







1. Abstract
该小节介绍了前人谣言检查系统依赖子任务的缺点和SpotFake模型的特点以及更好的性能。
虽然存在多模态假新闻检测系统,但它们倾向于通过考虑额外的子任务(如事件鉴别器)和寻找跨模态的相关性来解决假新闻问题。 假新闻检测的结果严重依赖子任务,在没有子任务训练的情况下,假新闻检测的性能平均下降 10%。
我们提出的解决方案在不考虑任何其他子任务的情况下检测假新闻。 它利用了文章的文本和视觉特征。 具体来说,我们利用语言模型(如 BERT)来学习文本特征,图像特征是从在 ImageNet 数据集上预训练的 VGG19 中学习的。
2. Introducion
该部分主要说明了多模态的重要性,并引入Spot Fake模型:SpotFake 考虑了文章中存在的两种形式 - 文本和图像。
- 多模态的好处:
在 SpotFake 中利用多模态信息的动机如下:(i) 不同的模态显示新闻的不同方面,(ii) 来自不同模态的信息在检测新闻的真实性方面相互补充,(iii) 不同的来源操纵不同的模态 基于他们的专业知识(例如,有些人具有通过操纵图像来创建假新闻的经验,而其他人可能具有操纵文本、音频和视频等形式的经验),以及 (iv) 因为现实世界的文本、照片和视频是 除了内容信息之外,复杂的上下文信息也很重要。 - SpotFake:用于假新闻检测的多模式框架。
SpotFake 的主要新颖之处在于结合了语言模型的强大功能,即来自 Transformers (BERT) 的双向编码器表示以结合上下文信息。 图像特征是从在 ImageNet 数据集上预训练的 VGG-19 中学习的。 然后将两种模态的表示连接在一起以产生所需的新闻向量。 这个新闻向量最终被用于分类。
3.Related Work
该小节花费大量篇幅介绍了谣言检测的相关工作,然后总结出之前谣言检查的不足,以及SpotFake的新颖之处。
之前多模态检测方面的不足
尽管这些多模式系统在检测假新闻方面表现良好,但分类器总是与另一个分类器一起训练。 这增加了训练和模型大小的开销,增加了训练的复杂性,有时还可能由于缺乏辅助任务的数据而阻碍系统的通用性。
SpotFake的新颖之处
它考虑了来自两种不同模式的特征,并将样本分类为真实或虚假,而不考虑任何其他子任务。
4.Methodology
该小节主要介绍检测方法
1.提出模型前:
作者做了一项公众调查,对人类表现、假新闻检测的困难以及多种模式的重要性,尤其是文本和图像组合对假新闻检测的重要性进行实证分析,充分证明了多模态的重要性。
