






初学者,个人学习,可能有错误。
首先,D-FINE基于DETR结构,也就是backbone->encoder->decoder形式
为什么会有这篇论文的提出?要从两个issue说起
issue 1: bbox回归任务默认bbox边界是个准确值,符合狄拉克delta分布。但实际中,边界有时候不准确,比如模糊,遮挡。此时bbox任务再用IoU loss和 L1 loss效果就不好了。同时bbox回归又对坐标很敏感,可能一些case下,bbox回归不好,收敛慢,收敛效果差。
issue 2: speed和(计算复杂度,参数量-带宽)间的制约关系。蒸馏可以不增加cost提升speed,但KD在检测任务效果不好。LD在检测任务效果好。但是LD 在anchor-free下不好做。
- D-FINE思路:将 bbox固定位置回归任务 变成 概率分布的预测任务
- 方法:FDR和GO-LSD
1)FDR 实现了 思路 , 并提供一个 细粒度的中间表示,也就是概率分布,这个中间表示可以提高定位精度。FDR以残差形式迭代优化概率分布。
2)GO-LSD是一个双向的优化策略。这里就是说 自蒸馏。 (DETR没有anchor, LD不好弄,所以做LSD)
通常我们是将浅层特征前向传播,之前的residual block也是浅层传递到深层,提供高分辨率信息。
但是GO-LSD将深层特征,也就是学习到的精细的bbox分布传给浅层,使浅层向深层看齐。这样有一个连锁效应,就是浅层学的更好了,深层预测更简单了,模型收敛更快了。
D-FINE有了1)和2)两个法宝,相同复杂度模型的精度肯定更好了。
D-FINE进一步对计算密集的module做了costdown, speed 更好。
FDR
FDR是在decoder中做的,D-FINE不同大小的模型有不同的deocder layers, 比如-n和-s有3个decoder layers
其中,decoder layer1经过一个bbox回归head(MLP), 预测初始的bbox ,同时,decoder layer1经过一个D-FINE head(MLP)预测 bbox的概率分布, 每1个bbox对应4个概率分布,即4条边的概率分布。
1)decoder如何预测概率分布
把decoder layer1预测的初始bbox记为:
![]()
因为要预测概率分布,那肯定要关注到每条边,所以作者这里把xywh转成了xy{t,b,l,r},中心点和它到四条边(依次是top, bottom, left, right)的距离。
decoder layer1的{t,b,l,r}记为
![]()
后续第个decoder layer的中心点到边缘距离为
![]()
每一个decoder layer经过一个D-FINE head 给出,和上一个decoder layer的logits加和并过softmax得到概率分布(针对
)
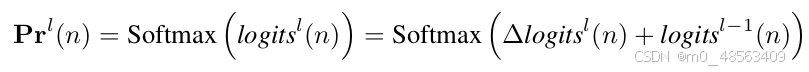
前面提到decoder layer1也会预测一个概率分布,但是时就不能用上面的公式计算了,采取如下公式:

2)如何修改优化初始bbox
decoder layer 1预测的bbox作为参考bbox, 后续的decoder layers 以残差的形式迭代优化bbox的边的概率分布,从而迭代优化decoder layer1 预测的bbox。
和
的关系为:
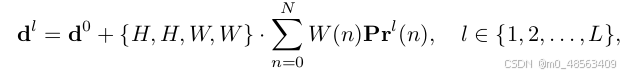
看到这个公式,首先可以粗浅理解为 一个非均匀权重W * 一个离散概率分布p * bbox的大小 作为残差去优化, 得到
。
代表的四条边相比初始bbx更贴近groud-truth.
每个边有一个概率分布p, 它代表的哪个物理量的概率分布?论文提到是p预测了可能的offset的可能性。也就是对于p的概率曲线,横坐标是offset, 比如是t的一系列可能值,共n个点,每个点有对应的权重w_n。 p的加权和即edge offset。这个offset可能没有尺度信息,所以*初始bbox的H和W(scale), 以适应尺寸。
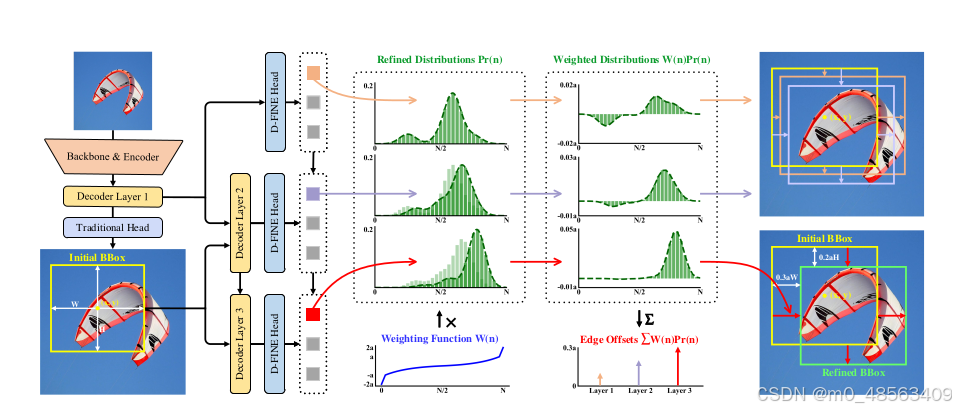
图片左侧,就是得到初始bbox,同时decoder layer1 会送入D-FINE head得到一个概率分布,这里叫它p1, 然后decoder layer1会传给decoder layer2, 再经过一个D-FINE head得到概率分布p2, 然后decoder layer2还会传给decoder layer3, 经过一个D-FINE head得到p3.
前面提到,w*p*scale是残差项,图上有初始的p和w*p. 其中,p1有两个positive的peak,w*p1分别有一个negative的peak和positive的peak, w*p1曲线下的面积为pos_p1, 对应图片右侧橙色线条的offset,p2和p3分别对应紫色和红色的offset,不断的优化目标。
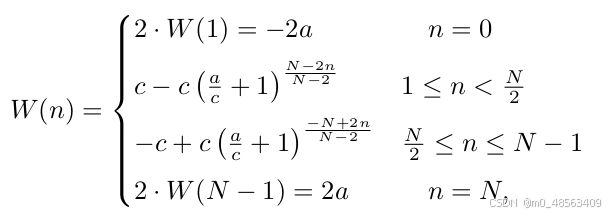
a和c是超参数,分别控制W(n)曲线上界,曲率。
当bbox接近ground-truth的时候,W(n)曲率小, 残差小,可以精细化调整。
相反,如果bbox离ground-truth还很远,靠近边界的曲率大,可以给出更大的校正。
曲线的曲率是什么?曲率描述曲线在某一点的弯曲程度,如下图,1/x0的曲率圆半径=x0点的曲率。
为了训练优化p, 受Distribution Focal loss(DFL)的启发,作者提出了FGL loss
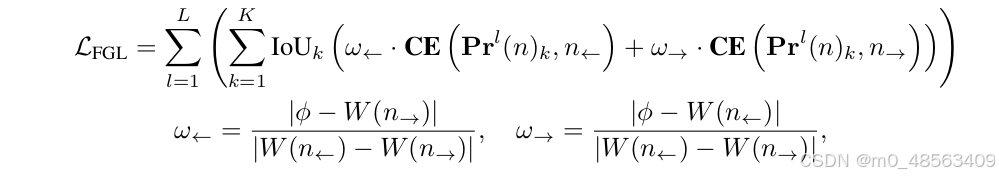
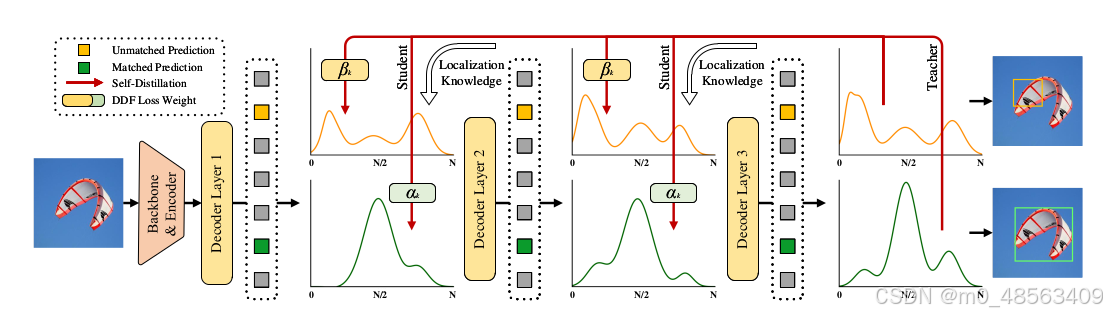
GO-LSD
GO-LSD 蒸馏 最后一层的定位知识给前面每一层。
蒸馏损失是浅层和最后一层的KL散度loss
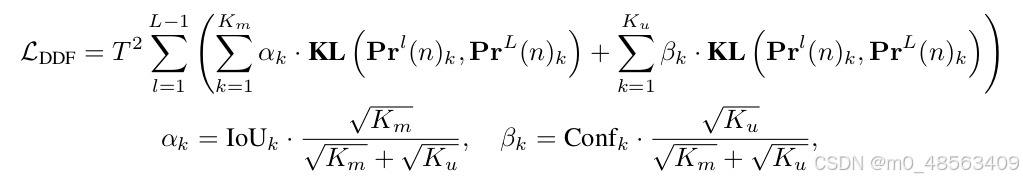

















 1292
1292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









