







 该篇文章介绍了一种新颖的图像融合方法YDTR,利用Y形动态Transformer模块(DTRM)结合卷积神经网络(CNN)和Transformer,增强红外与可见光图像的特征提取,以提高全局上下文信息的关联。文章还探讨了结构相似性和空间频率的损失函数设计,以及实验结果对比基线方法的表现。
该篇文章介绍了一种新颖的图像融合方法YDTR,利用Y形动态Transformer模块(DTRM)结合卷积神经网络(CNN)和Transformer,增强红外与可见光图像的特征提取,以提高全局上下文信息的关联。文章还探讨了结构相似性和空间频率的损失函数设计,以及实验结果对比基线方法的表现。
@article{tang2022ydtr,
title={YDTR: Infrared and visible image fusion via Y-shape dynamic transformer},
author={Tang, Wei and He, Fazhi and Liu, Yu},
journal={IEEE Transactions on Multimedia},
year={2022},
publisher={IEEE}
}
| 论文级别:SCI A2 |
| 影响因子:7.3 |
文章目录
📖论文解读
现有的基于深度学习的方法通常通过卷积运算从源图像中提取互补信息,这导致全局特征保留有限。
为了解决这个问题,作者提出了一种Y形动态transformer(YDTR)
动态transformer模块(DTRM)不仅用来获取局部特征,还可以获取上下文信息。
Y形网络可以更好的保留细节。
此外作者还设计了由结构相似性SSIM和空间频率SF组成的损失函数。
🔑关键词
Dynamic transformer, image fusion, infrared image, Y-shape network
动态transformer, 图像融合, 红外图像, Y形网络
💭核心思想
CNN+Transformer+AE+Y形网络
