







文章目录
大模型背景
专用模型:针对特定的任务,一个模型只能解决一个问题
通用大模型:一个模型可以应对多种不同的任务、多种模态
大模型成为发展通用人工智能的重要途径

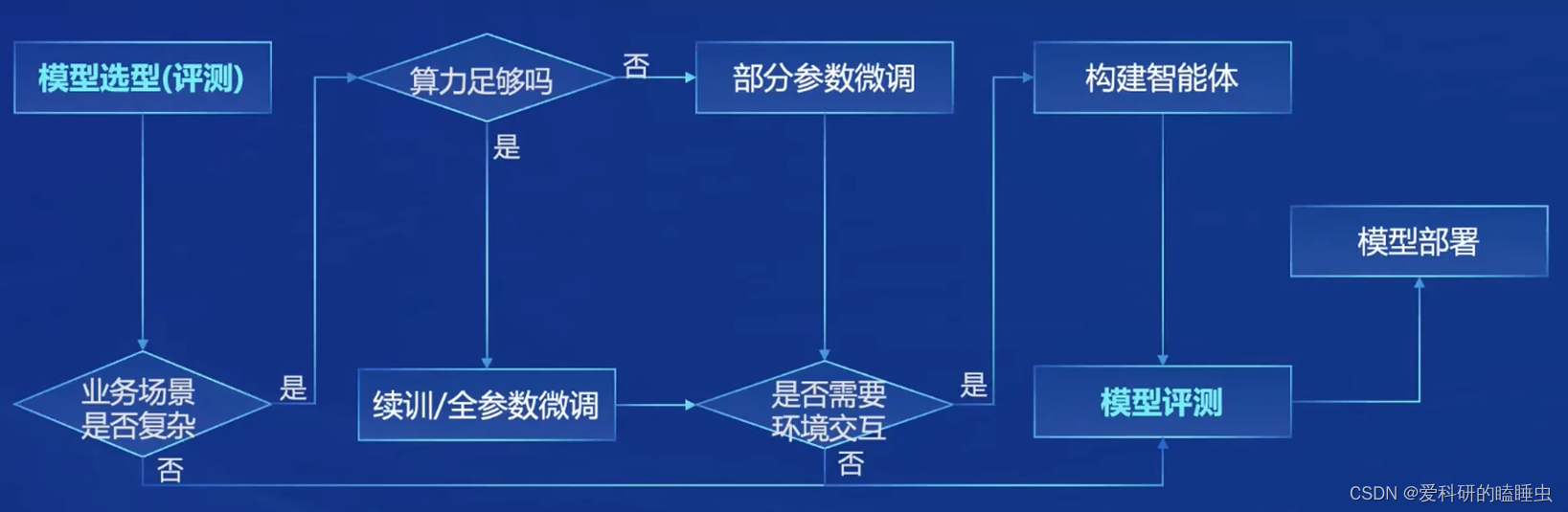
大模型开发流程
模型到应用的开发流程
InternLM 2.0
InternLM 2.0包含InternLM2-Base、InternLM2和 InternLM2-Chat
- InternLM2-Base:高质量和具有很强可塑性的模型基座,是模型进行深度领域适配的高质量起点
- InternLM2:在Base基础上,在多个能力方向进行了强化 ,在评测中成绩优异,同时保持很好的通用语言能力
- InternLM2-Chat:在Base基础上,通过SFT和RLHF,面向对话交互进行了优化,具有很好的指令遵循、共情聊天和调用工具等的能力

