









这个图展示了 Informer 网络的具体组件和细节。我们将分成编码器(Encoder)、蒸馏模块(Distilling)、解码器(Decoder)和最终输出(Final)四个部分来解释。
编码器(Encoder)
-
输入(Inputs)
- 采用
1x3 Conv1d卷积层。 - 使用嵌入层(Embedding)将输入数据转换为维度为 d = 512 d = 512 d=512 的嵌入向量。
- 采用
-
概率稀疏自注意力块(ProbSparse Self-attention Block)
- 多头概率稀疏自注意力(Multi-head ProbSparse Attention),设定为 h = 16 h = 16 h=16, d = 32 d = 32 d=32。
- 添加(Add)、层归一化(LayerNorm)和 Dropout(p = 0.1)。
- 位置相关前馈网络(Pos-wise FFN),内部维度 d i n n e r = 2048 d_{inner} = 2048 dinner=2048,激活函数为 GELU。
- 再次添加(Add)、层归一化(LayerNorm)和 Dropout(p = 0.1)。
蒸馏模块(Distilling)
- 使用
1x3 conv1d和 ELU 激活函数。 - 进行最大池化(Max pooling),步幅(stride)为 2。
解码器(Decoder)
-
输入(Inputs)
- 同样采用
1x3 Conv1d卷积层。 - 嵌入层将输入数据转换为维度为 d = 512 d = 512 d=512 的嵌入向量。
- 同样采用
-
带掩码的概率稀疏自注意力块(Masked ProbSparse Self-attention Block)
- 在注意力块上添加掩码。
- 多头自注意力(Multi-head Attention),设定为 h = 8 h = 8 h=8, d = 64 d = 64 d=64。
- 添加(Add)、层归一化(LayerNorm)和 Dropout(p = 0.1)。
- 位置相关前馈网络(Pos-wise FFN),内部维度 d i n n e r = 2048 d_{inner} = 2048 dinner=2048,激活函数为 GELU。
- 再次添加(Add)、层归一化(LayerNorm)和 Dropout(p = 0.1)。
最终输出(Final)
- 使用全连接层(FCN),输出维度为 d = d o u t d = d_{out} d=dout。
举例说明
假设输入数据为一个长度为 N = 10 N = 10 N=10 的时间序列,每个时间步长包含 5 个特征。
-
编码器输入
- 初始输入大小为 ( 10 , 5 ) (10, 5) (10,5)。
- 经过
1x3 Conv1d卷积层,假设输出大小保持不变为 ( 10 , 5 ) (10, 5) (10,5)。 - 嵌入层将每个特征嵌入到 512 维度,得到 ( 10 , 512 ) (10, 512) (10,512)。
-
概率稀疏自注意力块
- 多头自注意力将输出大小调整为 ( 10 , 32 ) (10, 32) (10,32)。
- 位置相关前馈网络将每个特征调整为 2048 维度,然后通过 GELU 激活函数,再映射回 512 维度,大小仍然为 ( 10 , 512 ) (10, 512) (10,512)。
-
蒸馏模块
1x3 conv1d和 ELU 操作大小保持 ( 10 , 512 ) (10, 512) (10,512)。- 最大池化后,步幅为 2,得到 ( 5 , 512 ) (5, 512) (5,512)。
-
解码器输入
- 初始输入大小为 ( 5 , 512 ) (5, 512) (5,512)。
- 经过
1x3 Conv1d卷积层,大小保持 ( 5 , 512 ) (5, 512) (5,512)。
-
带掩码的自注意力块
- 多头自注意力调整大小为 ( 5 , 64 ) (5, 64) (5,64)。
- 位置相关前馈网络将每个特征调整为 2048 维度,然后通过 GELU 激活函数,再映射回 512 维度,大小仍然为 ( 5 , 512 ) (5, 512) (5,512)。
-
最终输出
- 全连接层将输出维度调整为所需的 d o u t d_{out} dout。
通过这些步骤,Informer 网络能够高效地处理和提取时间序列数据中的特征,并生成最终的预测结果。
输入-----卷积
详细解释并举例说明 1x3 Conv1d 卷积层的使用。
1x3 Conv1d 卷积层解释
在卷积神经网络中,1x3 Conv1d 指的是一维卷积操作,卷积核的大小为 1 行 3 列。这意味着在卷积操作时,卷积核会覆盖输入序列的 3 个连续元素。下面是具体步骤:
-
输入特征:假设输入是一个时间序列,每个时间步长包含 5 个特征,输入形状为 ( N , 5 ) (N, 5) (N,5),这里 N N N 是时间步的数量。
-
卷积操作:
- 卷积核大小:1x3
- 输入序列滑动窗口的大小是 3,这意味着卷积核在每一步会覆盖 3 个连续的特征,并产生一个输出值。
举例说明
假设我们的输入序列长度为 N = 10 N=10 N=10,每个时间步包含 5 个特征。输入数据可以表示为一个 10x5 的矩阵:
( x 11 x 12 x 13 x 14 x 15 x 21 x 22 x 23 x 24 x 25 x 31 x 32 x 33 x 34 x 35 ⋮ ⋮ ⋮ ⋮ ⋮ x 101 x 102 x 103 x 104 x 105 ) \begin{pmatrix} x_{11} & x_{12} & x_{13} & x_{14} & x_{15} \\ x_{21} & x_{22} & x_{23} & x_{24} & x_{25} \\ x_{31} & x_{32} & x_{33} & x_{34} & x_{35} \\ \vdots & \vdots & \vdots & \vdots & \vdots \\ x_{101} & x_{102} & x_{103} & x_{104} & x_{105} \end{pmatrix} x11x21x31⋮x101x12x22x32⋮x102x13x23x33⋮x103x14x24x34⋮x104x15x25x35⋮x105
卷积操作
假设我们有一个卷积核 K K K,大小为 1x3,权重分别为 w 1 , w 2 , w 3 w_1, w_2, w_3 w1,w2,w3。
-
第一步卷积:卷积核覆盖第 1 到第 3 列
输出 1 = x 11 ⋅ w 1 + x 12 ⋅ w 2 + x 13 ⋅ w 3 \text{输出}_{1} = x_{11} \cdot w_1 + x_{12} \cdot w_2 + x_{13} \cdot w_3 输出1=x11⋅w1+x12⋅w2+x13⋅w3 -
第二步卷积:卷积核滑动到第 2 到第 4 列
输出 2 = x 12 ⋅ w 1 + x 13 ⋅ w 2 + x 14 ⋅ w 3 \text{输出}_{2} = x_{12} \cdot w_1 + x_{13} \cdot w_2 + x_{14} \cdot w_3 输出2=x12⋅w1+x13⋅w2+x14⋅w3 -
第三步卷积:卷积核滑动到第 3 到第 5 列
输出 3 = x 13 ⋅ w 1 + x 14 ⋅ w 2 + x 15 ⋅ w 3 \text{输出}_{3} = x_{13} \cdot w_1 + x_{14} \cdot w_2 + x_{15} \cdot w_3 输出3=x13⋅w1+x14⋅w2+x15⋅w3
以此类推,直到卷积核覆盖到最后一个元素。
假设卷积层的输出通道数为 512,这意味着每次卷积操作会生成 512 个新的特征。因此,经过 1x3 Conv1d 卷积层后,输出的形状将是
(
N
,
512
)
(N, 512)
(N,512),其中
N
N
N 是时间步数。
具体数值举例
假设卷积核权重为 w 1 = 0.2 , w 2 = 0.5 , w 3 = 0.3 w_1 = 0.2, w_2 = 0.5, w_3 = 0.3 w1=0.2,w2=0.5,w3=0.3,输入特征为:
( 1 2 3 4 5 6 7 8 9 10 ) \begin{pmatrix} 1 & 2 & 3 & 4 & 5 \\ 6 & 7 & 8 & 9 & 10 \\ \end{pmatrix} (16273849510)
卷积操作如下:
-
第一步卷积:
输出 1 = 1 ⋅ 0.2 + 2 ⋅ 0.5 + 3 ⋅ 0.3 = 0.2 + 1.0 + 0.9 = 2.1 \text{输出}_{1} = 1 \cdot 0.2 + 2 \cdot 0.5 + 3 \cdot 0.3 = 0.2 + 1.0 + 0.9 = 2.1 输出1=1⋅0.2+2⋅0.5+3⋅0.3=0.2+1.0+0.9=2.1 -
