是,为了解决稀疏输入视图数据不足的主要挑战,我们提出了一种新的视图增强策略,该策略基于我们观察到的相邻视图包含丰富的形状和外观信息,提供强正则化来约束中间的新视图更清晰。具体来说,我们设计了一个两阶段的管道。在第一阶段,我们首先训练一个神经衰减场网络,在预定义的中间视点上呈现新的视图图像。然而,这些新颖的视图图像不太可信,因为它们通常是模糊的,几乎没有细节。因此,我们设计了一个去模糊网络,在邻近输入视图的帮助下去模糊这些新的视图图像。然后,在第二阶段,原始输入视图以及去模糊的新视图图像作为输入,进一步微调训练后的神经衰减场。
我们的方法在图像质量方面取得了优异的性能,我们已经进行了大量的实验来证明我们提出的SNAF的有效性。此外,我们提供全面的消融分析,以验证其在不同扫描条件下的稳定性能,并在具有金属伪影的挑战性数据和实际临床应用中展示其卓越的结果。
神经渲染在新视图合成和三维场景重建方面取得了优异的成绩。要在各个方面扩展NeRF[13],效率低下和需要密集的视图是两个主要缺点。许多作品通过更有效的体积表示来加速渲染过程,包括稀疏体素网格[11],八叉树[12]和哈希表[14]。同时,一些方法[3,22,24]被设计为考虑稀疏输入场景。例如,PixelNeRF[22]和SRF[3]从输入视图中提取CNN特征,从而具有使用稀疏输入生成新场景的泛化能力。同时,深度监督通过规范新视图的几何形状和外观,极大地提高了重建精度[7,15]。遗憾的是,它们并不适用于我们的带有神经衰减场的CBCT重建。首先,基于泛化的方法通常设计用于解决跨场景域变化而没有推理优化,其中许多3D重建细节通常会丢失,这对于临床使用是不可接受的。同样,基于深度的正则化在我们的任务中也不实用,因为在我们的透明场景下没有可用的深度或表面信息。在本文中,我们提出了一种新的针对稀疏视图输入的增强策略,该策略是在输入位姿固定模式的衰减场下设计的。
高质量的CBCT重建对于临床应用和下游计算机辅助任务至关重要,例如牙齿和牙槽骨分割[4-6]。滤波反向投影(FBP)[8]是商业CBCT系统中最常用的一种传统方法,通过从给定的2D视图进行反向投影来积累强度,但需要数百个输入视图来防止条纹伪影。这导致高辐射剂量和长扫描时间,促使研究和工业界探索稀疏视图重建[1,21],例如利用正则化来约束重建问题。
近年来,随着神经渲染技术的迅速发展,这一新兴技术被引入到CBCT图像的重建中[17,23]。这两项工作同时提出,采用体绘制快速重建CBCT。然而,NeAT[17]尚未在人体扫描的临床CBCT数据上得到验证,NAF[23]也没有很好地探索高质量图像重建的策略。此外,这两种方法不能解决稀疏视图输入的严峻挑战问题。在这项工作中,我们仅用20个输入视图成功地解决了这个问题,并提供了关于不同扫描条件的重要讨论(例如,输入视图的数量,有限角度和金属伪影),以及下游任务的验证(例如,分割)。
