








摘要
检索增强生成(RAG)方法在处理复杂问题(如多跳查询)时会遇到困难。虽然迭代检索方法通过收集附加信息来提高性能,但当前的方法通常依赖于对大型语言模型(LLM)的多次调用。本文介绍了高效的多跳问答检索器EfficientRAG。EfficientRAG迭代地生成新的查询,而不需要在每次迭代时调用LLM,并过滤掉不相关的信息。实验结果表明,在三个开放域多跳问答数据集上,效率trag优于现有的RAG方法。代码可在http://aka.ms/efficientrag中获得。
1 引言
大型语言模型(LLMs)在众多应用和任务中展现了卓越的性能(OpenAI, 2023;Jiang等人,2023a;Touvron等人,2023b)。然而,LLMs在训练数据中缺乏代表性不足的知识,特别是在特定领域设置中,并且仍然面临幻觉问题(Zhang等人,2023;Huang等人,2023;Yang等人,2023)。检索增强生成(RAG)技术(Lewis等人,2020;Gao等人,2023)已被广泛采用,以从外部资源中检索知识,以支撑生成的响应。以前的RAG方法通常采用一轮检索,例如,只使用用户查询或问题作为输入来检索知识(Guu等人,2020;Borgeaud等人,2022;Izacard等人,2023;Shi等人,2023)。这样的一轮RAG能够回答在输入查询中明确陈述所有所需信息的问题(Thorne等人,2018;Trischler等人,2017;Rajpurkar等人,2016),例如一跳问题,例如“牛顿的第三运动定律是什么?”。然而,一轮RAG方法可能在复杂问题中失败,因为在第一轮检索的信息之外还需要更多信息,例如多跳问题(Yang等人,2018a;Trivedi等人,2022a;Ho等人,2020b)。为了处理复杂的多跳问题,最近的工作提出通过多轮检索或推理来获取所需信息,例如为后续的多轮检索重写或生成查询(Khattab等人,2022;Ma等人,2023;Shao等人,2023;Jiang等人,2023b),交错多个检索和推理步骤(Trivedi等人,2023),多轮自我提问(Press等人,2023)。然而,这样的迭代检索方法有以下限制:(1)它们需要关于重写或为下一轮检索生成新查询的多次LLM调用,从而增加了延迟和成本。(2)它们需要专门的提示和少量样本,这些可能需要在不同场景下进行更新。
在本文中,我们受到这样的直觉启发,即多跳问题中的关系类型是有限的,或者与实体数量相比显著较少。正如Zhu等人(2023)所证明的,小型模型具有一定的推理能力,我们提出,从检索到的信息中识别关系及其相关实体可以有效地由小型模型而非LLMs来管理。因此,我们提出了EfficientRAG,它由一个标签器和过滤器组成,以迭代生成新的检索查询,并同时保留最相关的检索信息,与其他RAG方法相比提高了效率。
2 实证研究
2.1 LLM生成器的性能
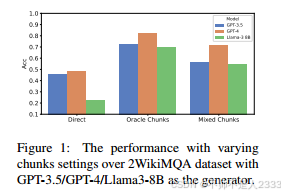
在本节中,我们进行了一项实证研究,以评估基于LLM的生成器在不同级别的检索信息下的表现。我们在三个数据集上进行了三种设置测试:直接提示(无检索片段)、oracle片段(以oracle片段作为上下文)和混合片段(以oracle片段和无关片段作为上下文),即HotpotQA(Yang等人,2018b)、2Wiki-multihop (2WikiMQA)(Ho等人,2020a)和MuSiQue(Trivedi等人,2022b)。生成器模型包括GPT-3.5(OpenAI, 2022)、GPT-4(OpenAI, 2023)的1106预览版本,以及Llama-3-8B1(Touvron等人,2023a)。我们使用GPT-3.5的准确度指标来评估模型答案,相关提示可以在附录B.1中找到。如图1所示,检索证明是有益的,无论是oracle设置还是混合设置,表现都优于直接回答方法。然而,无关片段的存在继续挑战LLM生成器,凸显了需要更精确的信息检索。
2.2 使用查询分解进行检索
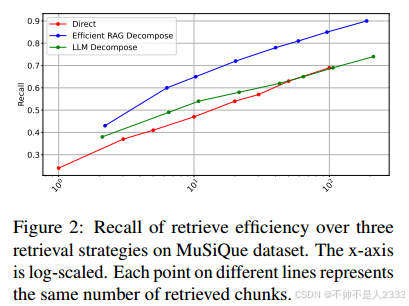
在面对复杂的多跳问题时,使用llm进行查询分解是一种常见的做法(Gao et al, 2023)。我们进行了另一项实证研究,以检查查询分解方法如何影响检索阶段。如图2所示,通过一次性分解(LLM分解,详见表11)检索的oracle块的数量超过了原始查询的直接检索。在相似数量的块上,迭代分解(EfficientRAG decomposition)实现了更高的召回率。当检索大约20个块时,效率trag分解实现的召回与LLM分解在检索大约200个块时具有相当的性能,从而证明了效率。所有检索器都使用contriever-msmarco (Izacard等人,2022)设置,块检索配置为1/3/5/10/20/30/50/100,LLM端点为gpt35-turbo-1106.