第二步卷积:
输出 2 = 2 ⋅ 0.2 + 3 ⋅ 0.5 + 4 ⋅ 0.3 = 0.4 + 1.5 + 1.2 = 3.1 \text{输出}_{2} = 2 \cdot 0.2 + 3 \cdot 0.5 + 4 \cdot 0.3 = 0.4 + 1.5 + 1.2 = 3.1 输出2=2⋅0.2+3⋅0.5+4⋅0.3=0.4+1.5+1.2=3.1 -
第三步卷积:
输出 3 = 3 ⋅ 0.2 + 4 ⋅ 0.5 + 5 ⋅ 0.3 = 0.6 + 2.0 + 1.5 = 4.1 \text{输出}_{3} = 3 \cdot 0.2 + 4 \cdot 0.5 + 5 \cdot 0.3 = 0.6 + 2.0 + 1.5 = 4.1 输出3=3⋅0.2+4⋅0.5+5⋅0.3=0.6+2.0+1.5=4.1
通过这些操作,卷积核滑动覆盖输入序列的不同部分,生成对应的输出特征,这就是 1x3 Conv1d 卷积层的工作方式。
总之,1x3 Conv1d 卷积层通过一维卷积操作对输入数据进行特征提取,生成新的高维特征表示,为后续的网络层提供丰富的特征信息。
输入-----嵌入
嵌入层将输入数据转换为维度为 d = 512 d = 512 d=512 的嵌入向量
概述
嵌入层(Embedding Layer)是神经网络中的一个层,用于将离散的输入数据(如单词或时间步特征)映射到连续的高维向量空间。这种映射可以捕捉输入数据的语义或特征间的关系。在 Informer 模型中,嵌入层的输出向量维度设定为 512,这意味着每个输入数据点将被转换为一个 512 维的向量。
示例说明
假设输入数据为一个时间序列,长度为 10,每个时间步包含 5 个特征。输入数据可以表示为一个 10x5 的矩阵:
X = ( 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 ) \mathbf{X} = \begin{pmatrix} 1 & 2 & 3 & 4 & 5 \\ 6 & 7 & 8 & 9 & 10 \\ 11 & 12 & 13 & 14 & 15 \\ 16 & 17 & 18 & 19 & 20 \\ 21 & 22 & 23 & 24 & 25 \\ 26 & 27 & 28 & 29 & 30 \\ 31 & 32 & 33 & 34 & 35 \\ 36 & 37 & 38 & 39 & 40 \\ 41 & 42 & 43 & 44 & 45 \\ 46 & 47 & 48 & 49 & 50 \end{pmatrix} X= 1611162126313641462712172227323742473813182328333843484914192429343944495101520253035404550
嵌入层会将每个时间步的 5 个特征映射到一个 512 维的向量。这通常通过一个线性变换实现,例如通过一个全连接层。具体来说,对于每个时间步 i i i,包含的 5 个特征 ( x i 1 , x i 2 , x i 3 , x i 4 , x i 5 ) (x_{i1}, x_{i2}, x_{i3}, x_{i4}, x_{i5}) (xi1,xi2,xi3,xi4,xi5),嵌入层将它们转换为一个 512 维的向量 h i \mathbf{h}_i hi。
具体计算过程
假设嵌入矩阵为 W \mathbf{W} W,大小为 5x512,和一个偏置向量 b \mathbf{b} b,大小为 512。
对于时间步 i = 1 i = 1 i=1,输入向量为 ( 1 , 2 , 3 , 4 , 5 ) (1, 2, 3, 4, 5) (1,2,3,4,5),嵌入层的输出向量 h 1 \mathbf{h}_1 h1 计算如下:
h 1 = x 1 ⋅ W + b \mathbf{h}_1 = \mathbf{x}_1 \cdot \mathbf{W} + \mathbf{b} h1=x1⋅W+b
其中 x 1 = ( 1 , 2 , 3 , 4 , 5 ) \mathbf{x}_1 = (1, 2, 3, 4, 5) x1=(1,2,3,4,5), W \mathbf{W} W 是一个 5x512 的矩阵, b \mathbf{b} b 是一个 512 维的向量。
假设部分权重和偏置如下:
W = ( 0.1 0.2 ⋯ 0.1 0.2 0.1 ⋯ 0.2 0.3 0.4 ⋯ 0.3 0.4 0.3 ⋯ 0.4 0.5 0.2 ⋯ 0.5 ) \mathbf{W} = \begin{pmatrix} 0.1 & 0.2 & \cdots & 0.1 \\ 0.2 & 0.1 & \cdots & 0.2 \\ 0.3 & 0.4 & \cdots & 0.3 \\ 0.4 & 0.3 & \cdots & 0.4 \\ 0.5 & 0.2 & \cdots & 0.5 \end{pmatrix} W= 0.10.20.30.40.50.20.10.40.30.2⋯⋯⋯⋯⋯0.10.20.30.40.5
b = ( 0.1 0.1 ⋮ 0.1 ) \mathbf{b} = \begin{pmatrix} 0.1 \\ 0.1 \\ \vdots \\ 0.1 \end{pmatrix} b= 0.10.1⋮0.1
计算得到的 h 1 \mathbf{h}_1 h1 的部分值为:
h 1 = ( 1 , 2 , 3 , 4 , 5 ) ⋅ W + b \mathbf{h}_1 = (1, 2, 3, 4, 5) \cdot \mathbf{W} + \mathbf{b} h1=(1,2,3,4,5)⋅W+b
= ( 1 ⋅ 0.1 + 2 ⋅ 0.2 + 3 ⋅ 0.3 + 4 ⋅ 0.4 + 5 ⋅ 0.5 , 1 ⋅ 0.2 + 2 ⋅ 0.1 + 3 ⋅ 0.4 + 4 ⋅ 0.3 + 5 ⋅ 0.2 , ⋯ ) + b = (1 \cdot 0.1 + 2 \cdot 0.2 + 3 \cdot 0.3 + 4 \cdot 0.4 + 5 \cdot 0.5, 1 \cdot 0.2 + 2 \cdot 0.1 + 3 \cdot 0.4 + 4 \cdot 0.3 + 5 \cdot 0.2, \cdots) + \mathbf{b} =(1⋅0.1+2⋅0.2+3⋅0.3+4⋅0.4+5⋅0.5,1⋅0.2+2⋅0.1+3⋅0.4+4⋅0.3+5⋅0.2,⋯)+b
= ( 5.5 , 3.5 , ⋯ ) + ( 0.1 , 0.1 , ⋯ ) = (5.5, 3.5, \cdots) + (0.1, 0.1, \cdots) =(5.5,3.5,⋯)+(0.1,0.1,⋯)
= ( 5.6 , 3.6 , ⋯ ) = (5.6, 3.6, \cdots) =(5.6,3.6,⋯)
最终,每个时间步 i i i 都会被映射到一个 512 维的向量,形成一个新的矩阵 H \mathbf{H} H,大小为 10x512。
总结
嵌入层的主要作用是将输入数据转换为高维嵌入向量,在 Informer 模型中,输出维度为 512,这种高维度表示可以更好地捕捉输入数据的特征和语义关系。
概率稀疏自注意力块
多头概率稀疏自注意力(Multi-head ProbSparse Attention)
概述
多头概率稀疏自注意力(Multi-head ProbSparse Attention)是一种改进的自注意力机制,旨在提高模型在处理长序列数据时的效率。具体来说,它通过概率稀疏化的方式减少计算复杂度,同时保留了关键的注意力信息。
在 Informer 模型中,这个机制的参数设置为:
- 头的数量( h h h)为 16
- 每个头的维度( d d d)为 32
详细解释
- 自注意力机制(Self-attention Mechanism)
自注意力机制的核心思想是让每个输入元素(比如时间序列中的一个时间步)都能与所有其他输入元素进行交互和“注意”,从而生成一个新的表示。具体来说,自注意力计算公式如下:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
其中, Q Q Q(Query)、 K K K(Key)和 V V V(Value)是通过线性变换从输入向量中得到的, d k d_k dk 是 K K K 的维度。
- 多头注意力机制(Multi-head Attention Mechanism)
多头注意力机制通过并行使用多个自注意力头,使得模型能够从不同的表示子空间中学习更加丰富的特征。每个头都有自己的一组 Q , K , V Q, K, V Q,K,V 矩阵,然后将所有头的输出拼接在一起,并通过一个线性变换生成最终的输出。
