







V. Vs, J. M. Jose Valanarasu, P. Oza and V. M. Patel, “Image Fusion Transformer,” 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 2022, pp. 3566-3570, doi: 10.1109/ICIP46576.2022.9897280. keywords: {Training;Image sensors;Neural networks;Benchmark testing;Sensor fusion;Transformers;Feature extraction;Image fusion;Transformer;CNN;Long-range dependencies;Spatio-Transformer},
论文所在期刊:IEEE International Conference on Image Processing (ICIP)
发布时间:16-19 October 2022
所在级别:
影响因子:
论文笔记
关键词
Image fusion, Transformer, CNN, Long-range dependencies, Spatio-Transformer
图像融合,Transformer,卷积神经网络,长范围相关,空间-Transformer
提出问题
- 基于CNN的方法通过融合局部特征来执行图像融合。然而,它们不考虑图像中存在的长范围依赖性
核心思想
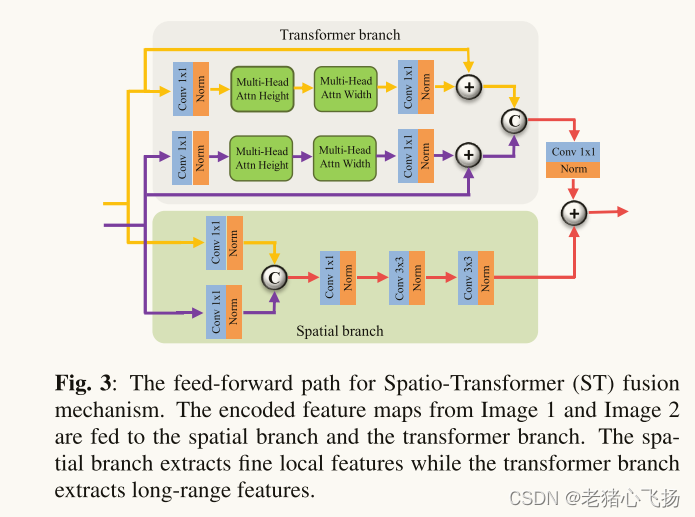
一种基于transformer的多尺度融合策略,兼顾本地和远程信息(或全局上下文)。所提出的方法遵循两阶段的训练方法。在第一阶段,我们训练一个自动编码器来提取多尺度的深度特征。在第二阶段,多尺度特征融合使用的空间变换器(ST)融合策略。ST融合块由CNN和Transformer分支组成,分别捕获本地和远程特征。
网络结构
- 整体框架
- IFT由三个部分组成:编码器网络,SpatioTransformer(ST)融合网络和嵌套解码器网络
- 编码器网络由四个编码器块组成,其中每个编码器块包含一个内核大小为3 × 3的卷积层,然后是ReLU和最大池化操作,从编码器网络的每个卷积块中
提取多尺度的深度特征 - ST融合网络由
空间分支和Transformer分支组成。空间分支由conv层和瓶颈层组成,用于捕获局部特征。Transformer分支由一个基于轴向注意力的Transformer块组成,用于捕获远程依赖关系(或全局上下文),ST融合网络融合从两个源图像中提取到的多尺度特征 - 最后通过以融合特征作为输入来训练嵌套解码器网络来获得融合图像。解码器网络基于RFN-Nest架构

- ST Fusion:由两个分支组成:空间和Transformer分支。
自我注意与轴向注意
自注意是一种注意机制,它将单个序列的不同标记联系起来,以便计算相同序列的表示。设x ∈ RCin×H×W和y ∈ RCout×H×W是输入和输出特征,其中Cin和Cout分别是输入和输出通道的数量,H和W分别对应于高度和宽度。输出y计算如下:- 其中qij、kij和vij是在任意位置i ∈ {1,…,H}且j ∈ {1,…,W}和分别计算为q = WQx、k = WKx和v = WVx。
- 可以推断自我注意力计算整个特征图的长距离亲和力,不像CNN。然而,这种自注意机制由于其二次复杂性而在计算上是昂贵的。
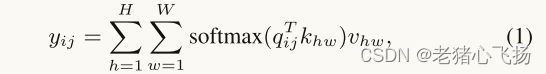
- 为了使计算更有效,采用
轴向注意力,沿着高度轴的自注意沿着可以被计算为:- 首先在特征图高度轴上执行自我注意,然后在宽度轴上执行自我注意,从而降低计算复杂度
- Wang提出了一种可学习的位置嵌入,用于轴向注意查询,键和值,以使亲和度对位置信息敏感。这些位置嵌入是在训练期间联合学习的参数。
- 其中rq、rk、rv ∈ RH×H是高度轴的位置嵌入。