3 方法
3.1 EfficientRAG 框架
在本节中,我们介绍了EfficientRAG,这是一个即插即用的方法,旨在通过多次检索轮次高效地检索相关信息,以丰富检索信息并减少无关信息,从而帮助提高答案的质量和准确性。
EfficientRAG由两个轻量级组件组成:标签器与标记器(Labeler & Tagger)和过滤器(Filter)。这些组件共享相同的模型结构,标签器与标记器2从同一模型内的不同头部产生输出,而过滤器的输出来自另一个模型。标签器和过滤器都充当令牌级分类器,将令牌分类为真或假。
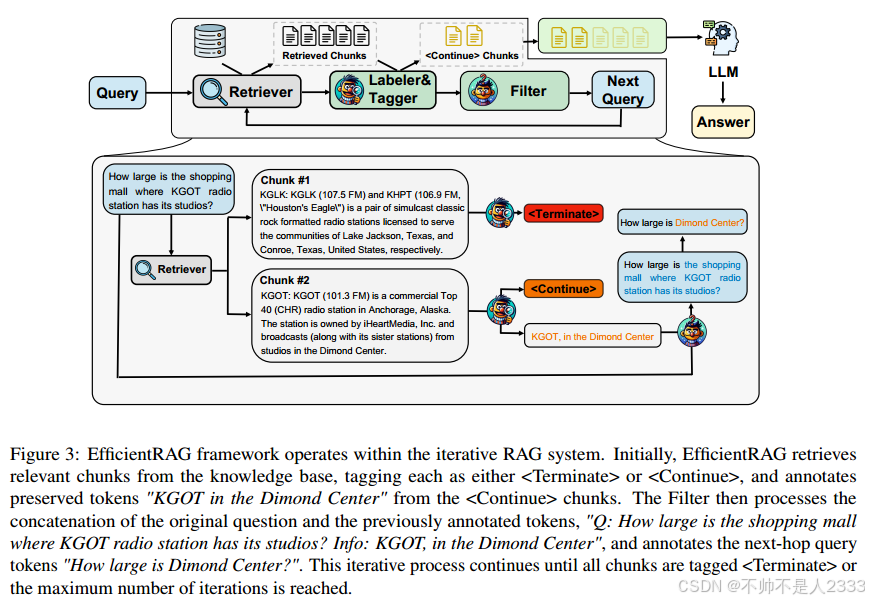
图3展示了EfficientRAG如何融入传统的RAG系统。给定一个查询,检索器从数据库中获取相关片段。
然后,标签器模块注释文档中的一系列令牌,这些令牌代表可能(部分)回答查询的有用信息。接着,标记器模块对片段进行标记,指示检索到的片段是有帮助的还是无关的。如果标记指示需要更多信息来回答查询,即标记为<Continue>,我们将这个片段添加到候选池中,该池将提供给基于LLM的生成器以获得最终答案。否则,如果文档被标记为无用或无关,我们将停止从此查询搜索后续分支。过滤器模块将标记的令牌和当前查询结合起来,构建下一轮检索的新查询。这是通过用标记的令牌(有用信息)替换查询中的未知部分来完成的。我们的方法有效地生成了后续检索轮次的新查询,旨在检索超出初始查询范围的信息。
一旦我们的方法获得足够的信息来回答初始问题,它就会停止并将所有这些信息传递给最终生成器以获得最终响应。利用我们高效的RAG方法消除了生成查询所需的多次LLM调用,从而在处理复杂查询时提高了性能。
3.2 综合数据构造
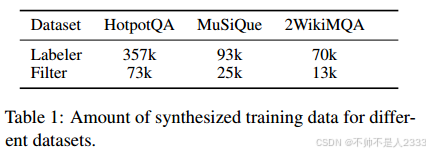
我们利用LLM为标签器和过滤器合成训练数据。这个过程包括多跳问题分解、令牌标注、下一跳问题过滤和负采样。合成数据在表1中详细说明。
多跳问题分解。给定一个多跳问题和相关片段,我们首先提示LLM将原始问题分解为几个单跳问题。每个单跳问题对应一个片段。然后,我们要求LLM解析子问题的依赖关系。
令牌标注。对于每个子问题及其对应的片段,我们提示LLM标注片段中对子问题回答重要的单词。我们用二元标签注释片段中的每个单词,以确定它是否重要并应该由EfficientRAG标签器保留。我们使用SpaCy工具包3,遵循Pan等人(2024)的方法。
下一跳问题过滤。给定一个单跳问题及其依赖问题的标注令牌,我们提示LLM生成下一个跳问题,这理想情况下是下一个检索查询。我们提取下一跳问题令牌的方式与令牌标注过程相同。
