






目录
EfficientNetV1:
原理介绍:
之前的深度学习论文都是在某个设计维度上对网络结构进行研究,比如网络结构的操作层个数(depth)、操作层的通道数(width)或者输入图片的分辨率,很少有论文同时对这三种维度上的组合搜索进行研究。EfficientNetV1研究的就是在相同FLOPS算力的限制下,探索网络深度、宽度和分辨率对相同操作类型网络的结果影响,找到最优的配置比例参数。
- 增加网络的深度能够得到更加丰富、复杂的feature map,而且能够很好的应用到其它任务中。但网络的深度过深会面临梯度消失,训练困难的问题。
- 增加网络的width能够获得更高细粒度的特征并且也更容易训练,但对于width很大而深度较浅的网络往往很难学习到更深层次的特征。
- 增加输入网络的图像分辨率能够潜在得获得更高细粒度的特征模板,但对于非常高的输入分辨率,准确率的增益也会减小。并且大分辨率图像会增加计算量。
优化问题:
基本卷积网络问题可以描述为:

其中:表示连乘运算,
表示一个运算操作,
表示
运算在
中执行的次数,
是执行次数也是深度(depth),X表示输入
的特征矩阵,
表示X的高度宽度(分辨率resolution)以及Channels(width)。
在一个标准的卷积神经网络中,网络结构的变化一般规律是:随着网络深度的增加,分辨率在每个stage减小一半,特征通道翻倍。EfficientNet的设计空间是每个stage的分辨率、通道数
和操作层数
,为了减小搜索的设计空间,规定这三个维度的数值在stage上按照一定比例均匀变化。作者的目的是希望在给定资源限制的条件下,找到网络的深度、宽度和分辨率,最大限度地提高模型网络的分类准确率,优化问题可以表述为:

其中,d , w , r分别用来缩放深度depth、缩放分辨率resolution和缩放特征矩阵的channel(通道宽度width)。target_memory为memory限制,target_flops为FLOPs限制。
作者是思路是一个卷积网络所有的卷积层必须通过相同的比例常数进行统一扩展,这句话的意思是,三个参数乘上常数倍率。所以个一个模型的扩展问题,就用数学语言描述为:

其中,分别表示深度、宽度和分辨率三种维度,引进一个混合系数
,并构成比例,这个比例的约束是
。
为什么宽度和分辨率的比例系数需要平方呢?因为计算量FLOPS的变化比例是和或者
的平方成正比的,这样子的话才能保证FLOPS随着
的变化呈现
的比例变化。
网络架构:
以MnasNet的基本模块MBConv为搜索空间,搜索出了一个基准网络(FLOPS<400M),叫做EfficientNet-B0,这个网络模型的结构为:
 其中MBConv结构为:
其中MBConv结构为:

[1x1升维] -> DW -> SE -> 1x1[降维] -> Droupout -> Shortcut
EfficientNetV2:
EfficientNetV1中存在的问题:
- 训练图像尺寸很大时,训练速度非常慢。
- 在浅层网络中使用Depthwise convolutions速度会很慢。
- 使用同等缩放策略并不是最优的。
原理介绍:
基于EfficientNetV1中存在的问题,EfficientNetV2设计了一个搜索空间,其还包含了额外的操作,如Fused MBConv,并应用训练感知NAS和缩放来联合优化模型精度、训练速度和参数量。我们发现的名为EfficientNetV2的网络训练速度比以前的型号快4倍(图3),而参数量则小6.8倍。
Fused MBConv:将浅层MBConv结构替换成Fused-MBConv结构能够明显提升训练速度。
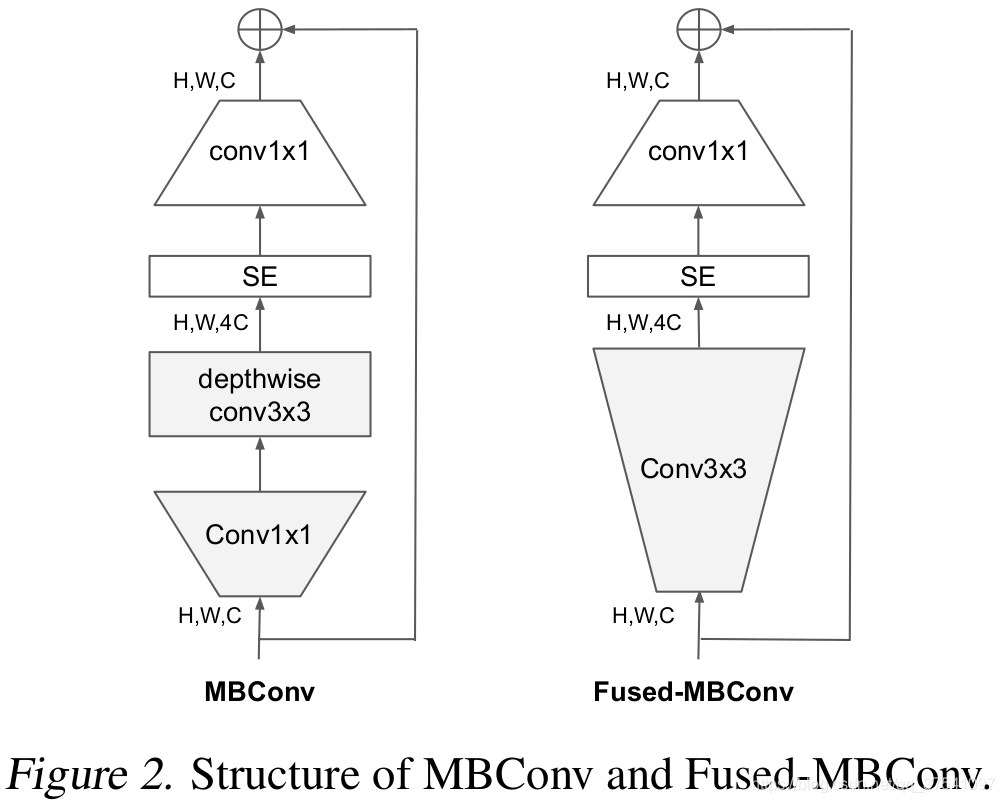
EfficientNet使用较小的expansion ratio,减少内存访问开销。偏向使用更小的kernel_size以增加感受野。移除了EfficientNetV1中最后一个步距为1的stage,减少内存开销。
网络结构:
















 2127
2127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