图2展示了我们的两阶段框架的概述,我们首先在第一阶段训练衰减场,然后在第二阶段,借助增强的新视图对训练场进行微调。我们将在下面详细说明技术细节。

图2。我们提出的用于稀疏视图CBCT重建的SNAF概述。给定输入视图(橙色点),我们首先在第一阶段(紫色箭头)用等步光线投射(第3.2节)训练衰减场,这样我们就可以在任何一对输入之间生成几个新的视图(蓝色点)。然后,在第二阶段(红色箭头),我们使用新提出的去模糊网络(第3.3节)去模糊渲染视图。作为回报,增强的新视图(绿点)与输入视图一起作为输入,进一步微调学习到的衰减场。
CBCT扫描。如图1所示,CBCT扫描的配置是非常标准的,其中x射线源沿着平面弧形轨迹绕旋转轴移动,以捕获感兴趣的人体器官(例如牙齿)的二维投影。具体地说,x射线源向感兴趣区域发射一束锥形光束,并设置等心为旋转中心,该旋转中心大致位于感兴趣区域的中心。扫描开始时,x射线源以固定的角度步长从规划的圆弧轨迹起点移动到终点,轨迹平面垂直于旋转轴。例如,它在角度范围内移动[0,210)与角步长10:5◦,这样它将捕获20个2D扫描。注意,这是临床上最常用的扫描构型,表示为20视图,其他构型,如30视图或50视图,可以自然地衍生出不同角度的步进。除非另有说明,本文均采用角度范围[0,210]。每次二维扫描都是发射锥形光束的透视投影,并由对面的平板探测器捕获,反射通过感兴趣区域的透射强度。
CBCT与衰减场。在CBCT成像中,衰减系数描述了通过不同材料吸收的x射线的比例,取决于它们的密度。衰减场与辐射场类似,是本文研究的重点。形式上,我们的目标是学习映射(x;y;z) !µ,即从一个三维点到它的衰减系数。
在第一阶段,受vanilla NeRF[13]和InstantNGP[14]的启发,我们将多分辨率哈希表集成到传统NeRF管道中,并进行了一些特殊调整以适应我们的独特设置,并保留其他核心元素,例如mlp不变。接下来,我们介绍所有关键的改编。
光线投射中的均匀采样。正如在介绍中提到的,真正的体绘制的一个特点是,与近似的表面渲染相比,没有特定的物体。相反,感兴趣区域的整个空间都是信息性的。因此,来自nerf的两次重要采样并不适用于我们的案例,我们希望使用沿所有光线的所有采样点覆盖整个空间。这意味着沿每条射线的采样点放置得尽可能均匀。为此,我们以这种方式设计等步光线投射。
给定所有具有相应相机参数的输入二维扫描,我们首先初始化一个离散的目标体(详细尺度见4.1节),作为衰减场的空间。然后,对于任意扫描中的每个像素点,我们向x射线源发射一条射线r(t) = o + td,使射线两次与体的边界框相交,即入射点o + tmind和出口点o + tmaxd。最后,我们用步长D对tmin和tmax之间的点进行采样。显然,不同的射线可以获得不同数量的内部采样点,并且D与所需的体积间距成比例设置。关于不同D值和抽样策略的详尽评估和讨论,请参见第5.1节。