MultiHead ( Q , K , V ) = Concat ( head 1 , head 2 , … , head h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \text{head}_2, \ldots, \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,head2,…,headh)WO
每个头的计算如下:
head i = Attention ( Q W i Q , K W i K , V W i V ) \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) headi=Attention(QWiQ,KWiK,VWiV)
- 概率稀疏化(ProbSparse)
概率稀疏化的目标是减少计算复杂度。标准的自注意力机制需要计算所有查询和键之间的相似度,计算量为 O ( N 2 ) O(N^2) O(N2),其中 N N N 是序列长度。概率稀疏化通过引入稀疏矩阵,选择性地计算重要的注意力权重,从而将复杂度降低到 O ( N log N ) O(N \log N) O(NlogN)。
- 设定参数 h = 16 , d = 32 h = 16, d = 32 h=16,d=32
在 Informer 模型中,使用了 16 个注意力头( h = 16 h = 16 h=16),每个头的维度为 32( d = 32 d = 32 d=32)。这意味着:
- 输入向量会被分成 16 份,每份的维度为 32。
- 每个注意力头独立地计算自注意力,然后将结果拼接在一起。
具体数值举例
假设输入序列长度 N = 10 N = 10 N=10,输入向量维度为 512。我们将这些向量通过线性变换得到 Q , K , V Q, K, V Q,K,V,然后进行多头自注意力计算。
-
线性变换
- Q , K , V Q, K, V Q,K,V 的维度为 ( 10 , 512 ) (10, 512) (10,512)。
- 将其分为 16 个头,每个头的维度为 32,得到的 Q , K , V Q, K, V Q,K,V 矩阵大小为 ( 10 , 32 ) (10, 32) (10,32)。
-
每个头的注意力计算
- 对于第一个头,计算注意力:
Q 1 = X W 1 Q , K 1 = X W 1 K , V 1 = X W 1 V Q_1 = XW_1^Q, \quad K_1 = XW_1^K, \quad V_1 = XW_1^V Q1=XW1Q,K1=XW1K,V1=XW1V
- 假设 Q 1 , K 1 , V 1 Q_1, K_1, V_1 Q1,K1,V1 的值分别为(假设 W W W 矩阵和偏置项被省略):
Q 1 = ( q 11 q 12 ⋯ q 132 q 21 q 22 ⋯ q 232 ⋮ ⋮ ⋱ ⋮ q 101 q 102 ⋯ q 1032 ) , K 1 = ( k 11 k 12 ⋯ k 132 k 21 k 22 ⋯ k 232 ⋮ ⋮ ⋱ ⋮ k 101 k 102 ⋯ k 1032 ) , V 1 = ( v 11 v 12 ⋯ v 132 v 21 v 22 ⋯ v 232 ⋮ ⋮ ⋱ ⋮ v 101 v 102 ⋯ v 1032 ) Q_1 = \begin{pmatrix} q_{11} & q_{12} & \cdots & q_{132} \\ q_{21} & q_{22} & \cdots & q_{232} \\ \vdots & \vdots & \ddots & \vdots \\ q_{101} & q_{102} & \cdots & q_{1032} \end{pmatrix}, \quad K_1 = \begin{pmatrix} k_{11} & k_{12} & \cdots & k_{132} \\ k_{21} & k_{22} & \cdots & k_{232} \\ \vdots & \vdots & \ddots & \vdots \\ k_{101} & k_{102} & \cdots & k_{1032} \end{pmatrix}, \quad V_1 = \begin{pmatrix} v_{11} & v_{12} & \cdots & v_{132} \\ v_{21} & v_{22} & \cdots & v_{232} \\ \vdots & \vdots & \ddots & \vdots \\ v_{101} & v_{102} & \cdots & v_{1032} \end{pmatrix} Q1= q11q21⋮q101q12q22⋮q102⋯⋯⋱⋯q132q232⋮q1032 ,K1= k11k21⋮k101k12k22⋮k102⋯⋯⋱⋯k132k232⋮k1032 ,V1= v11v21⋮v101v12v22⋮v102⋯⋯⋱⋯v132v232⋮v1032
- 计算注意力权重:
Attention ( Q 1 , K 1 , V 1 ) = softmax ( Q 1 K 1 T 32 ) V 1 \text{Attention}(Q_1, K_1, V_1) = \text{softmax}\left(\frac{Q_1 K_1^T}{\sqrt{32}}\right)V_1 Attention(Q1,K1,V1)=softmax(32Q1K1T)V1
- 拼接输出
- 将 16 个头的输出拼接在一起,得到的最终输出大小为 ( 10 , 512 ) (10, 512) (10,512)。
通过多头概率稀疏自注意力机制,Informer 模型能够高效地处理长序列数据,同时保留重要的注意力信息。
添加(Add)、层归一化(LayerNorm)和 Dropout(p = 0.1)
好的,我们来详细解释添加(Add)、层归一化(LayerNorm)和 Dropout(p = 0.1)这些关键词,并通过具体数值举例说明它们在神经网络中的作用和计算过程。
1. 添加(Add)
在神经网络中,添加(Add)操作通常用于将不同层的输出进行元素级加法。通常情况下,它与残差连接(Residual Connection)一起使用,使得输入和输出可以进行直接的元素级相加,帮助训练更深的网络。
2. 层归一化(LayerNorm)
层归一化(Layer Normalization)是一个正则化技术,用于归一化每个样本在批次中的每一层的输出。这种方法通过标准化来稳定和加速训练过程,具体计算公式为:
x ^ = x − μ σ + ϵ \hat{x} = \frac{x - \mu}{\sigma + \epsilon} x^=σ+ϵx−μ
其中, μ \mu μ 是输入的均值, σ \sigma σ 是输入的标准差, ϵ \epsilon ϵ 是一个小常数,用于防止除零。
3. Dropout(p = 0.1)
Dropout 是一种防止神经网络过拟合的技术。在训练过程中,它随机地将一部分神经元的输出设置为零,按照概率 p p p 来执行这种操作,从而使模型更具泛化能力。在这里, p = 0.1 p = 0.1 p=0.1 表示 10% 的神经元输出会被置零。
举例说明
假设我们有一个神经网络层,输入向量为:
x = [ 1.0 , 2.0 , 3.0 , 4.0 ] \mathbf{x} = [1.0, 2.0, 3.0, 4.0] x=[1.0,2.0,3.0,4.0]
经过一层神经网络后,输出为:
h = [ 0.5 , 1.5 , 2.5 , 3.5 ] \mathbf{h} = [0.5, 1.5, 2.5, 3.5] h=[0.5,1.5,2.5,3.5]
添加(Add)
我们使用残差连接,将输入 x \mathbf{x} x 和输出 h \mathbf{h} h 相加:
z = x + h = [ 1.0 + 0.5 , 2.0 + 1.5 , 3.0 + 2.5 , 4.0 + 3.5 ] = [ 1.5 , 3.5 , 5.5 , 7.5 ] \mathbf{z} = \mathbf{x} + \mathbf{h} = [1.0 + 0.5, 2.0 + 1.5, 3.0 + 2.5, 4.0 + 3.5] = [1.5, 3.5, 5.5, 7.5] z=x+h=[1.0+0.5,2.0+1.5,3.0+2.5,4.0+3.5]=[1.5,3.5,5.5,7.5]
层归一化(LayerNorm)
对于向量 z = [ 1.5 , 3.5 , 5.5 , 7.5 ] \mathbf{z} = [1.5, 3.5, 5.5, 7.5] z=[1.5,3.5,5.5,7.5],计算其均值和标准差:
μ = 1.5 + 3.5 + 5.5 + 7.5 4 = 4.5 \mu = \frac{1.5 + 3.5 + 5.5 + 7.5}{4} = 4.5 μ=41.5+3.5+5.5+7.5=4.5
σ = ( 1.5 − 4.5 ) 2 + ( 3.5 − 4.5 ) 2 + ( 5.5 − 4.5 ) 2 + ( 7.5 − 4.5 ) 2 4 = 9 + 1 + 1 + 9 4 = 5 ≈ 2.236 \sigma = \sqrt{\frac{(1.5 - 4.5)^2 + (3.5 - 4.5)^2 + (5.5 - 4.5)^2 + (7.5 - 4.5)^2}{4}} = \sqrt{\frac{9 + 1 + 1 + 9}{4}} = \sqrt{5} \approx 2.236 σ=4(1.5−4.5)2+(3.5−4.5)2+(5.5−4.5)2+(7.5−4.5)2=49+1+1+9=5≈2.236
归一化输出:
z ^ = z − μ σ + ϵ = [ 1.5 − 4.5 2.236 , 3.5 − 4.5 2.236 , 5.5 − 4.5 2.236 , 7.5 − 4.5 2.236 ] ≈ [ − 1.34 , − 0.45 , 0.45 , 1.34 ] \hat{\mathbf{z}} = \frac{\mathbf{z} - \mu}{\sigma + \epsilon} = \left[\frac{1.5 - 4.5}{2.236}, \frac{3.5 - 4.5}{2.236}, \frac{5.5 - 4.5}{2.236}, \frac{7.5 - 4.5}{2.236}\right] \approx [-1.34, -0.45, 0.45, 1.34] z^=σ+ϵz−μ=[2.2361.5−4.5,2.2363.5−4.5,2.2365.5−4.5,2.2367.5−4.5]≈[−1.34,−0.45,0.45,1.34]
Dropout(p = 0.1)
假设我们应用 Dropout,概率 p = 0.1 p = 0.1 p=0.1,表示有 10% 的神经元会被随机设置为零。在这里,假设我们随机将第二个元素设置为零:
z ^ ′ = [ − 1.34 , 0 , 0.45 , 1.34 ] \hat{\mathbf{z}}' = [-1.34, 0, 0.45, 1.34] z^′=[−1.34,0,0.45,1.34]
总结
通过这个示例,我们详细解释了添加(Add)、层归一化(LayerNorm)和 Dropout(p = 0.1)的作用和计算过程:
- 添加(Add):用于残差连接,帮助训练深层网络。
- 层归一化(LayerNorm):通过标准化每层的输出来稳定和加速训练。
- Dropout(p = 0.1):通过随机将部分神经元输出设置为零来防止过拟合,提高模型的泛化能力。
这些技术的组合使用可以有效提升神经网络的训练效果和性能。
位置相关前馈网络(Pos-wise FFN)
概述
位置相关前馈网络(Position-wise Feed-Forward Network, FFN)是 Transformer 模型中的一个关键组件,它独立地对每个时间步的位置进行处理。它的主要作用是通过一系列的线性变换和非线性激活函数,对输入的每个位置进行特征提取和转换。
具体内容
- 内部维度( d inner = 2048 d_{\text{inner}} = 2048 dinner=2048):指的是前馈网络中隐藏层的大小。在这一层中,输入向量会被映射到一个 2048 维的空间。
- 激活函数为 GELU:GELU(Gaussian Error Linear Unit)是一种非线性激活函数,能够更好地处理复杂的特征。其公式为:
GELU ( x ) = x ⋅ Φ ( x ) \text{GELU}(x) = x \cdot \Phi(x) GELU(x)=x⋅Φ(x)
其中, Φ ( x ) \Phi(x) Φ(x) 是标准正态分布的累积分布函数。
工作原理
- 输入向量:假设输入向量的维度为 d model = 512 d_{\text{model}} = 512 dmodel=512。
- 线性变换和激活:首先,输入向量会通过一个线性变换映射到内部维度( d inner = 2048 d_{\text{inner}} = 2048 dinner=2048),然后通过 GELU 激活函数。
- 线性变换:经过激活函数处理后的向量再通过另一个线性变换映射回原始维度( d model = 512 d_{\text{model}} = 512 dmodel=512)。
具体数值举例
假设我们有一个输入向量 x \mathbf{x} x,其维度为 512:
x = [ x 1 , x 2 , x 3 , … , x 512 ] \mathbf{x} = [x_1, x_2, x_3, \ldots, x_{512}] x=[x1,x2,x3,…,x512]
- 线性变换和激活
首先,输入向量 x \mathbf{x} x 会通过一个线性变换映射到 2048 维度:
W 1 ∈ R 512 × 2048 , b 1 ∈ R 2048 \mathbf{W}_1 \in \mathbb{R}^{512 \times 2048}, \quad \mathbf{b}_1 \in \mathbb{R}^{2048} W1∈R512×2048,b1∈R2048
h = x ⋅ W 1 + b 1 \mathbf{h} = \mathbf{x} \cdot \mathbf{W}_1 + \mathbf{b}_1 h=x⋅W1+b1
假设 W 1 \mathbf{W}_1 W1 和 b 1 \mathbf{b}_1 b1 的部分值为:
W 1 = ( 0.1 0.2 ⋯ 0.1 0.3 0.4 ⋯ 0.3 ⋮ ⋮ ⋱ ⋮ 0.5 0.6 ⋯ 0.5 ) , b 1 = [ 0.1 , 0.1 , … , 0.1 ] \mathbf{W}_1 = \begin{pmatrix} 0.1 & 0.2 & \cdots & 0.1 \\ 0.3 & 0.4 & \cdots & 0.3 \\ \vdots & \vdots & \ddots & \vdots \\ 0.5 & 0.6 & \cdots & 0.5 \end{pmatrix}, \quad \mathbf{b}_1 = [0.1, 0.1, \ldots, 0.1] W1= 0.10.3⋮0.50.20.4⋮0.6⋯⋯⋱⋯0.10.3⋮0.5 ,b1=[0.1,0.1,…,0.1]
计算得到的 h \mathbf{h} h 为:
h = [ h 1 , h 2 , h 3 , … , h 2048 ] \mathbf{h} = [h_1, h_2, h_3, \ldots, h_{2048}] h=[h1,h2,h3,…,h2048]
然后通过 GELU 激活函数:
h GELU = GELU ( h ) = [ GELU ( h 1 ) , GELU ( h 2 ) , … , GELU ( h 2048 ) ] \mathbf{h}_{\text{GELU}} = \text{GELU}(\mathbf{h}) = [\text{GELU}(h_1), \text{GELU}(h_2), \ldots, \text{GELU}(h_{2048})] hGELU=GELU(h)=[GELU(h1),GELU(h2),…,GELU(h2048)]
- 线性变换
经过激活函数处理后的向量再通过另一个线性变换映射回 512 维度:
W 2 ∈ R 2048 × 512 , b 2 ∈ R 512 \mathbf{W}_2 \in \mathbb{R}^{2048 \times 512}, \quad \mathbf{b}_2 \in \mathbb{R}^{512} W2∈R2048×512,b2∈R512
y = h GELU ⋅ W 2 + b 2 \mathbf{y} = \mathbf{h}_{\text{GELU}} \cdot \mathbf{W}_2 + \mathbf{b}_2 y=hGELU⋅W2+b2
假设 W 2 \mathbf{W}_2 W2 和 b 2 \mathbf{b}_2 b2 的部分值为:
W 2 = ( 0.1 0.2 ⋯ 0.1 0.3 0.4 ⋯ 0.3 ⋮ ⋮ ⋱ ⋮ 0.5 0.6 ⋯ 0.5 ) , b 2 = [ 0.1 , 0.1 , … , 0.1 ] \mathbf{W}_2 = \begin{pmatrix} 0.1 & 0.2 & \cdots & 0.1 \\ 0.3 & 0.4 & \cdots & 0.3 \\ \vdots & \vdots & \ddots & \vdots \\ 0.5 & 0.6 & \cdots & 0.5 \end{pmatrix}, \quad \mathbf{b}_2 = [0.1, 0.1, \ldots, 0.1] W2= 0.10.3⋮0.50.20.4⋮0.6⋯⋯⋱⋯0.10.3⋮0.5 ,b2=[0.1,0.1,…,0.1]