使用Y形网络的两条分支分别提取红外及可见光图像的纹理细节,然后在主干充分合并。
DTRM可以充分挖掘局部和全局信息。
🪅相关背景知识
本文的背景知识涉及:
- 深度学习
- 神经网络
- 图像融合
- 自编码器
- transformer
下图为作者总结的一些方法的特点
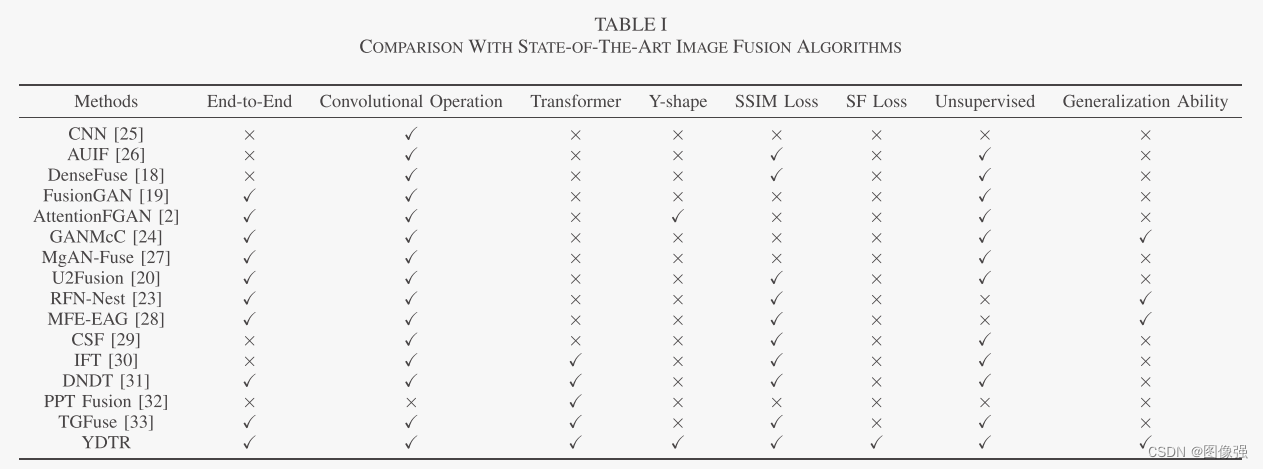
我觉得这个Y形结构优点牵强,
打个比方,(DIF-Net)Unsupervised Deep Image Fusion With Structure Tensor Representations就是典型的Y形结构
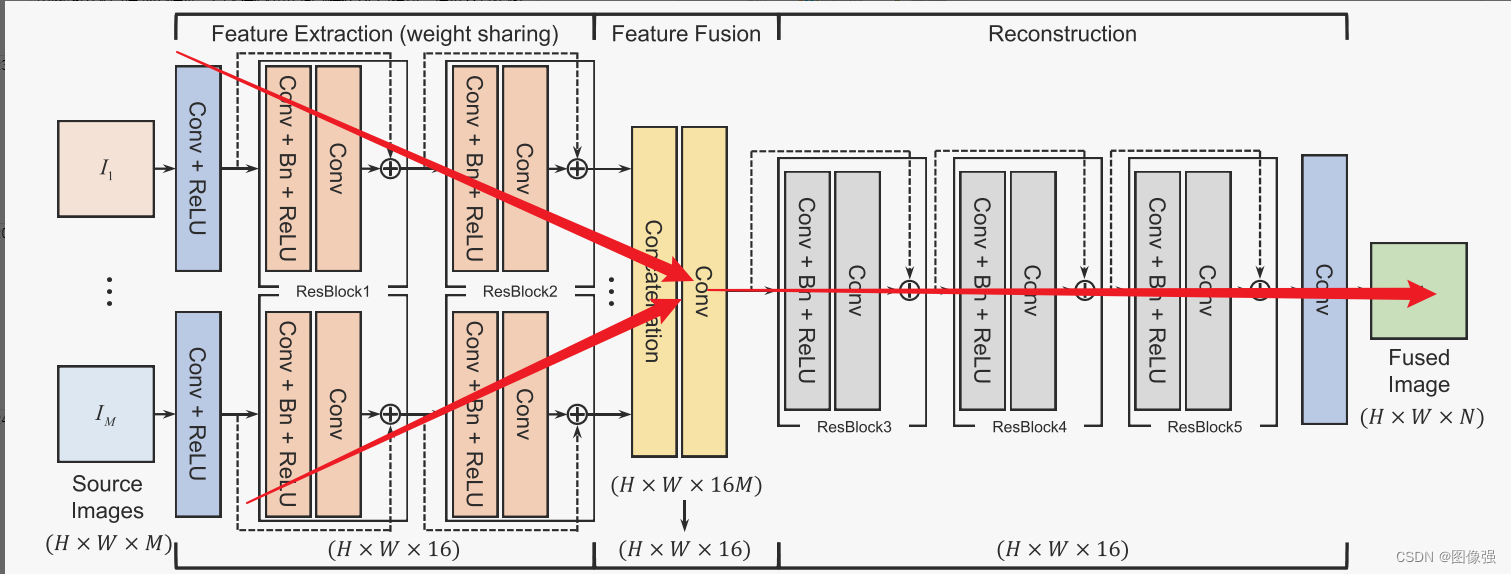
IFCNN也算是Y形结构的变体。
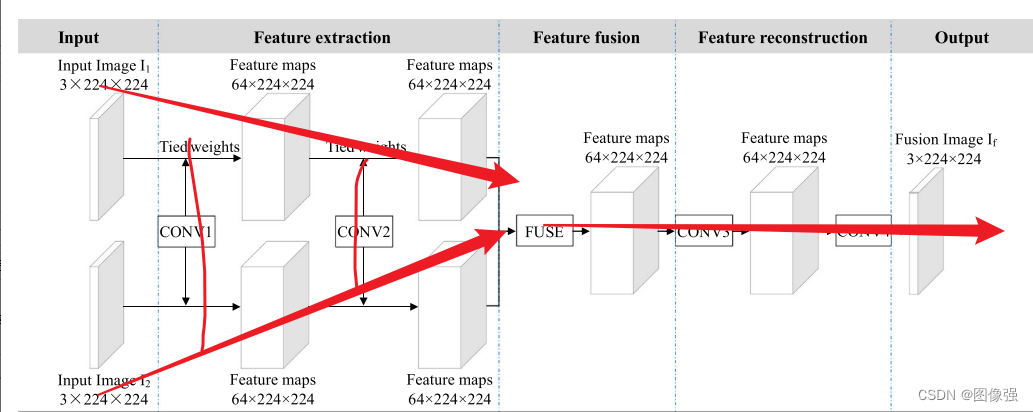
其实就是两个分支分别处理不同模态的图像,然后汇总。所以这个”Y形结构创新“仁者见仁智者见智。
🪢网络结构
作者提出的网络结构如下所示。这是我目前见过最长的网络结构图了,足足占了一页的80%左右。
让我们看看作者究竟提出了什么想法。
其实这个网络结构很简单那,就是双分支双编码器单解码器的网络结构,在编码器后面和解码器前面加入了作者设计的DTRM,也就是动态transformer模块用来提升全局上下文信息的关联。
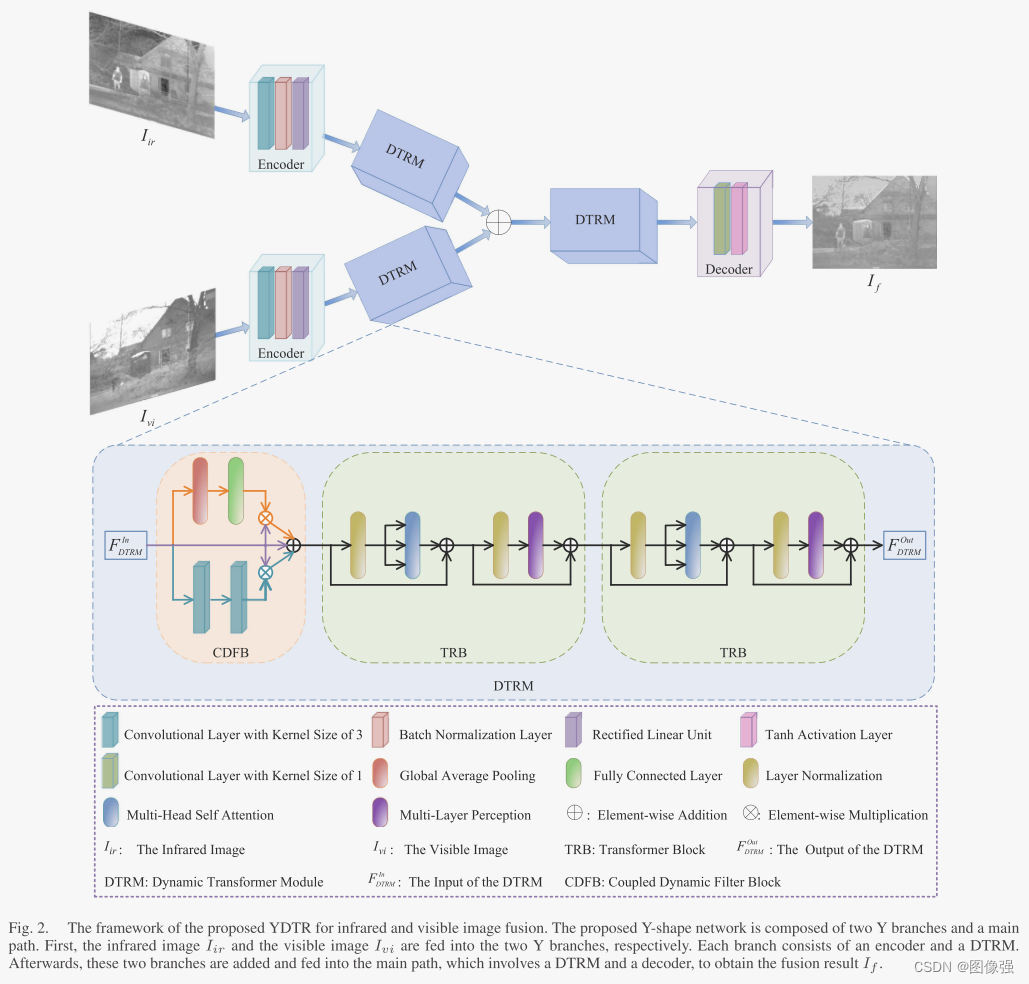
从上图我们可以看到,Y形结构每条分支均包含一个编码器和一个DTRM
在分支中,编码器用于提取浅层特征,STRM用于对远程互补信息进行捕获。
主干由一个用于特征集成的DTRM和一个用于降维的解码器组成。
在DTRM中,由一个CDFB和两个TRB组成。说白了就是一个滤波+两个Transformer块。
📉损失函数
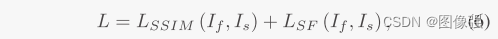
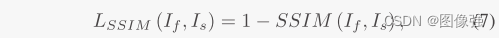