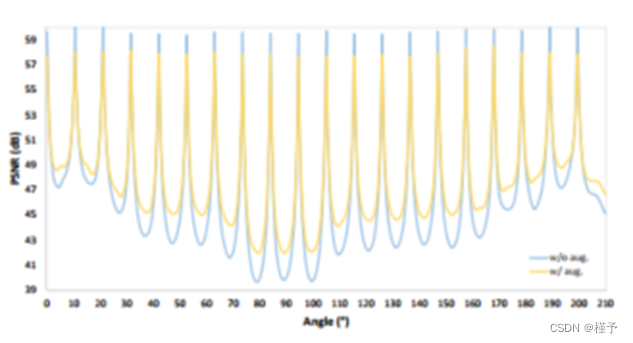
图3。具有/不具有视图增强的新颖视图预测。我们根据PSNR值将沿着捕获轨迹生成的新视图可视化。很明显,在输入和新视图之间存在显著的退化。我们的视角增强策略显著缩小了差距。注意这里,去模糊发生在山谷。
体积渲染。对于每次二维扫描,x射线源发射具有初始强度的锥形光束,该光束通过每条射线遇到的不同组织衰减,最后由平板探测器接收,形成所有逐像素的强度值。这种呈现过程通常用比尔-朗伯定律来表述:

式中,I为可从二维扫描中读取的透射强度,I0为入射强度,µ为衰减系数,δ为采样推进步长。
在本文中,我们利用Eq. 1从衰减场生成渲染(即传输)图像Ipred,最后通过均方误差最小化来学习神经衰减场:
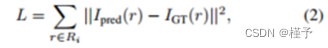
其中Ri和IGT分别表示射线和地面真值强度的集合。
总的来说,我们遵循类似的训练策略来学习衰减场。由于采用哈希编码,可以快速获得学习到的衰减场,并且质量较好,最后通过均匀网格采样得到重建的三维体。
尽管第一阶段学习到的衰减场可以产生质量不错的CBCT图像,但由于输入视图有限,数据不足,导致图像严重模糊,如图5所示。同时,如2.1节所述,解决神经渲染中稀疏视图挑战的现有技术并不适用,因此,我们根据CBCT扫描过程(3.1节)中介绍的观察结果设计了新的视图增强方案。
具体来说,我们首先沿着扫描轨迹呈现一组新的视图,并根据PSNR对图像质量进行量化,如图3紫色线所示,其中我们发现,在任何连续输入视图(见山谷)之间的新视图中,由于模糊(图5),图像质量急剧下降。因此,一个简单有效的想法是对中间的新视图进行去模糊处理,以提高目标衰减场的质量。
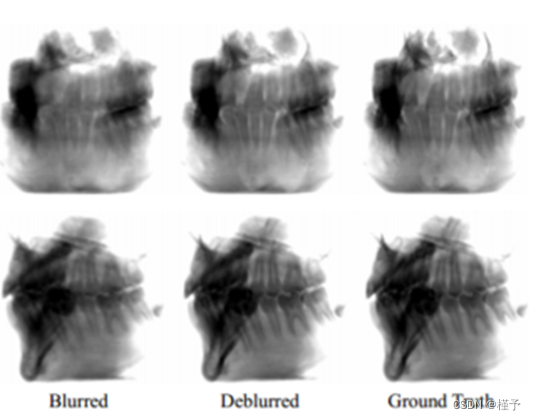
图5。消融去除模糊的研究。我们在(直接渲染,第一列)和去模糊(第二列)之前可视化了两个典型的2D视图示例。去模糊网络极大地增强了与地面真实相媲美的清晰边界和细节(第三列)。
由模糊变清晰的网络。由于CBCT扫描的独特配置,相邻视图具有较强的外观相似性,包含丰富的尖锐特征。为了直接使用来自输入视图的图像先验并保持感兴趣区域的几何一致性,我们因此设计了一个去模糊网络,该网络将第一阶段从学习的神经衰减场中呈现的新视图作为输入,以及通过图像拼接的左邻右邻视图。目标是将模糊的视图映射到具有精细细节的高质量对应视图。
数据准备和培训。为了训练去模糊网络,我们构建了一个来自不同患者的成对四组数据集。具体来说,我们收集了30名患者的数据,对于每个患者的数据,我们按照第一阶段的描述训练衰减场。然后,我们为任何相邻的输入视图illeft和right生成一个中间的new视图Inew。相应的基真观Igt,与上述三种观一起形成成对的四重观fIleft;Inew;Iright;用于训练网络的Igtg。该网络具有具有附加注意机制的UNet结构[16][10,20],并预先进行预训练。详细的网络结构请参见补充资料。