SFT与RLHF
SFT(Structured Fine-Tuning)是一种模型优化技术,它通过在预训练的语言模型上进行有针对性的微调,以适应特定任务或领域。SFT可以提高性能的原因有几个:
-
领域自适应:预训练的语言模型通常在大规模通用语料库上进行训练,而SFT可以通过在特定领域的数据上微调模型,使其更好地适应该领域的特定模式、术语和上下文。这种领域自适应可以提高模型在特定任务或领域中的性能。
-
数据增强:SFT通常会使用特定任务或领域的数据来微调模型,这种数据增强可以丰富模型的训练数据,提供更多的样本和多样性,有助于改善模型的泛化能力和性能。
-
参数调整:SFT允许对模型进行参数微调,以优化模型在特定任务上的表现。通过微调模型的参数,可以更好地适应任务的要求,提高性能。
RLHF(Reward Learning from Human Feedback)是一种使用人类反馈进行强化学习的技术。尽管RLHF可以在某些情况下提供性能改进,但它也可能对性能产生负面影响的原因包括:
- 人类反馈的限制:RLHF依赖于人类提供的反馈信号来指导模型的学习。然而,人类反馈可能存在主观性、不一致性和有限性的问题。人类的主观判断和个体差异可能会导致训练出的模型在特定任务上的性能不稳定或低效。
- 人类反馈的代价:收集和利用人类反馈可能需要大量的时间、人力和资源。人类标注大规模数据集或提供反馈的过程可能会成为瓶颈,限制了RLHF的应用范围和效率。
