







informer中的超参数调优
在机器学习和深度学习模型中,超参数调优是指通过调整模型的超参数来提升模型的性能。超参数是那些在训练过程中不会更新的参数,而是需要在训练之前设置好的参数,例如学习率、批量大小、网络层数等。
在这段话中,描述了使用网格搜索(grid search)方法对超参数进行调优的过程。以下是详细的解释:
-
网格搜索:
网格搜索是一种系统地遍历预定义的超参数组合,从而找到最佳超参数的方法。对于每个超参数,定义一个值的集合,然后对这些集合进行笛卡尔积,得到所有可能的组合。然后,通过交叉验证来评估每个组合的性能,选择效果最好的组合。举例说明,如果有两个超参数:学习率(learning rate)和批量大小(batch size),它们的可能取值分别是:
- 学习率:[ {0.001, 0.01, 0.1} ]
- 批量大小:[ {16, 32, 64} ]
那么,网格搜索将评估以下所有组合的性能:
- (0.001, 16)
- (0.001, 32)
- (0.001, 64)
- (0.01, 16)
- (0.01, 32)
- (0.01, 64)
- (0.1, 16)
- (0.1, 32)
- (0.1, 64)
-
具体方法:
在文中,Informer模型包含了一个3层堆叠和一个2层堆叠(输入的1/4大小)作为编码器,以及一个2层解码器。超参数调优的具体方法如下:- 优化器:使用Adam优化器。
- 学习率:初始学习率为1e-4,每2个epoch衰减10倍,总共训练10个epoch。
- 批量大小:32。
-
零均值归一化:
输入数据在进行训练前需要进行零均值归一化处理。归一化可以加速模型的收敛,并有助于提高模型的性能和稳定性。 -
预测窗口:
在长时序预测(LSTF)设置中,逐步延长预测窗口大小。例如:- 在ETTh、ECL和Weather数据集中,预测窗口大小为{1天, 2天, 7天, 14天, 30天, 40天}。
- 在ETTm数据集中,预测窗口大小为{6小时, 12小时, 24小时, 72小时, 168小时}。
-
评价指标:
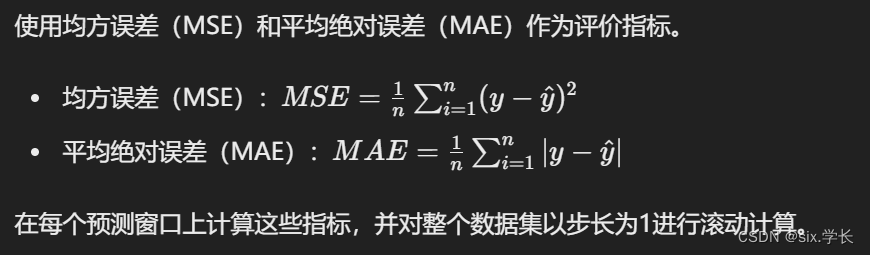
-
平台:
所有模型的训练和测试都在一台Nvidia V100 32GB GPU上进行。这确保了实验环境的一致性和高效性。
举例说明:
假设我们在ETTh数据集上进行超参数调优,具体步骤如下:
- 准备数据:将数据进行零均值归一化处理。
- 定义超参数空间:设置学习率为[ {1e-4, 1e-5, 1e-6} ],批量大小为[ {16, 32, 64} ]。
- 进行网格搜索:遍历所有学习率和批量大小的组合,训练模型并记录每个组合的性能。
- 训练模型:使用Adam优化器,初始学习率为1e-4,每2个epoch衰减10倍,总共训练10个epoch。对于每个超参数组合,训练模型并评估其在验证集上的MSE和MAE。
- 选择最佳超参数:选择在验证集上表现最好的超参数组合。
- 评估模型:使用最佳超参数组合,在测试集上评估模型的MSE和MAE,计算不同预测窗口大小下的性能。
通过这种方法,我们可以系统地找到最佳的超参数组合,从而提升模型的预测性能。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