有了预训练的去模糊网络,在第二阶段,我们首先对新视图进行去模糊处理,然后将去模糊的视图以及原始输入视图发送到神经网络,对学习到的衰减场进行微调。这里需要注意的是,泛化能力来自于对于不同的患者,CBCT扫描过程会对共同感兴趣的区域产生具有相似空间和强度范围的CBCT图像。我们在第4.3节中彻底验证了该策略。
在我们的实验中,我们采用牙科数据集来验证我们提出的框架的优势。为我们的数据集,三维CBCT图像的分辨率为401×401× 401,体素间距为0:2 × 0:2 × 0:2 mm,我们的合成2D投影为404×404,间距为0:278× 0:278 mm。为了合成二维投影,我们按照公式1 (I0 = 1:0)进行体绘制,并模拟不同角度范围和角度步进的扫描过程。并且,对于光线投射中的每条射线,采用固定的D = 0:1mm(即CBCT间隔的一半),通过三线性插值计算每个采样点的衰减值。
在我们的框架中,多分辨率哈希表编码器和mlp是两个至关重要的学习模块神经衰减场。对于哈希表编码器,我们采用[14]的官方实现,其中将核心参数设置为适合我们设置的特定值,包括大小T = 219,分辨率级别数L = 12,特征维度F = 8。通过实验,我们观察到F在学习衰减场中起着更为重要的作用。因为,与自然场景中主要代表物体表面的神经辐射场不同,我们的神经衰减场更复杂,并且在整个场景中具有许多解剖细节的信息。因此,神经衰减场需要更大尺寸的特征,我们所有的实验都使用F = 8。对于完全连接的层,我们使用带有ReLU的紧凑的3层64通道MLP从哈希表中学习多分辨率特征。
训练。对于训练网络,使用Adam优化器,初始学习率为1e-3,并呈指数衰减。我们首先用四个Nvidia A100 GPU卡对去模糊网络进行4小时的预训练。然后,我们用一块Nvidia A100 GPU卡在第一阶段训练20分钟,在第二阶段训练10分钟,以学习和微调衰减场。
为了验证我们的方法的优势,我们将我们的SNAF与学习方法和非学习方法进行了比较,包括滤波反向投影(FBP)[8],同步代数重建(SART)[1],以及最近流行的三种神经渲染解决方案[13,17,23]。其中,FBP和SART是目前商用CBCT系统中仍然常用的两种传统方法,其中FBP具有较高的效率,而SART主要用于稀疏视图CBCT重建。神经渲染方法neural Radiance Fields (NeRF)[13]主要用于自然场景的新视图合成,我们对其进行了轻微修改,去掉了其颜色预测分支。此外,我们还比较了两种并行的神经体绘制方法,神经自适应断层扫描(NeAT)[17]和神经衰减场(NAF)[23],这两种方法专门用于具有最佳状态性能的CBCT重建。出于消融的目的,我们提出了SNAF的一种变体,通过去除视图增强,记为SNAF (w/o aug)。实验以不同数量的输入视图(即20、30、40和50个视图)进行。需要注意的是,20视图极为稀疏,通常比临床收集的少25倍。