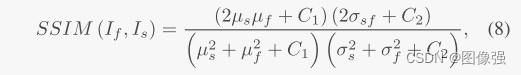
上面的SSIM损失函数很常见,但是空间频率损失函数就不太常见了,我们一起来看看。
一般来说,SF都是用在评价指标项里,这里作者相当于直接从评价指标出发,从结果出发找方法。
SF其实就是通过水平和垂直梯度计算得出的 ,反应了图像灰度级变换。
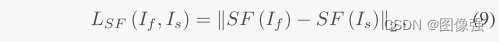
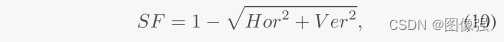
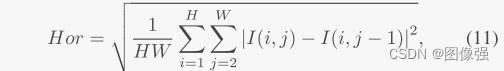
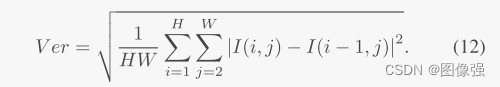
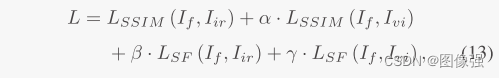
🔢数据集
- TNO, RoadScene,128× 128
图像融合数据集链接
[图像融合常用数据集整理]
🎢训练设置

🔬实验
📏评价指标
- QMI
- QNCIE
- QP
- MS-SSIM
- QCV

扩展学习
[图像融合定量指标分析]
🥅Baseline

✨✨✨扩展学习✨✨✨
✨✨✨强烈推荐必看博客[图像融合论文baseline及其网络模型]✨✨✨
🔬实验结果






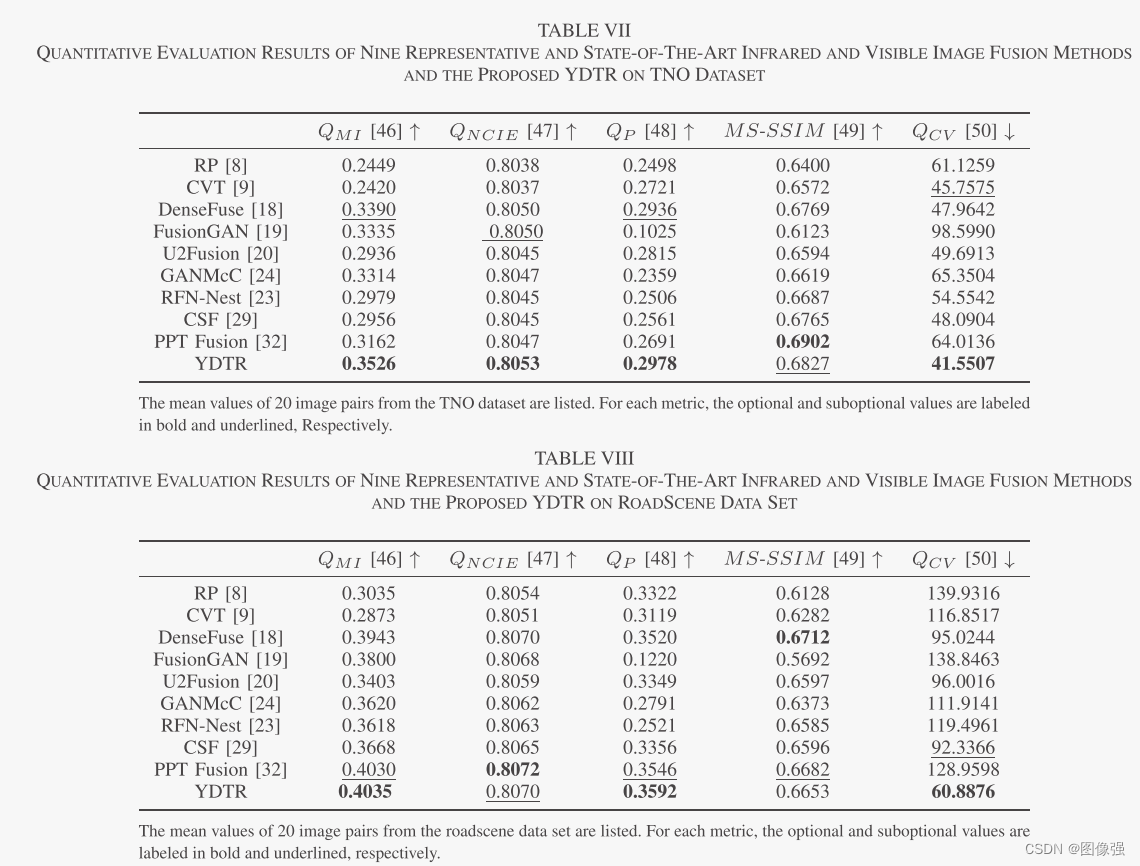
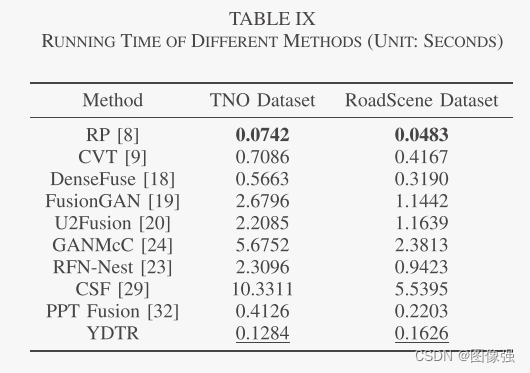
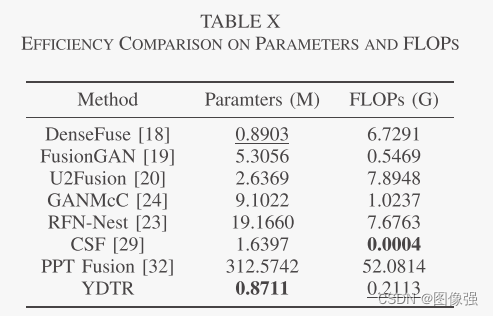
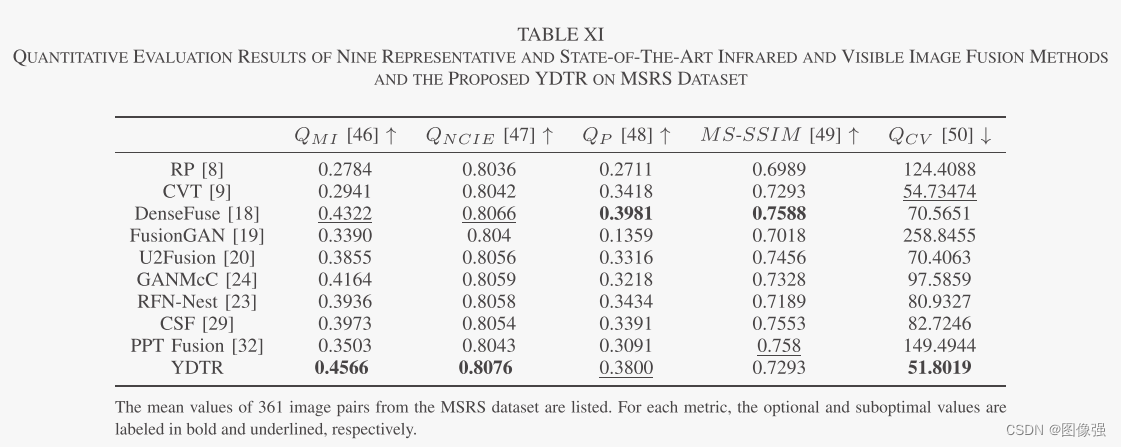

更多实验结果及分析可以查看原文:
📖[论文下载地址]
🧷总结体会
本文其实就是双编码器单解码器的网络结构+动态transformer
🚀传送门
📑图像融合相关论文阅读笔记
📑[CS2Fusion: Contrastive learning for Self-Supervised infrared and visible image fusion by estimating feature compensation map]
