







Abstract
我们提出了 SpotFake+,这是一种多模式方法,它利用迁移学习从新闻文章及其相关图像中捕获语义和上下文信息,并实现更好的假新闻检测准确性。
Introduction
作者在该小节简单介绍了谣言检测相关工作,并总结出了他们的不足之处:
但由于以下原因,它们表现不佳:(1) 他们缺乏文本中存在的上下文信息,并且(2)他们没有从图像模态中捕捉可能试图强调某些事实的特征。
然后提出了自己的模型:
为了克服上述挑战,我们提出了 SpotFake+,它是现有多模式假新闻检测系统SpotFake的高级版本。 所提出的架构利用预训练的语言转换器和预训练的 ImageNet 模型进行特征提取。 这些特征向量被输入全连接层进行分类。
Methodology
Dataset
FakeNewsNet 存储库(Shu et al. 2018)由来自两个不同领域(政治和娱乐)的两个数据集组成。 每篇新闻文章都有与之关联的文本和图像。
数据集中存在的样本数量如表所示:

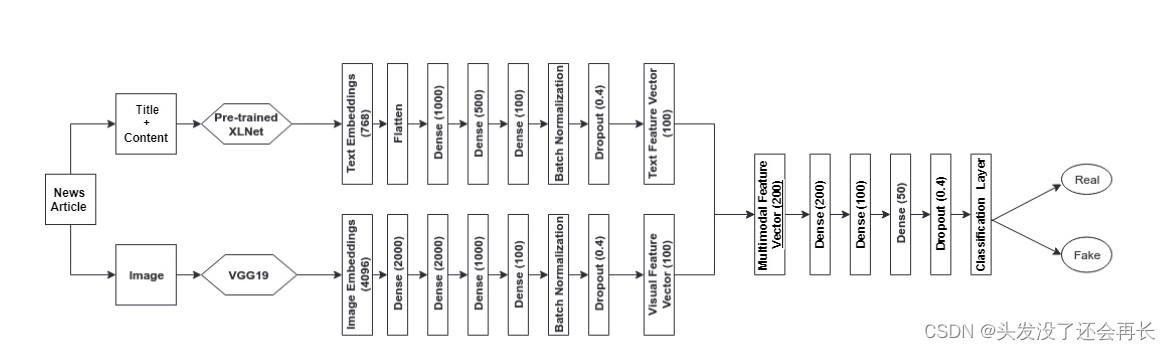
Proposed Model Architecture
所提出的模型有两个子模块——文本特征提取器和视觉特征提取器
Results
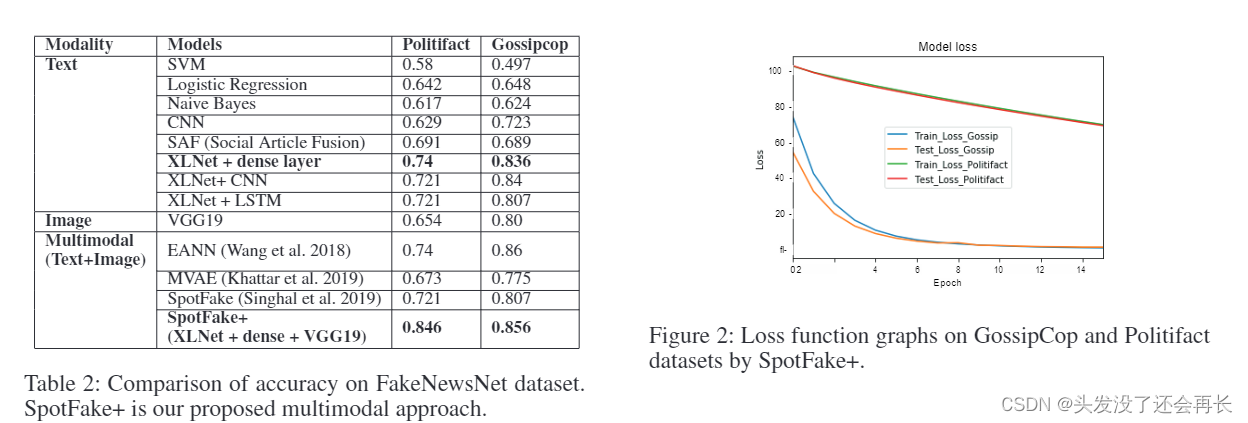
在同一数据集上将 SpotFake+ 与当前最先进的文本和其他多模态模型进行比较。 结果的详细分析如表2所示。损失函数图也绘制在图2中。
Conclusion
给定一篇新闻文章,SpotFake+ 可以将其分为两类:真实的或虚假的。所提出的架构使用迁移学习来捕获文章中的文本和视觉特征。 本文中进行的实验进一步揭示了多模态特征在假新闻检测问题上的潜力。















 1261
1261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