- 环境差异:人类反馈通常是在特定环境下给出的,而这个环境可能与模型在实际应用中所面临的环境存在差异。这种环境差异可能导致模型在实际应用中的性能与在训练时根据人类反馈所表现的性能不一致。
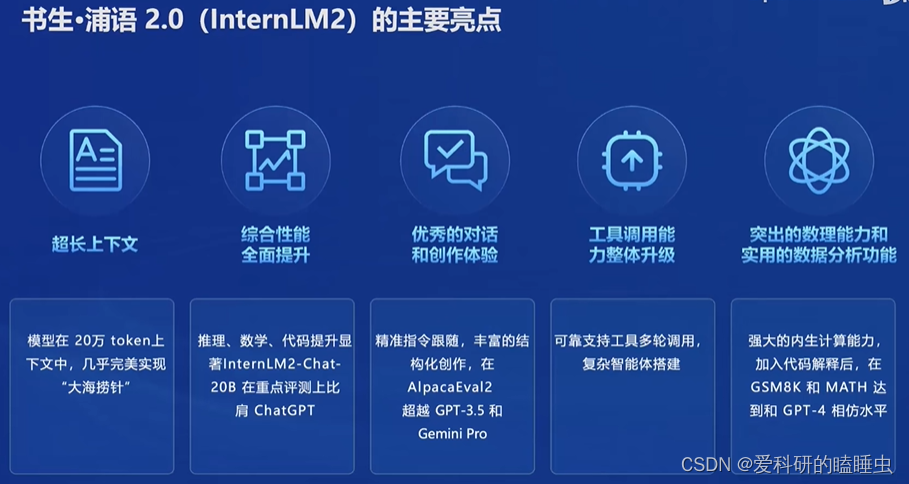
InternLM2主要亮点
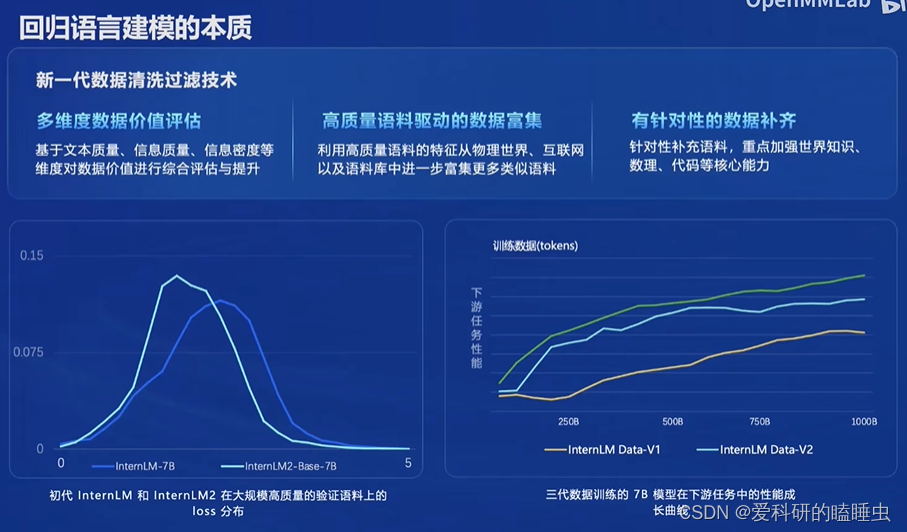
InternLM2通过新一代数据清洗过滤技术,性能上达到了多个亮点。
- 超长上下文理解:模型在20万token上下文中,几乎完美的实现“大海捞针”
- 综合性能全面提升:推理、数学、代码提升显著
- 优秀的对话和创作体验:精准指令跟随,丰富的结构化创作,在AlpacaEval2超越GPT-3.5和Gemini Pro
- 工具调用能力整体升级:可靠支持工具多轮调用,复杂智能体搭建
- 突出的数理能力和实用的数据分析功能:强大的内生计算能力,加入代码解释后,在GSM8K和MATH达到和GPT-4相仿水平
书生·浦语全链路开源开放体系
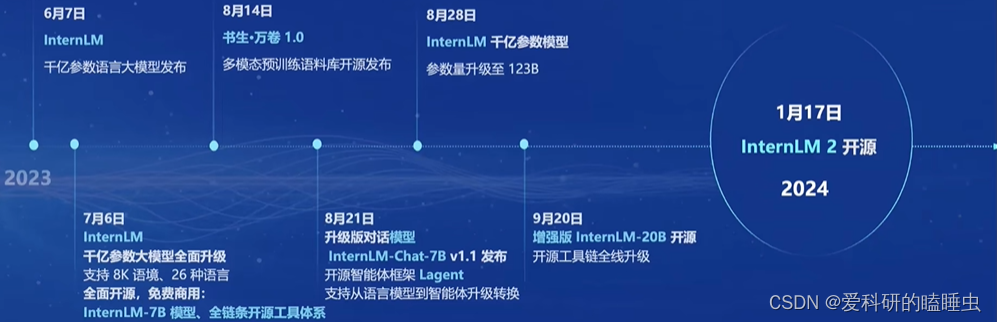
书生·浦语大模型开源历程
书生从训练到应用的全过程开源,包括数据准备,预训练架构InternLM-Train,微调框架XTuner,部署框架LMDeploy,评测工具OpenCompass,在应用方面智能体Lagent和智能体工具箱AgentLego。

