






个人理解,可能有错误。
主要关注D-FINE-N,相关的源码为:
dfine_hgnetv2_n_coco.yml
dfine.py
hgnetv2.py
hybrid_encoder.py
dfine_decoder.py
D-FINE-N的yaml文件给出了网络config, 包括backbone用HgNetv2,backbone用‘B0’架构的参数,encoder用HybridEncoder, decoder用D-FINE自己的transformer,以及optimizer, train, val的设置。
Backbone部分
- HGNetv2
Encoder部分
- CSPNet
- ELAN
- RepNCSP
- RepNCSPELAN4
- HybridEncoder
Decoder部分
- Integral
- TransformerDecoderLayer
- MSDeformableAttention
- TransformerDecoder
- DFINETransformer
下面说内容以input_shape为(1, 3, 320, 320)展开,需要将dataloader.yml和dfine_hgnetv2.yml中进行修改。注意在D-FINE的代码中,如果-n.yml没有改对应参数,都会默认使用dfine_hgnetv2.yml中的参数。
一、Backbone
dine-n中,backbone用的是hgnetv2,由1个stemblock和4个stage组成。4个stage对应4个特征提取模块。backbone只传递最后两个stage的feature map 进入encoder, 对应dfine_hgnetv2_n_coco.yml中的return_idx:[2,3], 这两个特征图的shape分别是(1,512,20,20)和(1,1024,10,10。
二、Encoder
这部分建议看大佬博客RT-DETR 详解之 Efficient Hybrid Encoder_hybridencoder-CSDN博客
encoder用的是hybrid encoder, 来自RT-DETR, 如下图。
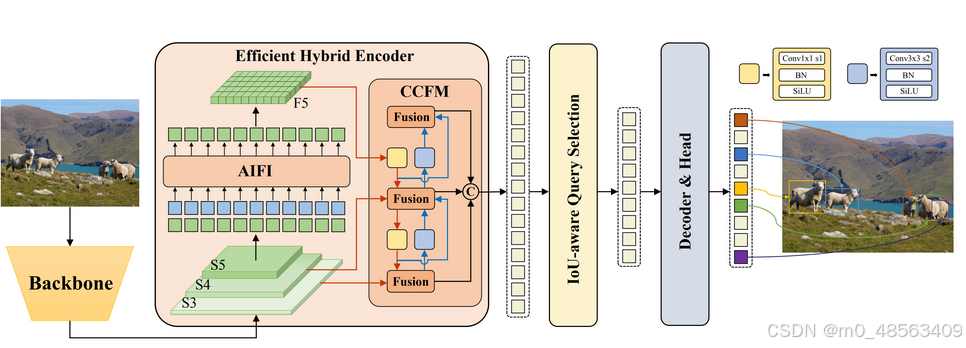
总体设计
RT-DETR希望像Deformable-DETR一样获取多尺度特征,但是RT-DETR认为不是所有的feature map都需要计算自注意力。在D-FINE-n中,只将stage4的特征图Token化并计算自注意力,同时自注意力只有一层encoder layer。为方便表述,将stage3, stage4的feature map记为C3、C4,C3的shape为(1, 512, 20, 20), C4的shape为(1, 1024, 10, 10)。在D-FINE-n中,通过conv对C3进行特征提取,然后与C4经过encoder layer输出的feature map(记为F4)进行尺度间特征融合(CCFM), 从而获取多尺度特征,同时大幅减少计算量。
计算细节
def forward(self, feats):
assert len(feats) == len(self.in_channels)
proj_feats = [self.input_proj[i](feat) for i, feat in enumerate(feats)]
# encoder
if self.num_encoder_layers > 0: #encoder_layers=1
for i, enc_ind in enumerate(self.use_encoder_idx):
h, w = proj_feats[enc_ind].shape[2:]
# flatten [B, C, H, W] to [B, HxW, C]
src_flatten = proj_feats[enc_ind].flatten(2).permute(0, 2, 1)
if self.training or self.eval_spatial_size is None:
pos_embed = self.build_2d_sincos_position_embedding(
w, h, self.hidden_dim, self.pe_temperature).to(src_flatten.device)
else:
pos_embed = getattr(self, f'pos_embed{enc_ind}', None).to(src_flatten.device)
memory :torch.Tensor = self.encoder[i](src_flatten, pos_embed=pos_embed)
proj_feats[enc_ind] = memory.permute(0, 2, 1).reshape(-1, self.hidden_dim, h, w).contiguous()
# broadcasting and fusion
inner_outs = [proj_feats[-1]]