最终输出向量 y \mathbf{y} y 为:
y = [ y 1 , y 2 , y 3 , … , y 512 ] \mathbf{y} = [y_1, y_2, y_3, \ldots, y_{512}] y=[y1,y2,y3,…,y512]
总结
位置相关前馈网络(Pos-wise FFN)通过两次线性变换和一次非线性激活函数(GELU)对每个输入位置进行独立处理。首先,它将输入向量映射到高维空间(2048 维),然后通过 GELU 激活函数,最后再映射回原始维度(512 维),从而实现对输入特征的非线性转换和丰富的特征提取。
再一次添加(Add)、层归一化(LayerNorm)和 Dropout(p = 0.1)是为了加强模型的稳定性、提高训练的效果和防止过拟合。我们逐一解释这些操作的原因及其作用。
再次添加(Add)、层归一化(LayerNorm)和 Dropout(p = 0.1)
再次添加(Add)
添加操作通常与残差连接(Residual Connection)一起使用。残差连接最初在 ResNet 中提出,旨在解决深层网络中的梯度消失和梯度爆炸问题。通过将输入直接添加到输出中,残差连接能够帮助梯度更有效地传播,减轻训练深层网络的难度。具体来说,残差连接可以:
- 帮助梯度流动:减少梯度消失和梯度爆炸的问题,使得深层网络更容易训练。
- 保持信息传递:确保原始输入的信息在经过多层非线性变换后仍然保留,从而提高模型的表达能力。
在 Transformer 中,残差连接将输入 x \mathbf{x} x 添加到前馈网络或注意力层的输出 h \mathbf{h} h 中:
z = x + h \mathbf{z} = \mathbf{x} + \mathbf{h} z=x+h
再次层归一化(LayerNorm)
层归一化(LayerNorm)在每次非线性变换后进行,目的是对每层的输出进行标准化。再次进行层归一化可以进一步稳定训练过程。具体原因如下:
- 稳定训练:标准化每层输出的数据分布,减少不同层之间的不协调,有助于加速收敛。
- 减少内部协变量偏移:使每层的输入保持相对稳定,减轻网络对参数初始化和学习率的敏感性。
每次添加(Add)和 Dropout 操作后进行层归一化,可以确保即使添加了噪声或随机失活,输出仍然是标准化的。
再次 Dropout(p = 0.1)
Dropout 是一种正则化技术,通过随机失活部分神经元来防止过拟合。再一次应用 Dropout 可以增加模型的鲁棒性。具体原因如下:
- 防止过拟合:通过随机失活部分神经元,迫使模型在训练过程中不能过度依赖某些特定的神经元,从而提高模型的泛化能力。
- 增强鲁棒性:使模型更能适应训练数据的多样性和随机性。
在每次添加(Add)和层归一化后应用 Dropout,有助于在不同的网络层中引入随机性,从而使模型更加健壮。
具体数值举例
假设我们有一个输入向量 x \mathbf{x} x:
x = [ 1.0 , 2.0 , 3.0 , 4.0 ] \mathbf{x} = [1.0, 2.0, 3.0, 4.0] x=[1.0,2.0,3.0,4.0]
经过前馈网络后,输出为:
h = [ 0.5 , 1.5 , 2.5 , 3.5 ] \mathbf{h} = [0.5, 1.5, 2.5, 3.5] h=[0.5,1.5,2.5,3.5]
添加(Add)
使用残差连接将 x \mathbf{x} x 和 h \mathbf{h} h 相加:
z = x + h = [ 1.0 + 0.5 , 2.0 + 1.5 , 3.0 + 2.5 , 4.0 + 3.5 ] = [ 1.5 , 3.5 , 5.5 , 7.5 ] \mathbf{z} = \mathbf{x} + \mathbf{h} = [1.0 + 0.5, 2.0 + 1.5, 3.0 + 2.5, 4.0 + 3.5] = [1.5, 3.5, 5.5, 7.5] z=x+h=[1.0+0.5,2.0+1.5,3.0+2.5,4.0+3.5]=[1.5,3.5,5.5,7.5]
层归一化(LayerNorm)
计算 z \mathbf{z} z 的均值和标准差:
μ = 1.5 + 3.5 + 5.5 + 7.5 4 = 4.5 \mu = \frac{1.5 + 3.5 + 5.5 + 7.5}{4} = 4.5 μ=41.5+3.5+5.5+7.5=4.5
σ = ( 1.5 − 4.5 ) 2 + ( 3.5 − 4.5 ) 2 + ( 5.5 − 4.5 ) 2 + ( 7.5 − 4.5 ) 2 4 = 9 + 1 + 1 + 9 4 = 5 ≈ 2.236 \sigma = \sqrt{\frac{(1.5 - 4.5)^2 + (3.5 - 4.5)^2 + (5.5 - 4.5)^2 + (7.5 - 4.5)^2}{4}} = \sqrt{\frac{9 + 1 + 1 + 9}{4}} = \sqrt{5} \approx 2.236 σ=4(1.5−4.5)2+(3.5−4.5)2+(5.5−4.5)2+(7.5−4.5)2=49+1+1+9=5≈2.236
归一化输出:
z ^ = z − μ σ + ϵ = [ 1.5 − 4.5 2.236 , 3.5 − 4.5 2.236 , 5.5 − 4.5 2.236 , 7.5 − 4.5 2.236 ] ≈ [ − 1.34 , − 0.45 , 0.45 , 1.34 ] \hat{\mathbf{z}} = \frac{\mathbf{z} - \mu}{\sigma + \epsilon} = \left[\frac{1.5 - 4.5}{2.236}, \frac{3.5 - 4.5}{2.236}, \frac{5.5 - 4.5}{2.236}, \frac{7.5 - 4.5}{2.236}\right] \approx [-1.34, -0.45, 0.45, 1.34] z^=σ+ϵz−μ=[2.2361.5−4.5,2.2363.5−4.5,2.2365.5−4.5,2.2367.5−4.5]≈[−1.34,−0.45,0.45,1.34]
Dropout(p = 0.1)
假设我们应用 Dropout,概率 p = 0.1 p = 0.1 p=0.1,表示有 10% 的神经元会被随机设置为零。在这里,假设我们随机将第二个元素设置为零:
z ^ ′ = [ − 1.34 , 0 , 0.45 , 1.34 ] \hat{\mathbf{z}}' = [-1.34, 0, 0.45, 1.34] z^′=[−1.34,0,0.45,1.34]
总结
再一次添加(Add)、层归一化(LayerNorm)和 Dropout(p = 0.1)是为了增强模型的稳定性、提高训练的效果和防止过拟合。这些操作的组合使用能够确保神经网络在处理复杂任务时保持良好的性能和泛化能力。
好的,让我们详细解释 1x3 Conv1d 和 ELU 激活函数的具体作用和实现过程,并通过具体数据举例说明。
1x3 Conv1d 卷积层
1x3 Conv1d 是一个一维卷积层,卷积核的大小为 1 行 3 列。这意味着在卷积操作时,卷积核会覆盖输入序列的 3 个连续元素,并对其进行卷积操作,生成一个新的特征。
具体步骤
- 输入特征:假设输入是一个时间序列,每个时间步长包含 5 个特征,输入形状为 ( N , C in ) (N, C_{\text{in}}) (N,Cin),其中 N N N 是时间步数, C in C_{\text{in}} Cin 是每个时间步的特征数。
- 卷积核:卷积核的大小为 1x3,表示它覆盖 3 个连续的特征。
- 输出特征:经过卷积操作后,生成新的特征,输出形状为 ( N − 2 , C out ) (N-2, C_{\text{out}}) (N−2,Cout),其中 C out C_{\text{out}} Cout 是输出特征的数量。
ELU 激活函数
ELU(Exponential Linear Unit)是一种非线性激活函数,能够在深层网络中提供更好的性能和训练稳定性。ELU 的定义如下:
ELU ( x ) = { x , if x > 0 α ( e x − 1 ) , if x ≤ 0 \text{ELU}(x) = \begin{cases} x, & \text{if } x > 0 \\ \alpha (e^x - 1), & \text{if } x \leq 0 \end{cases} ELU(x)={x,α(ex−1),if x>0if x≤0