数据-书生·万卷
包括超1TB的50亿个文档的文本数据、超140G的2200万个图像-文本数据集和超900G的1000多个视频数据,进行了多模态融合、精细化处理和价值观对齐等处理

InternLM-Train
- 高可扩展,支持扩展到千卡训练
- 极致性能优化,Hybrid Zero加速技术
- 兼容主流,无缝接入HuggingFace等技术生态,支持各类量化技术
- 开箱即用,支持多种规格语言模型,修改配置即可训练

微调 XTuner
大语言模型的下游应用中,增量训练和有监督微调是经常用到的两种方式
- 增量训练,让基座模型学习到新知识
- 有监督微调,让模型学会理解和遵循各种指令,或注入少量的领域知识
XTuner框架
- 支持多种微调算法,多种微调策略与算法,覆盖各类SFT场景
- 适配多种开源生态,支持HuggingFace、ModelScope模型或数据集
- 自动优化加速,无需关注复杂的显卡优化
- 适配多种硬件,支持NVIDIA 20系列以上的所有显卡
评测工具 OpenCompass
国内外评测工具

OpenCompass评测工具发展历程
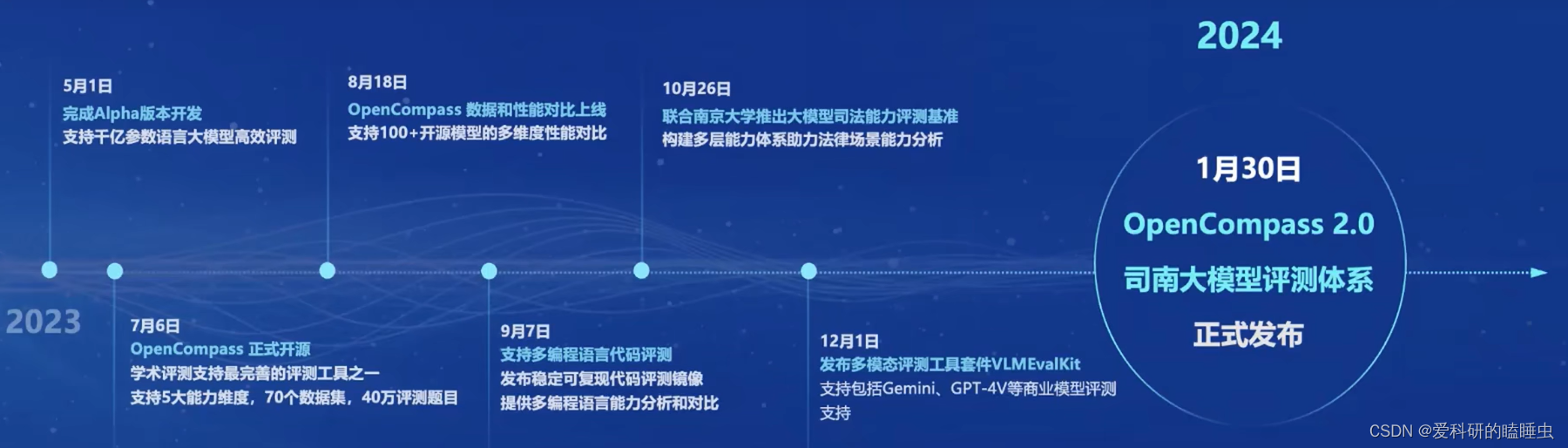
OpenCompass评测工具,是全球领先的大模型开源评测体系,包括6大维度
- 学科,包括初中考试、高考、大学考试、语言能力考试、职业资格考试
- 语言,字词释义、成语习语、语义相似、指代消解、翻译
- 知识,知识问答、多语种知识问答
- 理解,阅读理解、内容分析、内容总结
- 推理,因果推理、常识推理、代码推理、数学推理
- 安全,偏见、有害性、公平性、隐私性、真实性、合法性
工具层、方法层、能力层和模型层
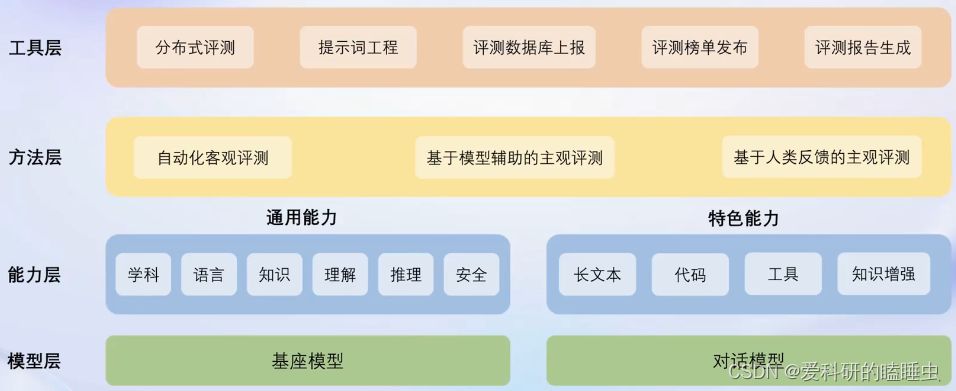
OpenCompass评测工具包括:
-
CompassRank 中立全面的性能榜单
大语言模型总榜单
多模态总榜单 -
CompassKit 大模型评测全栈工具链
- 数据污染检查
- 更丰富的模型推理接入
- 长文本能力评测
- 中英文双语主观评测

-
CompassHub 高质量评测基准社区
开源开放,共建共享大模型评测,让更多的开发者参与到评测中,汇聚更多优质的数据
部署 LMDeploy
大模型部署的挑战