我们希望我们的系统能够在没有任何其他子任务的情况下独立检测假新闻,正如在当前最先进的系统中所看到的那样。 当前最先进系统的假新闻分类器本身并不能很好地执行。 但是,在存在诸如样本重建之类的次要任务时,性能会显着提高。
2.SpotFake模型构成:
SpotFake模型如下图所示:
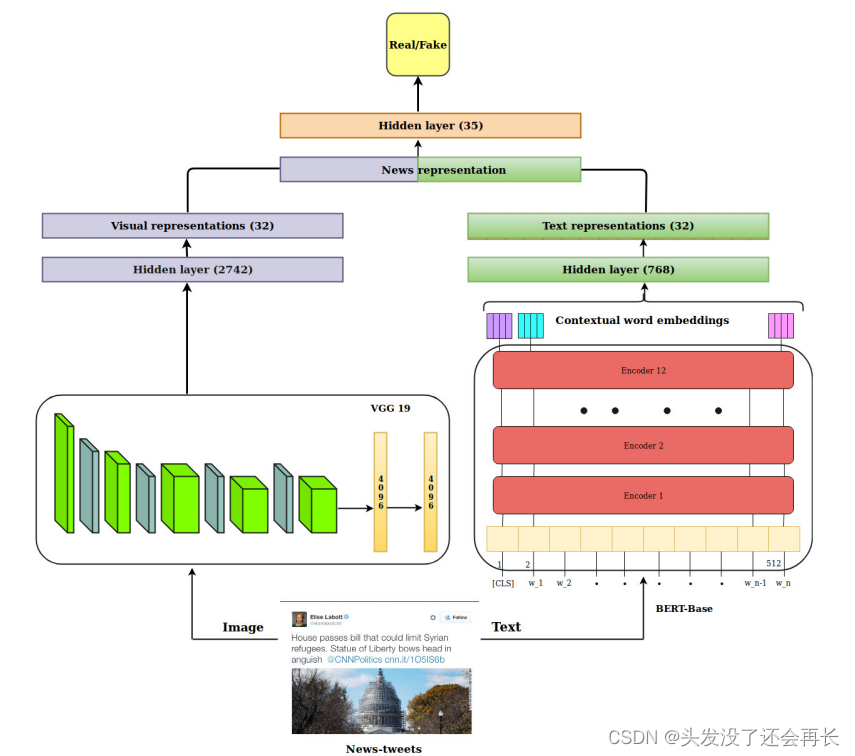
SpotFake 分为三个子模块。 第一个子模块是文本特征提取器,它使用语言模型提取上下文文本特征。 第二个子模块是视觉特征提取器,它从帖子中提取视觉特征。 最后一个子模块是一个多模态融合模块,它将从不同模态中获得的表示组合在一起形成新闻特征向量。
Textual Feature Extractor
我们使用基于 BERT 的具有 12 个编码器(称为转换器块)的模型。 它将不断向上移动的单词序列作为输入。 每一层都应用自我注意,并将其结果通过前馈网络传递,然后将其传递给下一个编码器,如图所示:
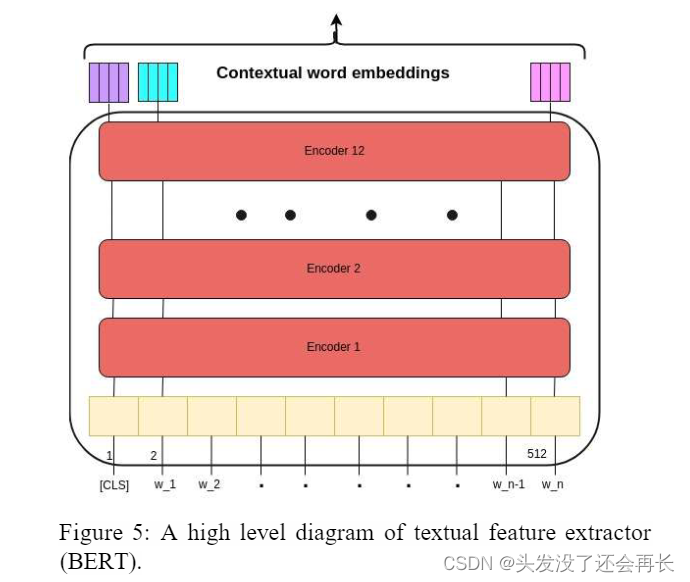
[CLS] 表示分类,Wi 表示作为输入到文本特征提取器子模块的标记序列。 从模块的倒数第二个输出层获得的特征是帖子的所需上下文嵌入,然后通过全连接层减少到长度为 32 的最终维度。这些文本特征向量表示为 Tf。
Visual Feature Extractor
我们使用预训练的 VGG-19。 我们提取在 ImageNet 数据集(表示为 Vg)上预训练的 VGG-19 卷积网络的倒数第二层的输出,并将其通过一个全连接层以减少到长度为 32 的最终维度。最终的视觉表示(表示为 作为 Vf) 获得如下:
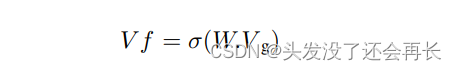
其中 Vg 是从预训练的 VGG19 [23] 获得的视觉特征表示,W 是视觉特征提取器中全连接层的权重矩阵。
Multimodal Fusion:
通过不同模态(即 Tf 和 Vf)获得的两个特征向量使用简单的连接技术融合在一起,以获得所需的新闻表示。 然后,此新闻表示将通过一个完全连接的神经网络进行假新闻分类。
5.Dataset
使用微博和twitter数据集
6.Experiment
该节介绍在实验过程中每一个模块的具体细节,参数设置和实验结果。
A. Experimental Setup of SpotFake:
对于文本模态,只完成预处理步骤是固定序列的输入长度。 所有高于规定长度的句子都被修剪,低于规定长度的任何内容都用零填充。 最终长度值被确定为 95% 的句子低于它的值。对于模型的图像组件,所有图像都调整为 224x224x3。
