







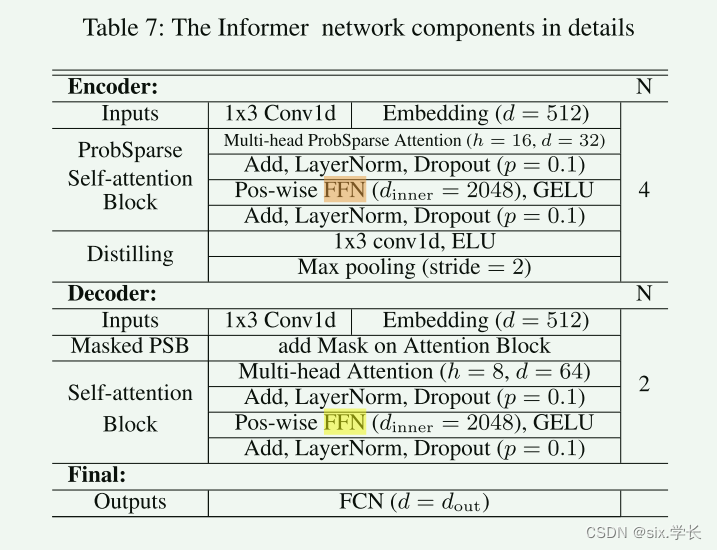
这张图表详细描述了Informer网络的各个组件和结构,包括编码器(Encoder)和解码器(Decoder),以及每一部分的具体操作。以下是对每个部分的详细解释:
Encoder(编码器)
编码器部分负责处理输入数据并生成中间表示。具体步骤如下:
-
Inputs(输入):
- 1x3 Conv1d:一维卷积操作,卷积核大小为1x3,用于初步特征提取。
- Embedding (d = 512):将输入数据嵌入到512维的高维空间中,以便于后续处理。
-
ProbSparse Self-attention Block(稀疏自注意力块):
- Multi-head ProbSparse Attention (h = 16, d = 32):多头概率稀疏自注意力机制,有16个头,每个头的维度为32。这个模块用于捕捉输入序列的长程依赖关系,同时通过稀疏化提升计算效率。
- Add, LayerNorm, Dropout (p = 0.1):标准的添加和归一化操作,包括加法(Add)、层归
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1058
1058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