损失函数
- 总损失
- Ldet为结构相似性损失
- Lfeat为特征相似性损失
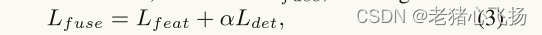
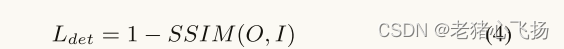
- M是提取深度特征的尺度数
- f、I1、I2分别表示融合图像、输入源1图像和输入源2图像。
- w1、wI 1、wI 2是用于平衡损耗幅度的折衷参数。
- Φm f是融合特征图,而ΦI1和ΦI2分别对应于输入源1和输入源2图像的编码特征图。
- 这种损失
约束融合的深度特征以保留显著结构,从而增强融合的特征空间以学习更多显著特征并保留精细细节。
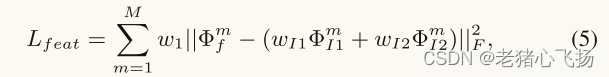
数据集
- 在KAIST数据集中的80000对可见光和红外图像上训练模型
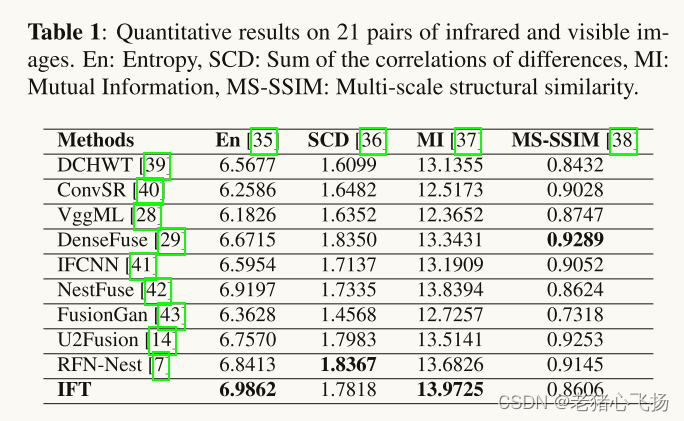
- 对TNO人为因素数据集中的21对可见光和红外图像进行了测试
训练设置
- 对于可见光和红外融合,将图像放大到256 × 256,并将超参数wI 1,wI 2,w1,α设置为6,3,100,700。对于所有实验,我们将学习率、epoch和batch size分别设置为10−4、4和2
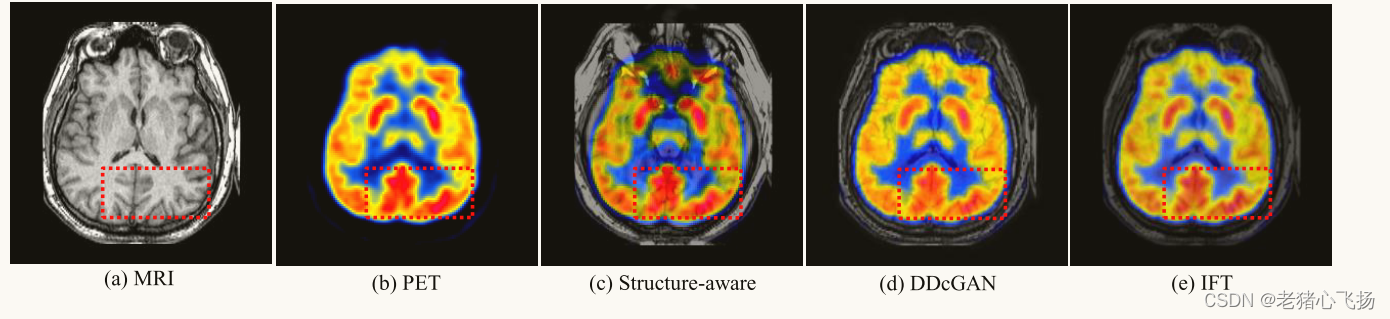
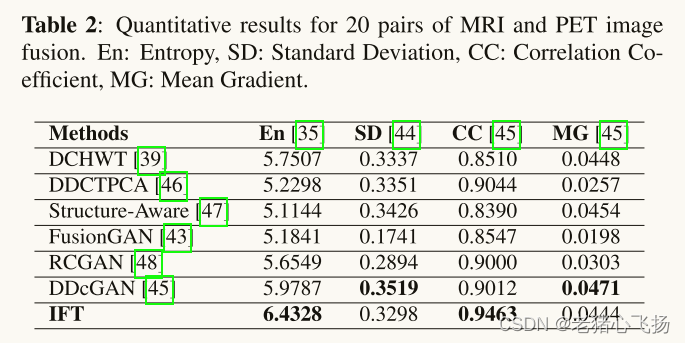
- 对于MRI和PET图像的实验,网络在9981个裁剪的补丁上进行训练,这些补丁具有从哈佛MRI和PET数据集获得的图像对。在从哈佛MRI和PET图像融合数据集中采样的20对MRI和PET图像上评估训练模型。在训练过程中,我们将图像调整为84 × 84,并将PET图像转换为IHS比例,以将I通道与MRI图像融合。
实验
评价指标
实验结果中表格的评价指标不懂的,可以看看这个:图像融合网络的通用评估指标
Baseline
实验结果
- 可见光与红外光图像融合:红色框突出显示人类,黄色框突出显示精细特征的重建

- MRI和PET图像融合
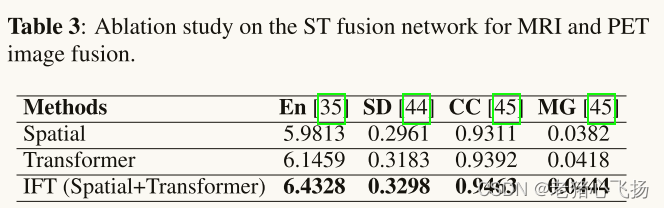
- 消融实验















 3246
3246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