定性地,典型的例子如图4所示,从中可以很容易地观察到,我们提出的方法优于所有竞争的方法,以更多的细节和更少的噪声重建CBCT图像。具体来说,由于FBP仅在足够的视图(例如,商业CBCT系统中的500个视图)下表现良好,因此它在50个输入视图下产生许多工件,并且当视图数减少时显着下降。另一种传统方法SART在一定程度上解决了稀疏视图问题;然而,它极大地交换了重建细节和一个过度平滑的问题,许多牙齿细节,特别是在20个输入视图上,丢失了。对于三种神经渲染方法(即NeRF、NeAT和NAF), NeRF产生的伪像比专门为CBCT重建设计的变体(即NeAT和NAF)要少。不幸的是,由于其全局优化机制(即没有局部特征嵌入),局部强度对比(例如牙齿内部)无法准确重建。相比之下,SNAF (w/o aug)已经超越了所有其他方法,提供了高质量的视觉结果,而SNAF (ours)通过新颖的视图增强进一步提高了质量,提供了更精细的细节。图5中显示了一个单独的视觉示例,以更好地说明差异,这反过来验证了我们的新视图增强策略的有效性。
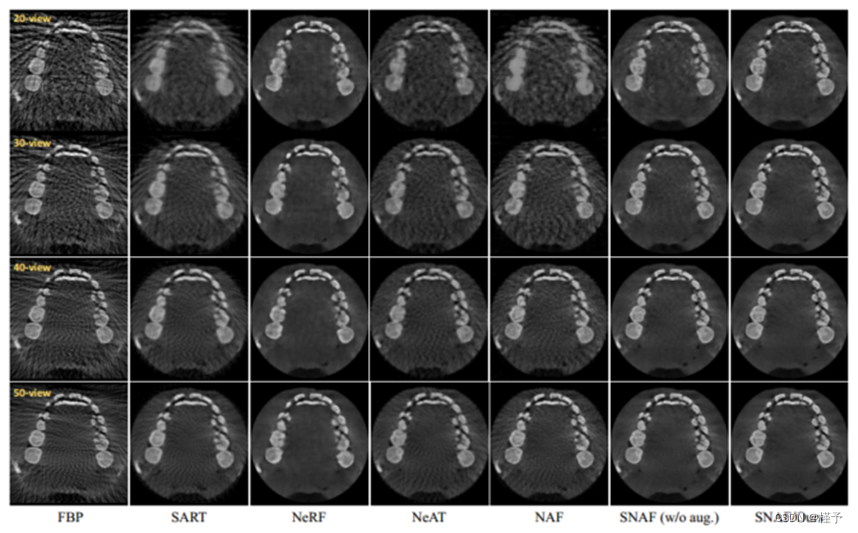
图4。不同方法的定性比较。我们比较了不同输入视图(每一行)下CBCT重建的性能,并通过不同方法(每一列)对重建的三维体切片进行了可视化。我们的重建质量大大优于所有其他方法。参考图1(轴向切片)的地面真实情况。
定量地,表1给出了PSNR和SSIM指标来衡量重建质量。与这些方法相比,我们的框架在不同数量的输入视图下实现了领先的性能。一个有趣的观察是,SNAF (w/o . 8)在20个输入视图上运行,甚至优于其他50个输入视图的方法,除了NeRF (31.98 dB的PSNR)。此外,受益于新视图论证,我们的重建精度在我们的稀疏视图设置下持续提高(20视图和50视图的PSNR分别提高1.07 dB和0.69 dB),表明去模糊网络可以进一步增强新视图,从而微调学习到的衰减场。
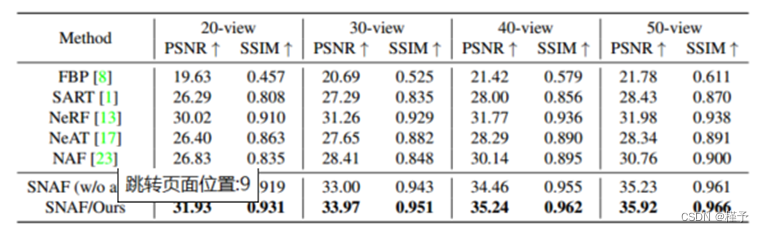
表1。不同方法的定量比较。我们使用不同视图配置下的PSNR和SSIM指标对不同方法重建的三维CBCT体积的质量进行量化。我们的方法在所有配置的两个指标上都取得了最好的结果。特别是,我们的方法只有20个视图,优于其他所有50个视图。
运行时间。FBP是一种有效的方法1分钟内构建三维CBCT体积。从20到50的输入视图通常需要4-12分钟。然而,对于基于神经渲染的方法,NeRF是一个全局优化,需要更多的训练时间(即使用我们的数据集大约90分钟),它的所有变体(NeAT, NAF和我们的SNAF)都是建立在局部特征编码上的,在A100 GPU上大约需要30分钟。
