







 本文详细解释了训练集、验证集和测试集在深度学习中的作用,强调了它们之间的联系以及实验中的注意事项。此外,还介绍了交叉验证的概念,特别是K折验证,以及模型参数和超参数的区别。
本文详细解释了训练集、验证集和测试集在深度学习中的作用,强调了它们之间的联系以及实验中的注意事项。此外,还介绍了交叉验证的概念,特别是K折验证,以及模型参数和超参数的区别。
训练集、验证集和测试集概念
训练集(Training Set): 用于训练模型的数据集。训练集用来训练模型,拟合出数据分布规律,即确定模型的权重和偏置等参数,这些参数称为学习参数。
- 训练集使用多次
- 确定模型权重、偏置等学习参数
- 训练出(学习出)模型
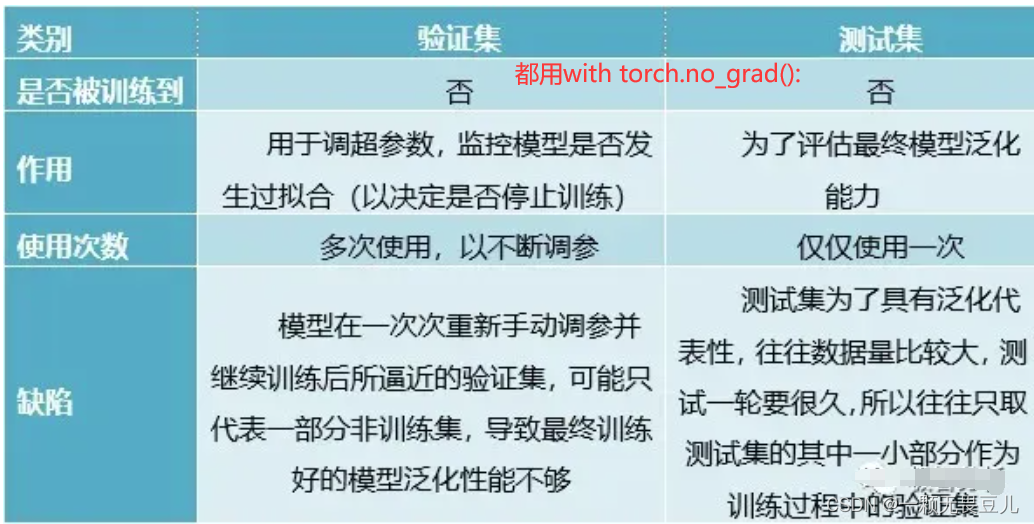
验证集(Validation Set): 用于验证模型性能的数据集。在模型训练过程中,验证集用来调整模型参数和超参数,以优化模型性能,避免过拟合,即验证集用于模型选择,并不参与学习参数的确定,而是为了选择出模型误差较小的模型参数和超参数。
- 验证集使用多次
- 调整并选择模型参数和超参数
- 选择模型(验证模型性能)
测试集(Test Set): 用于评估模型性能的数据集。在模型训练完成后,测试集用来评估模型的泛化能力(泛化能力即模型在未知数据上的表现),即测试集仅在训练完成后使用一次,评价最终模型的效果(其实,测试集可以跑多个epoch)。
- 不参与学习参数过程,也不参与超参数选择过程
- 测试集仅使用一次,完全独立,测试集未参与过训练或验证
- 评价最终模型
三者的联系和实验注意事项
-
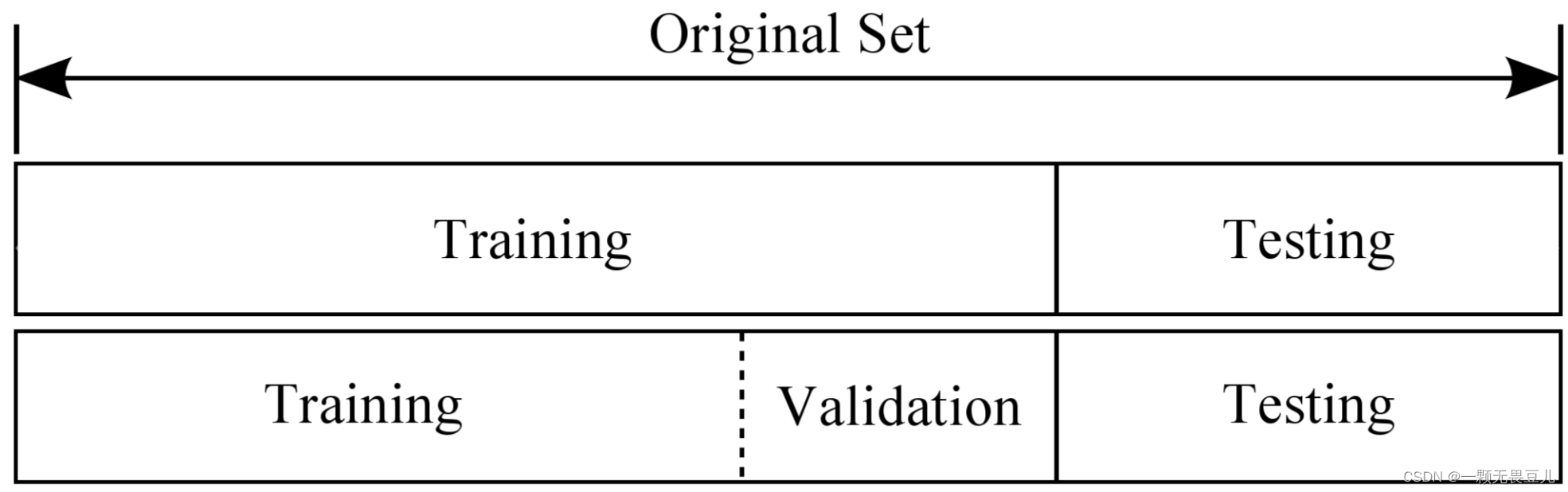
因训练集在学习模型过程中反复大量使用,验证集对模型偶尔的调整,测试集只对最终模型评价,所以,训练集、验证集和测试集数据常常划分关系:8:1:1或6:2:2,且三个数据集所用数据是不重叠的,是不同的!
-
测试集如同高考,决定最终成绩,决定最终模型性能,两人参加高考考同一份试卷,分数才能作对比,即只有在同样的测试集上,两个(或以上)模型的对比才有效。
(已有论文中常常不告知数据集的划分方式,为了和已有论文模型作对比,就是自己划分数据集,复现已有论文模型,将自己提出的模型和复现的对方的模型在相同测试集上作对比,说明自己提出模型的效果!!!); -