对于文本特征提取器:填充和标记化的文本被传递到 BERT 模型以接收维度为 768 的词向量。这些长度为 768 的向量然后分别通过大小为 768 和 32 的两个全连接层。对于图像特征提取器:同样,调整大小的图像通过在 ImageNet 上预训练的 VGG-19,被提取为长度为 4096的向量。 然后,该向量分别通过大小为 2742 和 32 的两个全连接神经网络层(对于微博数据集,我们有一个大小为 32 的全连接层)。多模态融合:两种模态的 32 维向量被连接并传递到一个全连接的神经网络分类器中,该分类器具有大小为 35 的隐藏层和大小为 1 的分类层,具有 sigmoid 激活函数。
另外:模型中的每个全连接层都有一个 relu 激活函数和 0.4 的 dropout 概率。 该模型在 256 的批量大小上进行训练,Adam 优化器使用提前停止对验证准确度进行了训练。
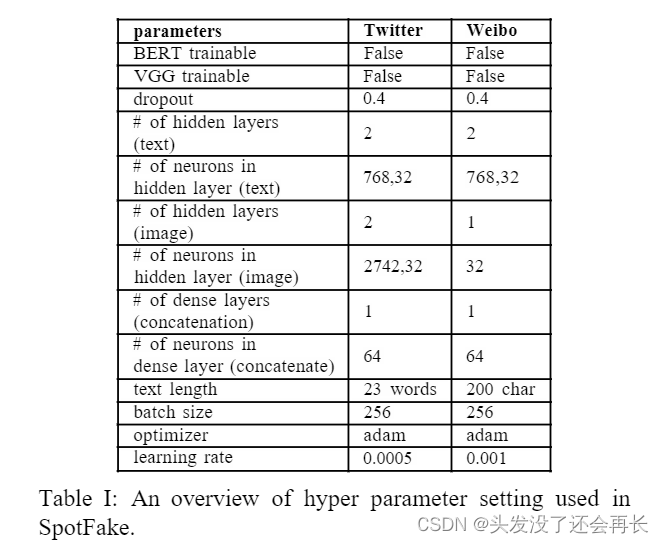
B. Hyperparameter Tuning for SpotFake
参数调整如下:
C. Results
在本节中,我们将报告 SpotFake 与当前最先进的 EANN- 和 MVAE 在每个类别的准确率、准确率、召回率和 Fl 分数方面的性能比较。 完整的比较结果下表:
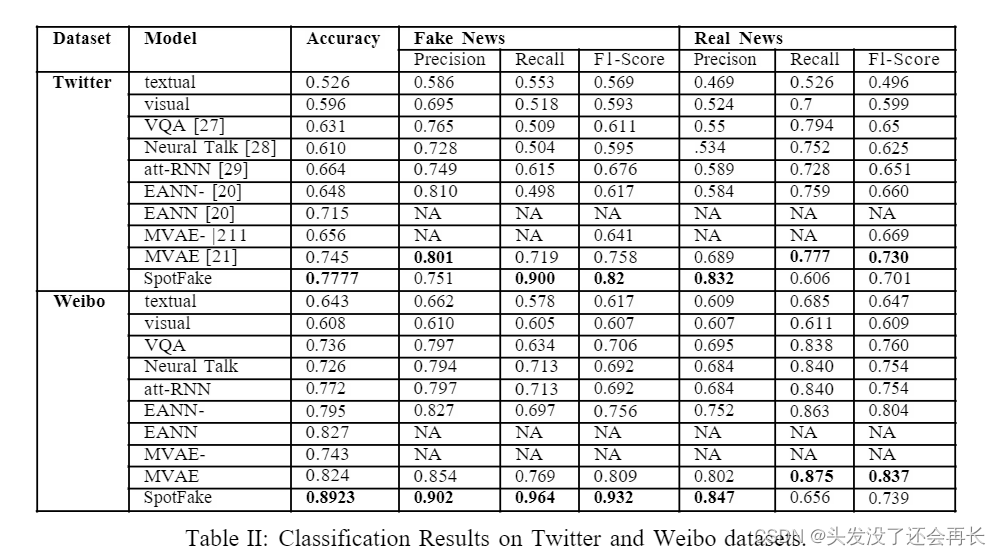
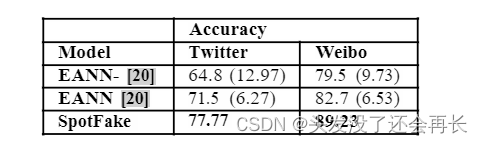
尽管 SpotFake 是一个独立的假新闻分类器,但我们在两个数据集上仍然大大优于 EANN 和 MVAE 的配置。 在 Twitter 数据集上,SpotFake 实现了分别超过 EANN- 和 EANN 12.97% 和 6.27% 的准确度增益。
7.Conclusion
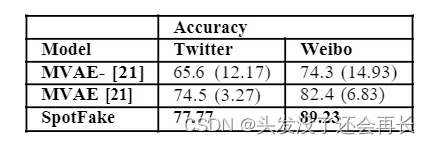
SpotFake 使用语言转换器模型和预训练的 ImageNet 模型进行提取,并使用全连接层进行分类。 它以平均 6% 的准确率在正确识别与模态方面优于基线。 更长的文章和更复杂的融合技术仍有改进的空间,以了解不同的模态如何在假新闻检测中发挥作用。















 688
688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