LMDeploy框架
- 高效推理引擎,持续批量处理技巧,深度优化的低比特计算kernel,模型并行,高效的k/v缓存机制
- 完备易用的工具链,量化、推理、服务全流程,无缝对接OpenCompass评测推理精度,与OpenAI接口高度兼容
- 支持交互式推理,不为历史对话买单

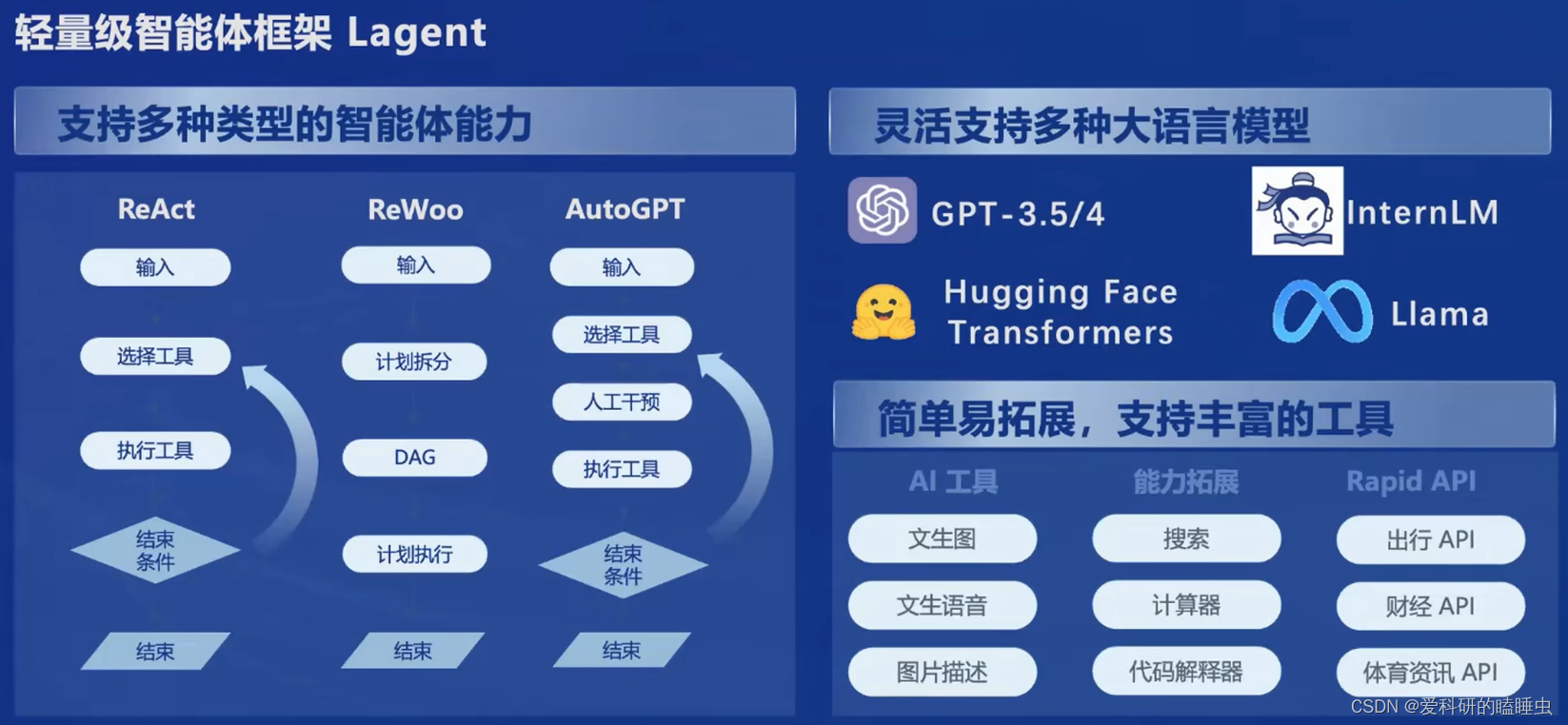
智能体 Lagent
- 支持多种类型的智能体能力,包括ReAct、ReWoo、AutoGPT
- 灵活支持多种大语言模型,包括GPT-3.5/4、Llama、InternLM
