







前言
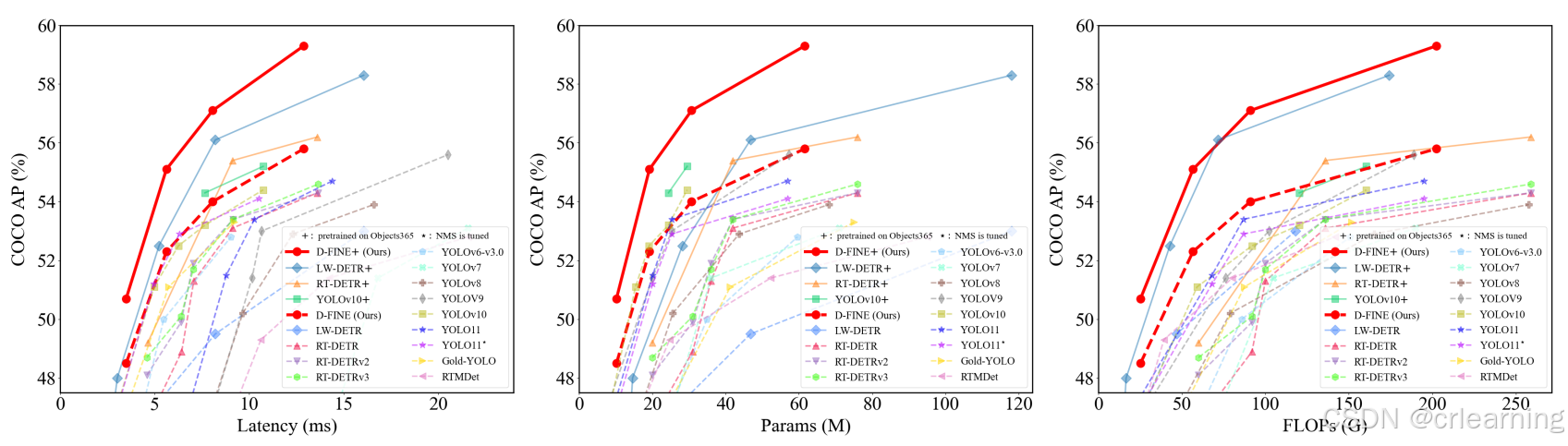
超越YOLOv11和RT-DETRv3的最新模型D-FINE,基于RT-DETR基线代码进行优化。从图中可观察到,不论是从推理速度、模型参数量、模型计算量,均超过了主流的目标检测模型。
论文地址:https://arxiv.org/pdf/2410.13842
代码地址:https://github.com/Peterande/D-FINE
本文主要分析该文章提出的创新点,及其为什么work。
主要创新点
论文主要提出两个点 FDR (Fine-grained Distribution Refinement) 细粒度分布优化和GO-LSD (Global Optimal Localization Self-Distillation)全局最优定位自蒸馏机制
1、FDR细粒度分布优化
what:
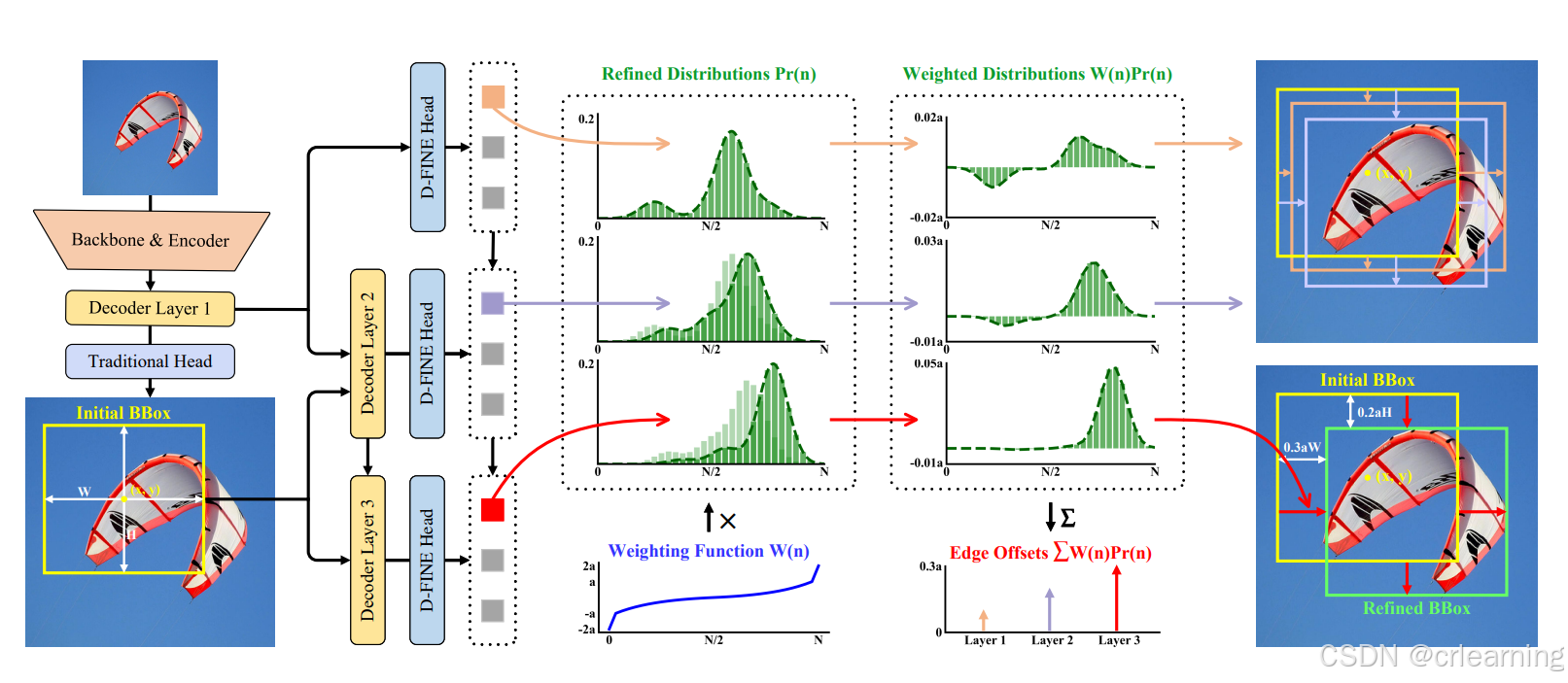
D-FINE是在RT-DETR结构的基础上进行优化,FDR(Fine-grained Distribution Refinement)通过细化概率分布的方式逐层优化边界框定位,被集成到RT-DETR框架中,增强对物体边界细致定位能力。
步骤分为以下4部分:
1、初始解码层:在最初的解码器层Layer1,模型生成初始的边界框坐标预测,并通过FDR模块(D-FINE Head)生成每个边界(上下左右)的概率分布。