负采样。对于每个过滤后的下一跳问题,我们检索最相似但不相关的片段作为困难负片段。这些负片段将被标记为<Terminate>,而其他相关片段则被标记为<Continue>。
3.3 训练
我们训练EfficientRAG标签器执行两个任务,令牌标注和片段过滤,因为它们都使用相同的输入。我们使用一个自编码器语言模型作为编码器,为拼接的序列查询和片段的每个令牌提取嵌入。随后,我们使用一个全连接层将令牌嵌入投射到一个二维空间,表示“有用令牌”和“无用令牌”。另一个全连接层被适配用来将序列嵌入的平均池化投射到二维空间,代表片段标签<Continue>和<Terminate>。我们以类似的方式训练EfficientRAG过滤器,而其输入序列是查询和标注令牌的拼接。过滤器提取单词并将它们拼接起来,形成下一个跳查询。
4 实验
4.1 端对端QA性能
我们在与§2.1相同的三个多跳问答数据集上对我们的EfficientRAG和多个基线进行评估。我们选择以下模型作为我们的基线。第一种是不需要检索的直接回答,包括具有专有数据的LMs。在这种情况下,我们包括直接提示和思维链提示(Touvron等人,2023a)以及问题分解提示。其次,我们将朴素RAG的基线与前10个检索块作为其知识。第三,我们采用了先进的迭代RAG方法,如Iter-RetGen (Shao等人,2023)和SelfAsk (Press等人,2023)。实现提示在附录B.3中。
实现细节。EfficientRAG Labeler和Filter基于DeBERTa-v3large (He et al, 2021)进行微调,共有24层,304M个参数。我们采用lama-3- 8b - instruction作为问答阶段和所有其他基准。
我们使用Contriever-MSMARCO (Izacard等人,2022)作为数据合成和推理阶段的检索器。
我们按照3.2节使用Llama-3-70B-Instruct构建了训练数据(详细提示见附录B.2)。我们在4× Nvidia A100 gpu上分别训练了大约10个gpu小时,使用AdamW (Loshchilov和Hutter, 2019)优化器,学习率为5e-6。
5 结果与分析
5.1 检索性能
模型的性能使用Recall@K指标跨三个不同的数据集进行评估。如表2所示,EfficientRAG在HotpotQA和2WikiMQA数据集上获得了非常高的召回分数,召回值分别为81.84和84.08。考虑到HotpotQA的最小块检索数为6.41,2WikiMQA的最小块检索数为3.69,这些结果令人印象深刻。然而,EfficientRAG在MuSiQue数据集上的性能不太令人满意。这种次优结果可能归因于检索的块数量较少和数据集的复杂性增加。