- 支持丰富的工具,包括AI工具(文生图、文生语音)、能力拓展(搜索、计算器、代码解释器)、Rapid API(出行API、财经API)
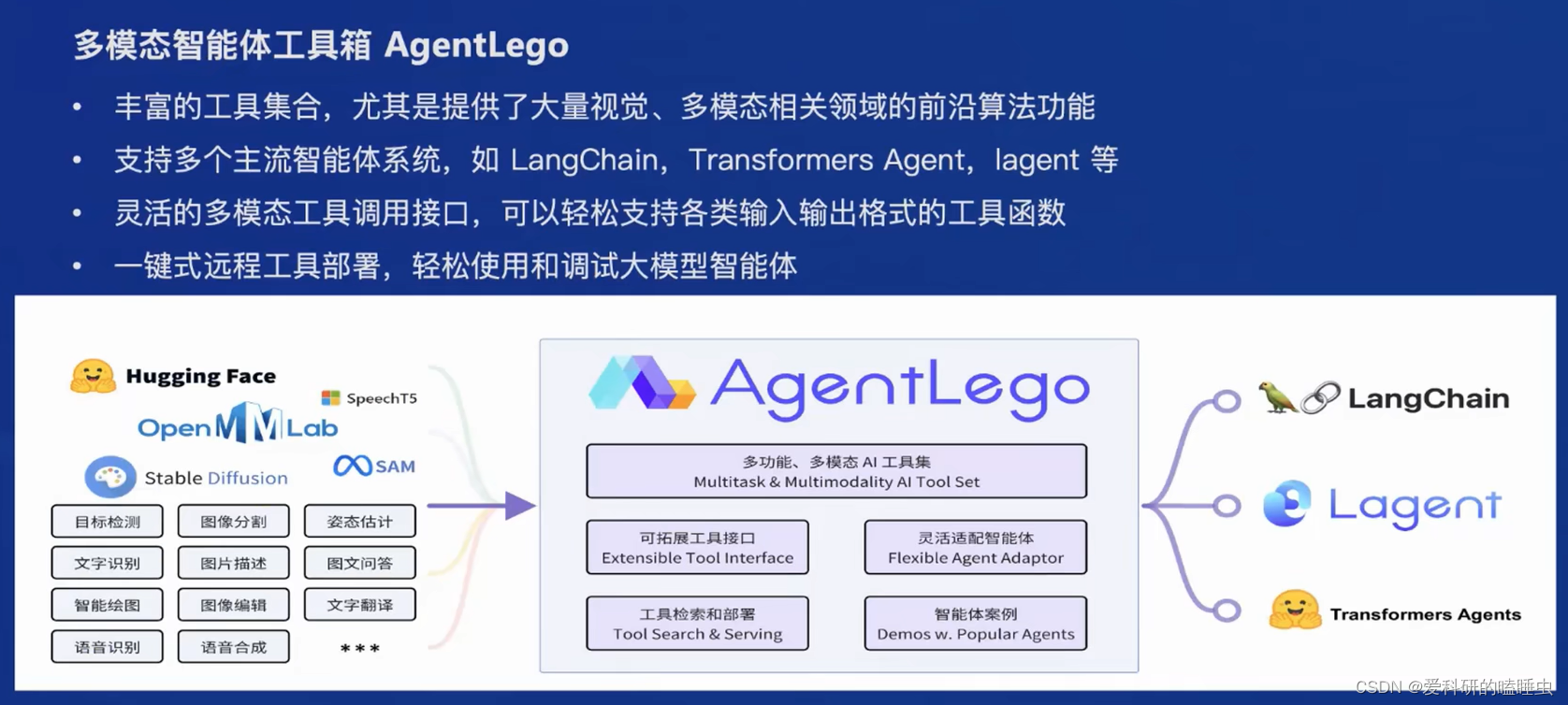
智能体工具箱 AgentLego
- 支持多模态任务
- 支持主流智能体系统,LangChain、Transformers Agent、Lagent
- 多模态工具接口















 1337
1337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