2、逐层细化:在后续的解码器层中,每层都会基于上一层的预测分布进一步优化边界框分布。通过这种逐层迭代,模型在每层都逐渐缩小边界不确定性,以此实现越来越精确的定位。。其中FDR采用残差更新的方式进行细化概率分布。
假设上一层生成的概率分布为 ,则当前层输出的是残差
。这些残差叠加到上一层的分布上,得到当前层更新的概率分布
。
通过Softmax将叠加后的分布转换成概率,从而得到新的细化分布。通过这种层层叠加的方式,分布逐步收敛到精确的边界位置。
3、非均匀加权函数的应用
权重函数 W(n)让模型对接近真实位置的偏移值进行更小的调整,而对远离真实位置的边界偏移赋予更大的权重。这种设计可以确保模型在接近目标边界时逐渐细化边界框,而在边界预测有偏差时进行较大调整。
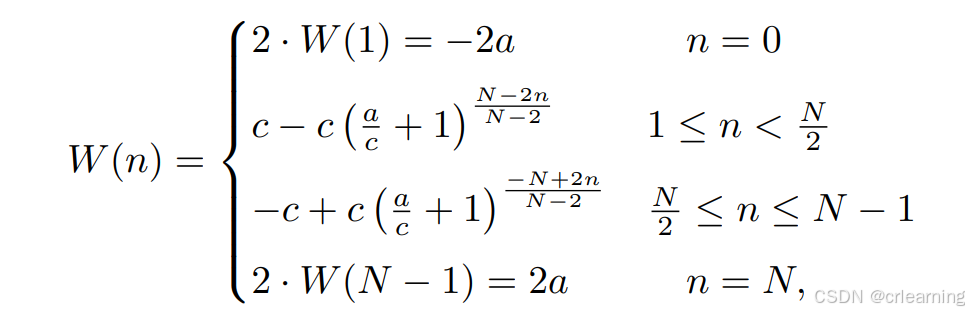
why work:
目前主流的目标检测都是基于预测框和目标框的IOU以及中心点边距distance来约束,但是这种distance强约束并不适合模糊目标,如遮挡物体(边界线位置是未知的,但回归是已知)。作者提采用概率分布的形式,为了更好地表示边界框预测中的位置不确定性。
传统的边界框回归方法通常直接预测边界框的固定坐标(如 (x,y,w,h)(x, y, w, h)(x,y,w,h) 或边距 (t,b,l,r)(t, b, l, r)(t,b,l,r)),把这些坐标当作确定值(即“确定性”预测)。然而,在实际应用中,物体边界往往并非完全明确,尤其是在以下场景中:
- 物体边缘模糊或部分遮挡
- 场景中存在复杂的光影变化
- 目标和背景之间的界限模糊
在这种情况下,单一确定的坐标预测无法表示边界的不确定性(它假设每个边界坐标都是完全确定的值,忽略真实标注就带有模糊性),即无法区分预测结果的置信度和精确性。
概率分布如何解决位置不确定性
FDR通过预测边界框边缘的概率分布,而不是直接输出固定坐标值,来增强模型对位置不确定性的表达能力。每个边界的概率分布表示预测边界可能落在的范围及其置信度高低,这样做有以下优势:
- 表达不确定性:通过概率分布,模型可以在一个范围内给出可能的边界位置,从而自然地表示出不确定性。模型不再需要强制预测一个单一确定值,而是可以通过概率峰值和分布形状来表达边界可能的多样性。
- 逐步细化边界框:通过FDR在每一层对分布的残差更新,模型可以逐层调整边界框,逐步收敛到更精确的位置。这种方法既保证了预测的精度,又能提高模型在复杂场景中的适应性。
- 抗噪性增强:由于概率分布可以缓解单点预测的波动,模型可以在更多场景下给出更稳定的结果,减少噪声干扰的影响。
how效果如何:
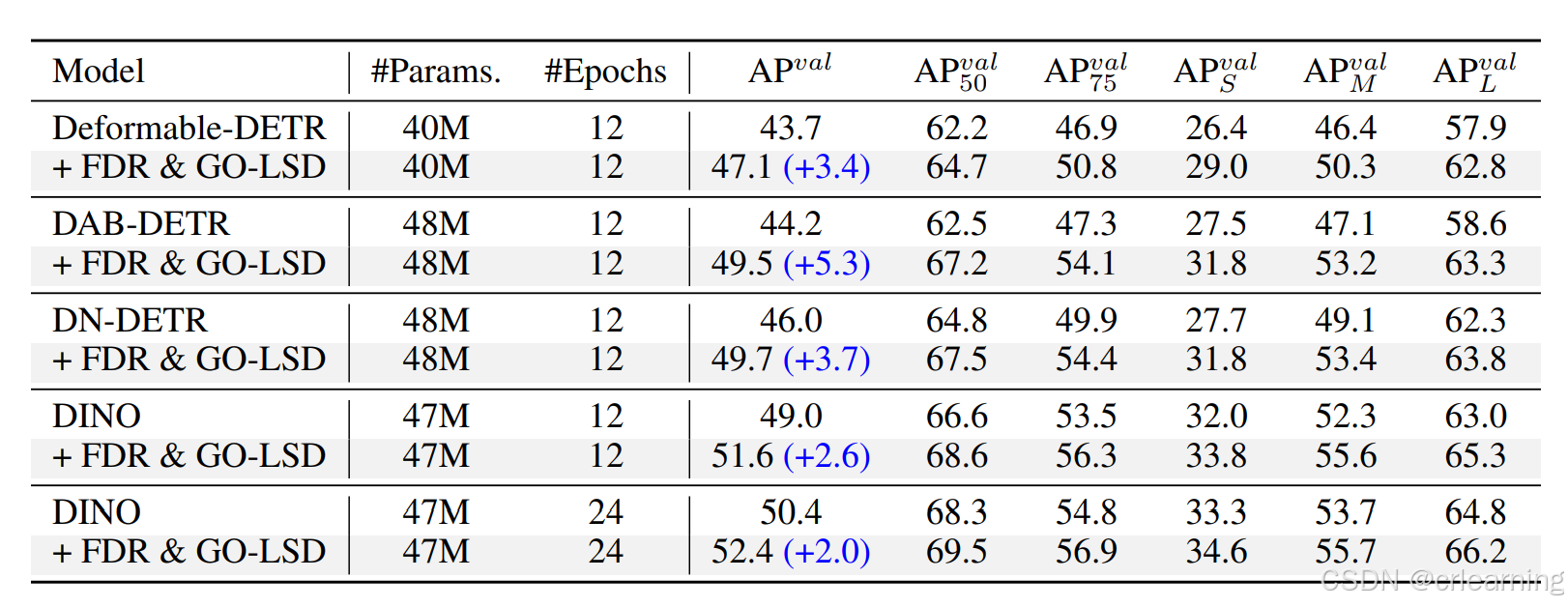
作者在coco数据集上进行实验,结果如下:呈正向
2、GO-LSD全局最优定位自蒸馏机制
GO-LSD是一种新颖的自蒸馏方法,通过将深层的精细定位知识传递给浅层,实现全局最优的定位优化。它的工作原理相对来说较为简单:
- 双向优化:利用最终层输出的精细分布来指导浅层预测,使得浅层能更早调整边界框位置,提升整体预测精度。
- 解耦权重策略(DDF):GO-LSD对匹配的高IoU和低置信度的预测应用不同权重,以更有效地进行蒸馏,提高了模型的稳定性和性能。
简单来说,GO-LSD将最后一层的结果与浅层计算KL散度(类似计算loss),将深层的准确性传递到浅层,帮助模型在训练过程中尽早学习到更高质量的定位信息,从而加快收敛速度。此方法不仅减少了训练成本,还优化了模型对复杂场景的适应能力,例如多对象密集场景和光线变化条件下的检测。
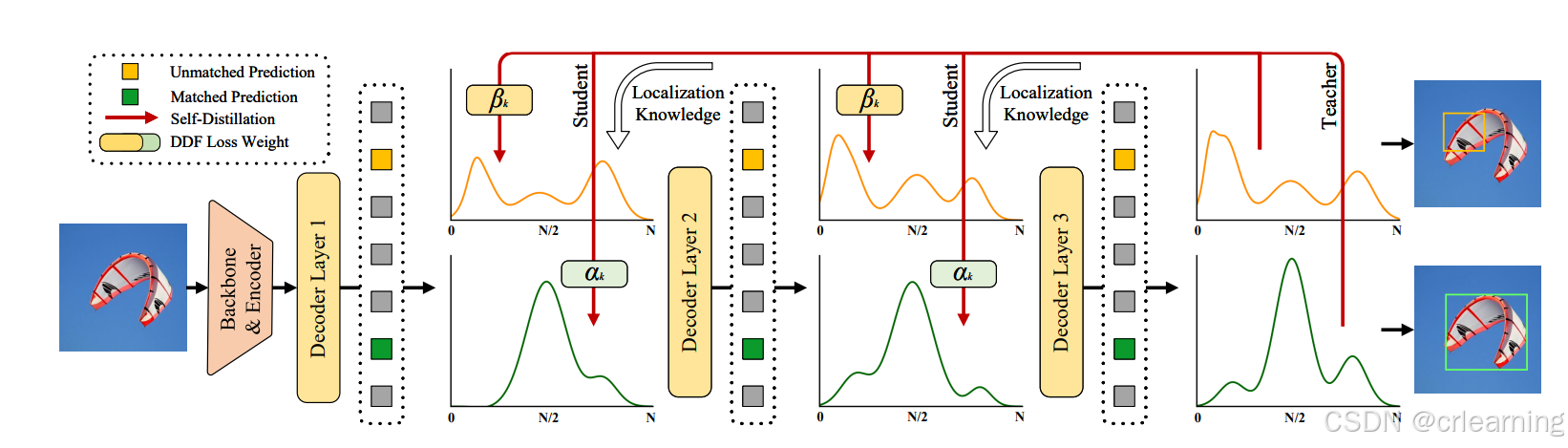
值得注意的是:为什么使用最后一层的预测结果,不直接使用真实标注?
若直接使用真实标注,浅层的误差会显得更大,模型在学习真实标注时反而容易受到过大偏差的影响,导致收敛更慢或难以优化。而最后一层的预测分布虽然不是完美,但通常更接近浅层能学习到的特征空间,因而是一个更稳定、渐进的优化目标。
总结
D-FINE这篇文章给我提供了很多思路,概率分布和自蒸馏,这些trick都是可以用于模型当中进行尝试,该文章代码开源,可以更深入学习。若需要代码解析,等复现后再更新


















 1558
1558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