📑[CrossFuse: A novel cross attention mechanism based infrared and visible image fusion approach]
📑[(DIF-Net)Unsupervised Deep Image Fusion With Structure Tensor Representations]
📑[(MURF: Mutually Reinforcing Multi-Modal Image Registration and Fusion]
📑[(A Deep Learning Framework for Infrared and Visible Image Fusion Without Strict Registration]
📑[(APWNet)Real-time infrared and visible image fusion network using adaptive pixel weighting strategy]
📑[Dif-fusion: Towards high color fidelity in infrared and visible image fusion with diffusion models]
📑[Coconet: Coupled contrastive learning network with multi-level feature ensemble for multi-modality image fusion]
📑[LRRNet: A Novel Representation Learning Guided Fusion Network for Infrared and Visible Images]
📑[(DeFusion)Fusion from decomposition: A self-supervised decomposition approach for image fusion]
📑[ReCoNet: Recurrent Correction Network for Fast and Efficient Multi-modality Image Fusion]
📑[RFN-Nest: An end-to-end resid- ual fusion network for infrared and visible images]
📑[SwinFuse: A Residual Swin Transformer Fusion Network for Infrared and Visible Images]
📑[SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer]
📑[(MFEIF)Learning a Deep Multi-Scale Feature Ensemble and an Edge-Attention Guidance for Image Fusion]
📑[DenseFuse: A fusion approach to infrared and visible images]
📑[DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pair]
📑[GANMcC: A Generative Adversarial Network With Multiclassification Constraints for IVIF]
📑[DIDFuse: Deep Image Decomposition for Infrared and Visible Image Fusion]
📑[IFCNN: A general image fusion framework based on convolutional neural network]
📑[(PMGI) Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity]
📑[SDNet: A Versatile Squeeze-and-Decomposition Network for Real-Time Image Fusion]
📑[DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion]
📑[FusionGAN: A generative adversarial network for infrared and visible image fusion]
📑[PIAFusion: A progressive infrared and visible image fusion network based on illumination aw]
📑[CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion]
📑[U2Fusion: A Unified Unsupervised Image Fusion Network]
📑综述[Visible and Infrared Image Fusion Using Deep Learning]
📚图像融合论文baseline总结
📑其他论文
📑[3D目标检测综述:Multi-Modal 3D Object Detection in Autonomous Driving:A Survey]
🎈其他总结
🎈[CVPR2023、ICCV2023论文题目汇总及词频统计]
✨精品文章总结
✨[图像融合论文及代码整理最全大合集]
✨[图像融合常用数据集整理]
🌻【如侵权请私信我删除】
如有疑问可联系:420269520@qq.com;
码字不易,【关注,收藏,点赞】一键三连是我持续更新的动力,祝各位早发paper,顺利毕业~



















 662
662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