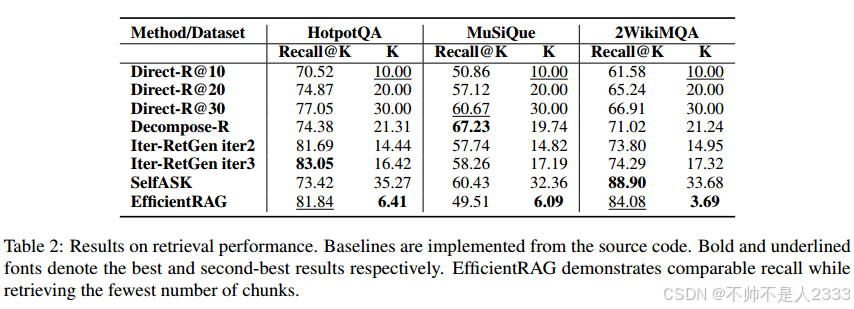
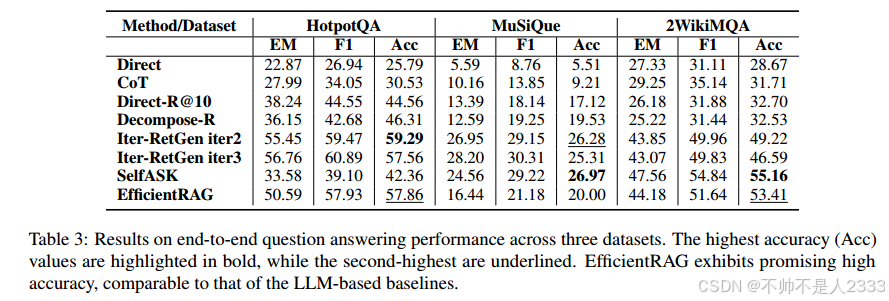
我们进一步评估了三个数据集上的QnA性能。如表3所示,我们的EfficientRAG框架在HotpotQA和2WikiMQA上都达到了第二高的准确率,即使在召回率较低的情况下,它在MuSiQue上也表现良好。这些基于LLM的系统表现不尽如人意,因为它们要求LLM用嘈杂的知识输入生成部分答案,但它们总是在中间步骤中失败。我们假设更多有用的知识和更少不相关的块是RAG系统的关键点,即使是一个简单的模型也可以用正确的RAG范式击败法学硕士。
5.2 推理效率
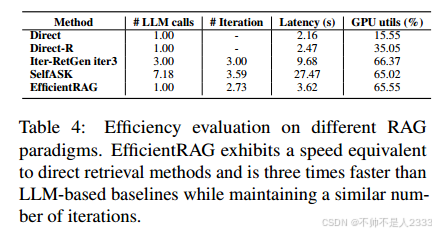
我们从MusiQue数据集中随机选择了200个样本进行实证研究,并计算了四个指标:LLM调用、迭代、延迟和GPU利用率。如表4所示,与其他迭代方法相比,我们的方法需要更少的迭代,在保持类似GPU利用率的情况下,时间效率提高了60%-80%。
5.3 使用不同生成器的性能表现
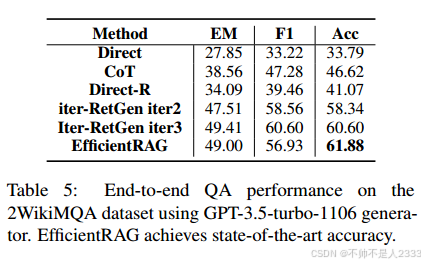
EfficientRAG可以从更强大的发电机中受益。如表5所示,使用GPT3.5作为生成器增强了基线和我们的方法的端到端性能。值得注意的是,EfficientRAG继续提供卓越的结果
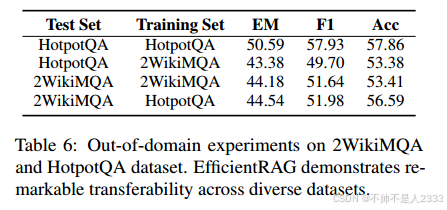
5.4 域外适配
EfficientRAG具有在不进行进一步下游训练的情况下适应不同场景的潜力。我们提出了一个跨HotpotQA和2WikiMQA数据集的领域外实验,其中我们在一个数据集上训练模型,并在另一个数据集上测试它。表6显示我们的模型能够很好地适应不同的数据集,甚至在某些情况下超过了在原始数据上训练的模型。这表明EfficientRAG并不依赖于特定领域的知识,展现了一定程度的迁移能力。
6 结论
在本研究中,我们介绍了高效检索器,这是一种用于多跳问题检索的新方法,可以迭代地生成新查询,同时避免了对大型语言模型的需求。对三个基准数据集的评估表明,EfficientRAG不仅可以用最少数量的检索块实现高召回,而且在随后的问答任务中也提供了有希望的结果。这些发现表明,EfficientRAG优于传统的检索增强生成方法,特别是在复杂的多跳问答场景中。

















 2324
2324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