其中, α \alpha α 是一个超参数,通常设定为 1。
举例说明
假设我们有一个输入时间序列,长度为 N = 5 N = 5 N=5,每个时间步包含 5 个特征。输入数据可以表示为一个 5x5 的矩阵:
X = ( 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 ) \mathbf{X} = \begin{pmatrix} 1 & 2 & 3 & 4 & 5 \\ 6 & 7 & 8 & 9 & 10 \\ 11 & 12 & 13 & 14 & 15 \\ 16 & 17 & 18 & 19 & 20 \\ 21 & 22 & 23 & 24 & 25 \end{pmatrix} X= 16111621271217223813182349141924510152025
1x3 conv1d` 和 ELU 激活函数
1x3 Conv1d 卷积操作
假设卷积核大小为 1x3,权重分别为 w 1 , w 2 , w 3 w_1, w_2, w_3 w1,w2,w3。我们应用卷积操作,生成新的特征。
卷积操作
-
第一步卷积:卷积核覆盖第 1 到第 3 列
输出 1 = x 11 ⋅ w 1 + x 12 ⋅ w 2 + x 13 ⋅ w 3 \text{输出}_{1} = x_{11} \cdot w_1 + x_{12} \cdot w_2 + x_{13} \cdot w_3 输出1=x11⋅w1+x12⋅w2+x13⋅w3 -
第二步卷积:卷积核滑动到第 2 到第 4 列
输出 2 = x 12 ⋅ w 1 + x 13 ⋅ w 2 + x 14 ⋅ w 3 \text{输出}_{2} = x_{12} \cdot w_1 + x_{13} \cdot w_2 + x_{14} \cdot w_3 输出2=x12⋅w1+x13⋅w2+x14⋅w3 -
第三步卷积:卷积核滑动到第 3 到第 5 列
输出 3 = x 13 ⋅ w 1 + x 14 ⋅ w 2 + x 15 ⋅ w 3 \text{输出}_{3} = x_{13} \cdot w_1 + x_{14} \cdot w_2 + x_{15} \cdot w_3 输出3=x13⋅w1+x14⋅w2+x15⋅w3
以此类推,直到卷积核覆盖到最后一个元素。
假设卷积核权重为 w 1 = 0.2 , w 2 = 0.5 , w 3 = 0.3 w_1 = 0.2, w_2 = 0.5, w_3 = 0.3 w1=0.2,w2=0.5,w3=0.3,输入特征为:
X = ( 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 ) \mathbf{X} = \begin{pmatrix} 1 & 2 & 3 & 4 & 5 \\ 6 & 7 & 8 & 9 & 10 \\ 11 & 12 & 13 & 14 & 15 \\ 16 & 17 & 18 & 19 & 20 \\ 21 & 22 & 23 & 24 & 25 \end{pmatrix} X= 16111621271217223813182349141924510152025
卷积操作如下:
-
第一步卷积:
输出 1 = 1 ⋅ 0.2 + 2 ⋅ 0.5 + 3 ⋅ 0.3 = 0.2 + 1.0 + 0.9 = 2.1 \text{输出}_{1} = 1 \cdot 0.2 + 2 \cdot 0.5 + 3 \cdot 0.3 = 0.2 + 1.0 + 0.9 = 2.1 输出1=1⋅0.2+2⋅0.5+3⋅0.3=0.2+1.0+0.9=2.1 -
第二步卷积:
输出 2 = 2 ⋅ 0.2 + 3 ⋅ 0.5 + 4 ⋅ 0.3 = 0.4 + 1.5 + 1.2 = 3.1 \text{输出}_{2} = 2 \cdot 0.2 + 3 \cdot 0.5 + 4 \cdot 0.3 = 0.4 + 1.5 + 1.2 = 3.1 输出2=2⋅0.2+3⋅0.5+4⋅0.3=0.4+1.5+1.2=3.1 -
第三步卷积:
输出 3 = 3 ⋅ 0.2 + 4 ⋅ 0.5 + 5 ⋅ 0.3 = 0.6 + 2.0 + 1.5 = 4.1 \text{输出}_{3} = 3 \cdot 0.2 + 4 \cdot 0.5 + 5 \cdot 0.3 = 0.6 + 2.0 + 1.5 = 4.1 输出3=3⋅0.2+4⋅0.5+5⋅0.3=0.6+2.0+1.5=4.1 -
第四步卷积:
输出 4 = 6 ⋅ 0.2 + 7 ⋅ 0.5 + 8 ⋅ 0.3 = 1.2 + 3.5 + 2.4 = 7.1 \text{输出}_{4} = 6 \cdot 0.2 + 7 \cdot 0.5 + 8 \cdot 0.3 = 1.2 + 3.5 + 2.4 = 7.1 输出4=6⋅0.2+7⋅0.5+8⋅0.3=1.2+3.5+2.4=7.1 -
第五步卷积:
输出 5 = 7 ⋅ 0.2 + 8 ⋅ 0.5 + 9 ⋅ 0.3 = 1.4 + 4.0 + 2.7 = 8.1 \text{输出}_{5} = 7 \cdot 0.2 + 8 \cdot 0.5 + 9 \cdot 0.3 = 1.4 + 4.0 + 2.7 = 8.1 输出5=7⋅0.2+8⋅0.5+9⋅0.3=1.4+4.0+2.7=8.1
ELU 激活函数
应用 ELU 激活函数处理卷积输出。
ELU ( x ) = { x , if x > 0 α ( e x − 1 ) , if x ≤ 0 \text{ELU}(x) = \begin{cases} x, & \text{if } x > 0 \\ \alpha (e^x - 1), & \text{if } x \leq 0 \end{cases} ELU(x)={x,α(ex−1),if x>0if x≤0
假设 α = 1 \alpha = 1 α=1,对于每个输出:
-
输出 1:
ELU ( 2.1 ) = 2.1 \text{ELU}(2.1) = 2.1 ELU(2.1)=2.1 -
输出 2:
ELU ( 3.1 ) = 3.1 \text{ELU}(3.1) = 3.1 ELU(3.1)=3.1 -
输出 3:
ELU ( 4.1 ) = 4.1 \text{ELU}(4.1) = 4.1 ELU(4.1)=4.1 -
输出 4:
ELU ( 7.1 ) = 7.1 \text{ELU}(7.1) = 7.1 ELU(7.1)=7.1 -
输出 5:
ELU ( 8.1 ) = 8.1 \text{ELU}(8.1) = 8.1 ELU(8.1)=8.1
如果输出为负值,例如假设某个输出为 -0.5:
ELU ( − 0.5 ) = α ( e − 0.5 − 1 ) = 1 ( 0.6065 − 1 ) = − 0.3935 \text{ELU}(-0.5) = \alpha (e^{-0.5} - 1) = 1 (0.6065 - 1) = -0.3935 ELU(−0.5)=α(e−0.5−1)=1(0.6065−1)=−0.3935
总结
通过 1x3 Conv1d 卷积层,输入的时间序列被转换为新的特征表示。ELU 激活函数进一步处理这些特征,通过非线性变换增强模型的表达能力。这两个步骤的结合,使得模型能够更好地捕捉输入数据中的复杂模式和关系。
在注意力块上添加掩码
掩码(Masking)在注意力机制中的作用
在自注意力机制中,掩码(masking)主要用于两个目的:
- 遮挡未来信息(在解码器中):确保模型在预测下一个词时,只能看到当前词及其之前的词,而不能看到未来的信息。这对于序列到序列的任务(如机器翻译)非常重要。
- 处理变长序列:在处理变长序列时,掩码用于忽略填充的部分,使得模型只关注实际有效的部分。
具体步骤
我们以遮挡未来信息为例来详细解释。在 Transformer 解码器中,使用掩码来确保当前时间步只能关注之前的时间步。
1. 输入序列
假设我们有一个输入序列,长度为 4:
X = ( x 1 x 2 x 3 x 4 ) \mathbf{X} = \begin{pmatrix} x_1 & x_2 & x_3 & x_4 \end{pmatrix} X=(x1x2x3x4)
2. 查询(Query)、键(Key)和值(Value)
首先,输入序列通过线性变换生成查询(Query)、键(Key)和值(Value)矩阵:
Q = X W Q , K = X W K , V = X W V Q = \mathbf{X}W_Q, \quad K = \mathbf{X}W_K, \quad V = \mathbf{X}W_V Q=XWQ,K=XWK,V=XWV