for idx in range(len(self.in_channels) - 1, 0, -1):
feat_heigh = inner_outs[0]
feat_low = proj_feats[idx - 1]
feat_heigh = self.lateral_convs[len(self.in_channels) - 1 - idx](feat_heigh)
inner_outs[0] = feat_heigh
upsample_feat = F.interpolate(feat_heigh, scale_factor=2., mode='nearest')
inner_out = self.fpn_blocks[len(self.in_channels)-1-idx](torch.concat([upsample_feat, feat_low], dim=1))
inner_outs.insert(0, inner_out)
outs = [inner_outs[0]]
for idx in range(len(self.in_channels) - 1):
feat_low = outs[-1]
feat_height = inner_outs[idx + 1]
downsample_feat = self.downsample_convs[idx](feat_low)
out = self.pan_blocks[idx](torch.concat([downsample_feat, feat_height], dim=1))
outs.append(out)
return outs1)进入encoder前,C3、C4都要先经过一个kenel为1的conv,转换feature map的channel为128(对应yml文件的hidden_dim),得到C3_128, C4_128
2)对C4_128进行维度变换得到拉成一维的特征(H, W)->H*W,(1, 128, 10, 10)->(1, 100, 128),得到src_flatten, 将其送入encoder
3)计算C4_128的位置编码,对应于hybrid_encoder.py中的build_2d_sincos_position_embedding, 注意到这个函数会传入w和h参数,对应C4_128的h和w。embedding的长度和C4_128的channel一样,pos_embed的shape是(1,100,128),送入encoder
位置编码推荐看知乎大佬猛猿写的分析
4)在encoder中完成多头自注意力计算。 这里是送入了TransformerEncoder类,它里面只有一层TransformerEncoderLayer。把src_flatten和pos_embed相加,结果作为q和k,然后计算q和k的自注意力,自注意力本质是matmul, 自注意力的计算结果的shape和q、k的shape一样,是(1, 100, 128),之后和src_flatten(shape=(1, 100, 128))相加。然后做norm, 过FFN。注意这个过程中有两次shortcut
经过上述操作,我们得到了一个(1, 100, 128)的output, 作为memory变量, 然后memory又被reshape为nchw,即(1,128,10,10), 记为feat_heigh,替换C4。其实这里的feat_heigh就是F4了。
5)多尺度特征融合。在多尺度特征融合中,我们的输入其实是C3_128、C4_128、F4。
FPN: C3_128, F4
首先对F4做以下操作 i)fusion,融合conv和BN,得到F4_fuse,shape是(1,128,10,10); 2)nearest上采样,scale=2, shape变成(1,128,20,20)得到upsample_feat。然后将C3_128和upsample_feat做concate之后送入fpn,得到的输出为inner_out, shape为(1,128,20,20),记为C3_fpn。
PAN: C3_fpn, F4_fuse
对C3_fpn通过conv做下采样,得到shape(1,128,10,10)的downsample_feat,然后将它和feat_height concate送入PAN,得到一个shape为(1,128,10,10)的output。
把FPN和PAN的output作为encoder的输出。FPN和PAN block都是用的RepNCSPELAN4,到这里encoder就结束了,之后送入decoder, 输出2路,分别是logits和boxes, logits的shape是(1,300,80),box的shape是(1,300,4),这里的300对应dfine_hgnetv2.yml里面的num_top_queries:300

















 2643
2643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