我们进行了大量的烧蚀和其他实验,以讨论技术细节(即,点采样策略),我们的方法在不同扫描条件下的性能(即,扫描范围),具有挑战性的金属工件的性能,以及下游牙科应用。在本节中,我们的默认输入视图号是20。更多讨论请参考补充资料。
采样策略在学习衰减领域中是至关重要的。在我们的SNAF中,我们采用了步长为D的简单均匀抽样策略,尽管分层抽样是另一种解决方案。在这个实验中,我们验证了我们的选择。
改变前进步长D。很明显,更大的D意味着沿着一条射线的采样点更少。由于点较少,它往往不能很好地覆盖整个空间,但却大大简化了计算。从表2可以看出,当我们将D从0:2mm增加到0:8mm时,可以观察到边际性能下降(30.86 vs。30.63 (PSNR)),而只需要不到1/3的训练时间。图6中的可视化示例也验证了这一点。因此,为了权衡训练时间和重建质量,我们可以适当忠实地放大步长D,我们的算法中采用D = 0:2mm首先保证重建质量。
均匀抽样与分层抽样。通过与可选的随D值增加的分层抽样方案进行比较,我们验证了均匀抽样是我们衰减场学习的最佳拟合方案。从表2和图6可以看出,当我们使用较小的D时,均匀抽样与分层抽样是同等的。然而,大的D,例如1:6mm,将带来明显的伪影和显著的PSNR下降(即29.73 vs. 28.95)。原因是,首先,我们的最终目标是通过网格采样获得离散表示(即3D体积),而不是用于生成新视图的完全连续的辐射场。保持一个固定的采样步长来捕获这个明确的3D体积是合理的。其次,均匀采样允许沿射线的总变化损失的积分,避免条纹伪影。相反,分层抽样引入的随机性不能产生均匀分布在体积内的样本点。因此,均匀采样是学习神经衰减领域的最佳采样策略。
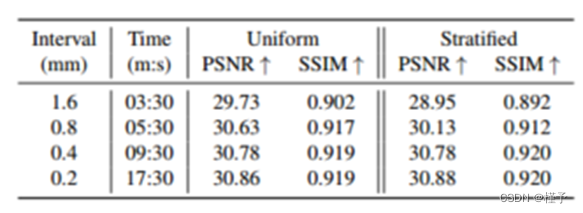
表2。不同步进的影像评价。在20视图扫描和0.2 mm的三维间隔条件下,我们改变了等步采样方案的采样步长。我们报告了重建体的PSNR和SSIM的成像质量。
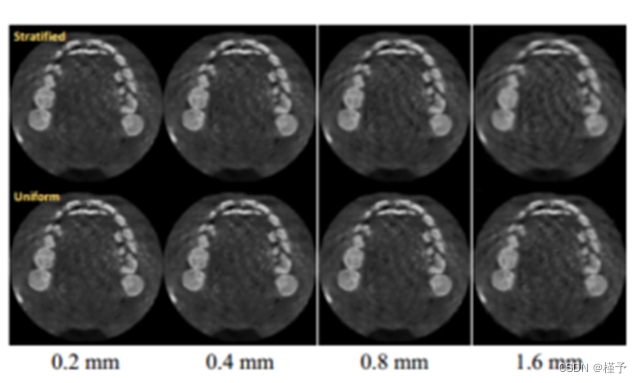
图6。不同步进取样策略的视觉比较。
扫描范围是通过弧度轨迹上的旋转角度来测量的,可以灵活变化,例如180度,210度(短扫描)或360度(全扫描)。在相同的辐射剂量(即相同的扫描视图数)下,更大的距离可以增加视图覆盖率,但扫描时间明显增加。在本实验中,我们打算在稀疏视图设置中确定最佳扫描范围,以权衡扫描时间和重建质量。从表3可以看出,小于150◦的扫描范围会导致明显的性能下降,而从180◦到360◦的扫描范围,性能的提升是微妙的。因此,我们认为推荐210◦作为我们所有实验中最好的扫描范围,这也与临床实践中捕获密集视图时的选择一致。
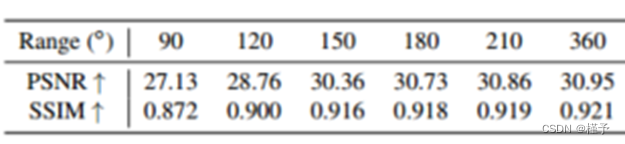