假设 Q , K , V Q, K, V Q,K,V 的维度都为 4×4:
Q = ( q 11 q 12 q 13 q 14 q 21 q 22 q 23 q 24 q 31 q 32 q 33 q 34 q 41 q 42 q 43 q 44 ) , K = ( k 11 k 12 k 13 k 14 k 21 k 22 k 23 k 24 k 31 k 32 k 33 k 34 k 41 k 42 k 43 k 44 ) , V = ( v 11 v 12 v 13 v 14 v 21 v 22 v 23 v 24 v 31 v 32 v 33 v 34 v 41 v 42 v 43 v 44 ) Q = \begin{pmatrix} q_{11} & q_{12} & q_{13} & q_{14} \\ q_{21} & q_{22} & q_{23} & q_{24} \\ q_{31} & q_{32} & q_{33} & q_{34} \\ q_{41} & q_{42} & q_{43} & q_{44} \end{pmatrix}, \quad K = \begin{pmatrix} k_{11} & k_{12} & k_{13} & k_{14} \\ k_{21} & k_{22} & k_{23} & k_{24} \\ k_{31} & k_{32} & k_{33} & k_{34} \\ k_{41} & k_{42} & k_{43} & k_{44} \end{pmatrix}, \quad V = \begin{pmatrix} v_{11} & v_{12} & v_{13} & v_{14} \\ v_{21} & v_{22} & v_{23} & v_{24} \\ v_{31} & v_{32} & v_{33} & v_{34} \\ v_{41} & v_{42} & v_{43} & v_{44} \end{pmatrix} Q= q11q21q31q41q12q22q32q42q13q23q33q43q14q24q34q44 ,K= k11k21k31k41k12k22k32k42k13k23k33k43k14k24k34k44 ,V= v11v21v31v41v12v22v32v42v13v23v33v43v14v24v34v44
3. 注意力得分计算
计算查询和键的点积,然后除以 d k \sqrt{d_k} dk(这里 d k = 4 d_k = 4 dk=4),再应用 softmax 函数:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
没有掩码时,注意力得分计算如下:
Q K T = ( q 11 k 11 + q 12 k 12 + q 13 k 13 + q 14 k 14 ⋯ q 21 k 21 + q 22 k 22 + q 23 k 23 + q 24 k 24 ⋯ q 31 k 31 + q 32 k 32 + q 33 k 33 + q 34 k 34 ⋯ q 41 k 41 + q 42 k 42 + q 43 k 43 + q 44 k 44 ⋯ ) QK^T = \begin{pmatrix} q_{11}k_{11} + q_{12}k_{12} + q_{13}k_{13} + q_{14}k_{14} & \cdots \\ q_{21}k_{21} + q_{22}k_{22} + q_{23}k_{23} + q_{24}k_{24} & \cdots \\ q_{31}k_{31} + q_{32}k_{32} + q_{33}k_{33} + q_{34}k_{34} & \cdots \\ q_{41}k_{41} + q_{42}k_{42} + q_{43}k_{43} + q_{44}k_{44} & \cdots \end{pmatrix} QKT= q11k11+q12k12+q13k13+q14k14q21k21+q22k22+q23k23+q24k24q31k31+q32k32+q33k33+q34k34q41k41+q42k42+q43k43+q44k44⋯⋯⋯⋯
4. 添加掩码
为了确保当前时间步不能看到未来的信息,我们使用一个上三角掩码矩阵 M \mathbf{M} M 来遮挡未来的信息:
M = ( 0 − ∞ − ∞ − ∞ 0 0 − ∞ − ∞ 0 0 0 − ∞ 0 0 0 0 ) \mathbf{M} = \begin{pmatrix} 0 & -\infty & -\infty & -\infty \\ 0 & 0 & -\infty & -\infty \\ 0 & 0 & 0 & -\infty \\ 0 & 0 & 0 & 0 \end{pmatrix} M= 0000−∞000−∞−∞00−∞−∞−∞0
将掩码添加到注意力得分上:
Q K T + M = ( q 11 k 11 + q 12 k 12 + q 13 k 13 + q 14 k 14 − ∞ − ∞ − ∞ q 21 k 21 + q 22 k 22 + q 23 k 23 + q 24 k 24 q 22 k 22 + q 23 k 23 + q 24 k 24 − ∞ − ∞ q 31 k 31 + q 32 k 32 + q 33 k 33 + q 34 k 34 q 32 k 32 + q 33 k 33 + q 34 k 34 q 33 k 33 + q 34 k 34 − ∞ q 41 k 41 + q 42 k 42 + q 43 k 43 + q 44 k 44 q 42 k 42 + q 43 k 43 + q 44 k 44 q 43 k 43 + q 44 k 44 q 44 k 44 ) QK^T + \mathbf{M} = \begin{pmatrix} q_{11}k_{11} + q_{12}k_{12} + q_{13}k_{13} + q_{14}k_{14} & -\infty & -\infty & -\infty \\ q_{21}k_{21} + q_{22}k_{22} + q_{23}k_{23} + q_{24}k_{24} & q_{22}k_{22} + q_{23}k_{23} + q_{24}k_{24} & -\infty & -\infty \\ q_{31}k_{31} + q_{32}k_{32} + q_{33}k_{33} + q_{34}k_{34} & q_{32}k_{32} + q_{33}k_{33} + q_{34}k_{34} & q_{33}k_{33} + q_{34}k_{34} & -\infty \\ q_{41}k_{41} + q_{42}k_{42} + q_{43}k_{43} + q_{44}k_{44} & q_{42}k_{42} + q_{43}k_{43} + q_{44}k_{44} & q_{43}k_{43} + q_{44}k_{44} & q_{44}k_{44} \end{pmatrix} QKT+M= q11k11+q12k12+q13k13+q14k14q21k21+q22k22+q23k23+q24k24q31k31+q32k32+q33k33+q34k34q41k41+q42k42+q43k43+q44k44−∞q22k22+q23k23+q24k24q32k32+q33k33+q34k34q42k42+q43k43+q44k44−∞−∞q33k33+q34k34q43k43+q44k44−∞−∞−∞q44k44
5. 应用 softmax 和计算输出
在应用了掩码后,再进行 softmax 操作和注意力输出计算:
Attention = softmax ( Q K T + M d k ) V \text{Attention} = \text{softmax}\left(\frac{QK^T + \mathbf{M}}{\sqrt{d_k}}\right)V Attention=softmax(dkQKT+M)V
例如,softmax 操作后的第一个时间步的输出只会考虑第一个元素,忽略未来的元素。其他时间步也是如此,确保当前时间步只关注过去和当前的信息。
具体例子
假设我们的输入序列为:
X = ( 1 2 3 4 ) \mathbf{X} = \begin{pmatrix} 1 & 2 & 3 & 4 \end{pmatrix} X=(1234)
经过线性变换后得到的 Q , K , V Q, K, V Q,K,V 为:
Q = K = V = ( 1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 ) Q = K = V = \begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{pmatrix} Q=K=V= 1000010000100001
计算 Q K T QK^T QKT:
Q K T = ( 1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 ) QK^T = \begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{pmatrix} QKT= 1000010000100001
添加掩码 M \mathbf{M} M 后:
Q K T + M = ( 1 − ∞ − ∞ − ∞ 0 1 − ∞ − ∞ 0 0 1 − ∞ 0 0 0 1 ) QK^T + \mathbf{M} = \begin{pmatrix} 1 & -\infty & -\infty & -\infty \\ 0 & 1 & -\infty & -\infty \\ 0 & 0 & 1 & -\infty \\ 0 & 0 & 0 & 1 \end{pmatrix} QKT+M= 1000−∞100−∞−∞10−∞−∞−∞1
应用 softmax:
softmax ( Q K T + M ) = ( 1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 ) \text{softmax}\left(QK^T + \mathbf{M}\right) = \begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{pmatrix} softmax(QKT+M)= 1000010000100001
计算注意力输出:
Attention = ( 1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 ) V = ( 1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 ) \text{Attention} = \begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{pmatrix} V = \begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{pmatrix} Attention= 1000010000100001 V= 1000010000100001
通过添加掩码,确保每个时间步只能关注当前及之前的时间步,从而实现了未来信息的遮挡。这样,模型在预测下一个时间步时不会看到未来的信息。
全连接层
好的,让我们详细解释全连接层(Fully Connected Layer, FCN)在神经网络中的作用及其具体实现,并通过一个具体的例子来说明其输出维度为 d = d out d = d_{\text{out}} d=dout 的过程。
全连接层(FCN)
概述
全连接层是神经网络中的一种基本层,通常位于网络的末端,用于将前面的层提取到的特征映射到最终的输出。全连接层的每个神经元都与前一层的所有神经元相连接,这种全连接的方式使得该层能够综合之前所有层提取到的信息。
公式
全连接层的操作可以用矩阵乘法来表示:
y
=
W
x
+
b
\mathbf{y} = \mathbf{W} \mathbf{x} + \mathbf{b}
y=Wx+b
其中:
- (\mathbf{x}) 是输入向量,维度为 (d_{\text{in}})。
- (\mathbf{W}) 是权重矩阵,大小为 (d_{\text{out}} \times d_{\text{in}})。
- (\mathbf{b}) 是偏置向量,维度为 (d_{\text{out}})。
- (\mathbf{y}) 是输出向量,维度为 (d_{\text{out}})。
举例说明
假设我们有一个输入向量 (\mathbf{x}),其维度为 (d_{\text{in}} = 4):
x
=
(
1
2
3
4
)
\mathbf{x} = \begin{pmatrix} 1 \\ 2 \\ 3 \\ 4 \end{pmatrix}
x=
1234
我们希望通过全连接层将其映射到一个输出向量 (\mathbf{y}),其维度为 (d_{\text{out}} = 3)。
权重矩阵和偏置向量
假设权重矩阵 (\mathbf{W}) 和偏置向量 (\mathbf{b}) 的值如下:
W
=
(
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1.1
1.2
)
\mathbf{W} = \begin{pmatrix} 0.1 & 0.2 & 0.3 & 0.4 \\ 0.5 & 0.6 & 0.7 & 0.8 \\ 0.9 & 1.0 & 1.1 & 1.2 \end{pmatrix}
W=
0.10.50.90.20.61.00.30.71.10.40.81.2
b
=
(
0.1
0.2
0.3
)
\mathbf{b} = \begin{pmatrix} 0.1 \\ 0.2 \\ 0.3 \end{pmatrix}
b=
0.10.20.3
计算过程
根据公式,我们进行矩阵乘法并加上偏置:
y
=
W
x
+
b
\mathbf{y} = \mathbf{W} \mathbf{x} + \mathbf{b}
y=Wx+b
首先计算 (\mathbf{W} \mathbf{x}):
W
x
=
(
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1.1
1.2
)
(
1
2
3
4
)
=
(
0.1
⋅
1
+
0.2
⋅
2
+
0.3
⋅
3
+
0.4
⋅
4
0.5
⋅
1
+
0.6
⋅
2
+
0.7
⋅
3
+
0.8
⋅
4
0.9
⋅
1
+
1.0
⋅
2
+
1.1
⋅
3
+
1.2
⋅
4
)
=
(
0.1
+
0.4
+
0.9
+
1.6
0.5
+
1.2
+
2.1
+
3.2
0.9
+
2.0
+
3.3
+
4.8
)
=
(
3.0
7.0
11.0
)
\mathbf{W} \mathbf{x} = \begin{pmatrix} 0.1 & 0.2 & 0.3 & 0.4 \\ 0.5 & 0.6 & 0.7 & 0.8 \\ 0.9 & 1.0 & 1.1 & 1.2 \end{pmatrix} \begin{pmatrix} 1 \\ 2 \\ 3 \\ 4 \end{pmatrix} = \begin{pmatrix} 0.1 \cdot 1 + 0.2 \cdot 2 + 0.3 \cdot 3 + 0.4 \cdot 4 \\ 0.5 \cdot 1 + 0.6 \cdot 2 + 0.7 \cdot 3 + 0.8 \cdot 4 \\ 0.9 \cdot 1 + 1.0 \cdot 2 + 1.1 \cdot 3 + 1.2 \cdot 4 \end{pmatrix} = \begin{pmatrix} 0.1 + 0.4 + 0.9 + 1.6 \\ 0.5 + 1.2 + 2.1 + 3.2 \\ 0.9 + 2.0 + 3.3 + 4.8 \end{pmatrix} = \begin{pmatrix} 3.0 \\ 7.0 \\ 11.0 \end{pmatrix}
Wx=
0.10.50.90.20.61.00.30.71.10.40.81.2
1234
=
0.1⋅1+0.2⋅2+0.3⋅3+0.4⋅40.5⋅1+0.6⋅2+0.7⋅3+0.8⋅40.9⋅1+1.0⋅2+1.1⋅3+1.2⋅4
=
0.1+0.4+0.9+1.60.5+1.2+2.1+3.20.9+2.0+3.3+4.8
=
3.07.011.0
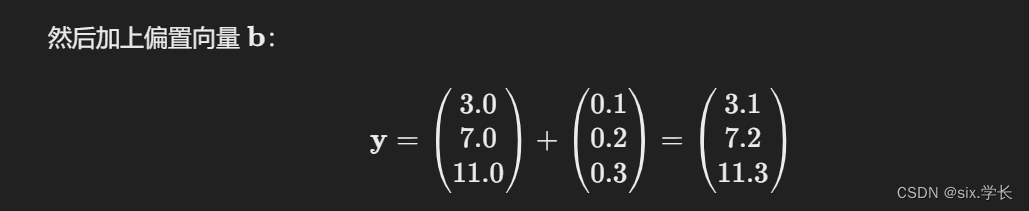
总结
全连接层(FCN)通过矩阵乘法和加偏置操作,将输入向量 x \mathbf{x} x 映射到输出向量 y \mathbf{y} y。在这个例子中,输入向量的维度为 4,输出向量的维度为 3,权重矩阵大小为 3×4,偏置向量的大小为 3。最终输出向量的维度为 d out = 3 d_{\text{out}} = 3 dout=3,实现了从输入到输出的维度转换。
通过全连接层的这种映射,可以将前面网络层提取到的特征转化为最终的输出,例如分类任务中的类别概率或回归任务中的连续值。















 724
724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