验证集如同高考的模拟考试——一模、二模、三模,通过参与模拟考,就可以调整自己考试状态,争取高考时达到一个好的状态,即验证集是为了从一堆可能的模型中,找到帮你表现最好的模型(指模型的参数、超参数),注意:这里的表现是在验证集上,选择了模型表现最好的超参数,再用测试集评估时,也可能存在效果不好的情况;
-
训练集如同作业题、练习题、周测、月测等等,模拟考、高考题一般都不会和平时练习题相同,是为了让学生学会知识、规律和举一反三的能力,所以训练集、验证集和测试集最好都没有重叠,模型才具有说服力。(目前公开的数据集,很多都已经划分好了训练集、验证集和测试集,且都没有数据重叠)
-
训练集和测试集易区分,验证集和测试集常搞混,验证集和测试集主要区别:
交叉验证
将数据集单纯划分为训练集、验证集和测试集时,并不是所有数据都参与了训练,存在数据信息利用不全的弊端,由于验证集只代表一部分非训练数据集,导致最终训练好的模型测试时的泛化能力并不好,所以为了保证泛化误差的稳定性,得到理想的模型,可以使用交叉验证,这里介绍K折验证法
(交叉验证方法很多,此篇涉及多种以及代码实现:https://blog.csdn.net/WHYbeHERE/article/details/108192957)
K折交叉验证:
1.将数据集分为训练集和测试集,测试集放在一边。
2.将训练集分为 k 份,每次使用 k 份中的1 份作为验证集,其他全部作为训练集。
3.通过 k 次训练后,得到了 k 个不同的模型。
4.评估 k 个模型的效果,从中挑选效果最好的超参数。
5.使用最优的超参数,然后将 k 份数据全部作为训练集重新训练模型,得到最终所需模型,最后再到测试集上测试。
参数、超参数的理解
- 模型参数: 参数属于模型内部的配置变量,它们通常在建模过程自动学习得出。如:线性回归或逻辑回归中的系数、支持向量机中的支持向量、神经网络中的权重、偏置。
- 模型超参数: 超参数属于模型外部的配置变量,他们通常由研究员根据自身建模经验手动设定。如学习速率,迭代次数,层数、K近邻中的K值。
深度学习的三大要素
- 数据
- 架构
- 损失

















 2465
2465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