表3。不同范围的影像评价。我们从扫描轨迹的增加5.3. 金属制品实验范围内采样了20个视图,并报告了重建CBCT体积的PSNR和SSIM指标。
金属伪影是CBCT长期存在的问题,主要是由金属植入物等金属材料引起的。在本实验中,我们证明了学习的神经衰减场可以显著地消除金属伪影。具体来说,我们首先选择一个干净的没有任何伪影的3D CBCT体积,然后通过将牙齿变成金属来模拟金属种植体,即分配一个大的衰减值,如图7的最后一列所示。我们使用20视图配置生成该合成CBCT体的20个视图,并比较FBP, SART和我们的重建结果。
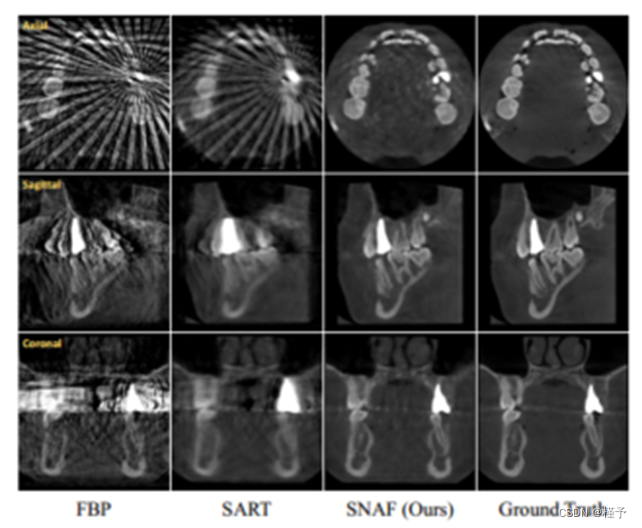
图7。视觉结果与金属工件。我们通过将合成金属放入干净的地面真值(最后一列)CBCT卷中来合成带有金属的输入视图。给定这样的输入,我们的SNAF可以忠实地消除几乎所有的金属伪影,而替代方法(即第一列和第二列的FBP和SART)遭受严重的条纹伪影。
在图7中,我们发现FBP产生了明亮的条纹伪影,并重建了不可用的结果。尽管SART设法通过平滑来缓解这些伪影,但仍然无法阻止退化。通过对比,我们的方法通过学习神经衰减场重建出高质量的CBCT图像,其中金属区域附近的边界更加清晰。主要原因是,其他方法强迫从给定视图通过反向投影来积累透射强度,从而用受影响的透射强度污染重建。相反,神经衰减场可以忠实地计算任何采样点的衰减系数,无论它们是否为金属。
我们的SNAF目标是具有稀疏输入视图的高质量CBCT重建。为了验证我们的结果可以用于真实的诊所,我们直接对重建的CBCT图像进行牙齿语义分割[5]。示例分割结果如图8所示,其中所有牙齿都从20视图和50视图结果中成功分割。尽管由于重建的CBCT图像中信号模糊,导致磨牙的牙根不完整,但即使只有20个视图,大多数牙齿也可以被忠实地识别和分割。
尽管SNAF仅提供20个视图的高质量CBCT重建,但当输入数据极其不足(例如,10个视图)时,它可能会失败。我们计划在未来的工作中将生成网络与神经衰减场相结合,以解决这一重大挑战。此外,我们在任何连续输入视图之间产生一个新的视图,而不是根据重建质量自适应地选择新的视图。从图3中观察到,PSNR分布的山谷对应于高斯分布,因为正面视图包含比侧面视图更多的信息,并且应该在这些位置周围放置更多的视图。幸运的是,高斯分布可以作为一个密度函数来指导未来高级自适应新视图的生成。
本文提出了一种利用神经衰减场学习从稀疏视图重构CBCT的新方法SNAF。针对数据不足带来的巨大挑战,提出了一种新的视图增强方案。大量的结果和实验验证了我们的结果的高质量。我们相信神经衰减领域有希望在其他医学图像处理任务中发挥作用,为未来的CBCT扫描系统提供潜力。
























 1776
1776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









