






 本文提出HNHN框架,一种超图卷积网络,包含非线性激活函数和灵活的归一化策略,提高真实世界数据集的分类准确性和速度。通过cliqueexpansion和stareexpansion处理超图,对比现有技术,HNHN在超节点和超边表示学习上取得优势。
本文提出HNHN框架,一种超图卷积网络,包含非线性激活函数和灵活的归一化策略,提高真实世界数据集的分类准确性和速度。通过cliqueexpansion和stareexpansion处理超图,对比现有技术,HNHN在超节点和超边表示学习上取得优势。
简介
Hypergraph|超图 为许多真实世界的数据集提供了自然表示。本文提出了一个用于超图表示学习的新框架HNHN。HNHN是一种超图卷积网络,具有应用于超节点和超边的非线性激活函数,并结合了一种归一化方案,该方案可以根据数据集灵活调整高基数超边和高阶顶点的重要性。与现有技术的方法相比,HNHN在真实世界数据集上的分类精度和速度方面的改进了性能。
引入
许多真实世界的数据都可以用图形表示,因为数据是以对象和对象之间关系的形式出现的。在许多情况下,一个关系可以连接两个以上的对象。超图可以自然地表示这样的结构。以论文作者图为例,其中的顶点表示论文。由于一个作者可以写多篇论文,所以在超图中把作者表示为超边是很自然的。本文的目标是用一种新的超图卷积算法来学习这种结构化数据的表示。
超边非线性问题:允许网络学习单个超边的非线性行为,这存在于许多真实世界的数据集中,具体来说就是:训练一个网络,其中一个用表示超节点,另一个用
表示超边。然后,可以将超节点超边关联矩阵用于卷积步骤。非线性函数σ同时作用于超节点和超边。
标准化问题:有多种不同的标准,取决于如何加权不同的顶点,比如;拉普拉斯算子,规范化表示如何对大阶顶点与小阶顶点进行加权的选择。这一选择应该根据权重较大的顶点在特定数据测试中是否能提供更好的准确性来做出——例如,在一个社交网络上,拥有大量连接的用户可能是重要且有影响力的个人,他们的活动对预测有用,而在另一个网络上,他们可能是随机建立连接的机器人。
本文的主要贡献:提出一种超图卷积网络,该网络具有应用于超节点和超边的非线性激活函数,以及一种更灵活的归一化方法。
模型和分析:
定义超图H由超节点的集合V和超边的集合E组成,其中每个超边本身就是一组超节点。定义关联矩阵A,如果第i个超节点在第j个超边中,则A(i,j)=1,否则=0,通过关联矩阵A的卷积来更新超节点表示和超边表示
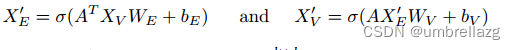
σ是非线性激活函数,W和b分别是权重矩阵和偏置矩阵。
Ni是点vi的边领域,Nj是ej的点领域
clique and star expansions的关系
为了将图卷积应用于超图问题,必须从超图H构建图G,有两种主要的方法clique and star expansions
第一种,clique expansion:通过将每个超边e用在其顶点集上的clique替换生成一个图,这种方法的一个小变种是生成一个加权图,其中clique上的每条边的权重等于k的某个固定函数,对于变体,我们用每个顶点到自身的一条边加上clique来替换每条超边
第二种,star expansion:生成一个图,它的点集是
,如果在超节点v和超边e之间有条边而且在超节点与超节点或者超边与超边之间没有边,这样可以使图形具有双向性。(假设超边
,那么子集
就是星形图)
如果对超节点和超边使用相同的权重,设置 和
,HNHN方法就等同于在星形扩展 G∗ 上图卷积
如果去掉非线性激活函数 σ,只考虑线性映射,那么HNHN方法就等同于在clique扩展的图上图卷积。
缺陷:
clique expansion:可能导致信息丢失,在同一个顶点集上可能有两个具有相同clique expansion的不同超图。
star expansion:它对待超节点和超边是一样的。在许多数据集中,超节点和超边描述了完全不同的对象,因此权重应该不同。
结论:
和
的光谱理论(spectral theory)差不多复杂或简单。
Hypergraph normalization超图规范化
一种常见的消息传递方案是通过消息池后邻域的基数来规范化消息。在将消息从超边传递到超节点的情况下,这可以表示为
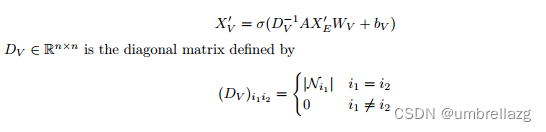
这确保了,对于形如ReLU这样的无界激活函数σ,当vi具有大程度时,特征向量不会从一层到下一层快速增长,而对于有界激活函数,σ的输入不会太大(因为有界激活功能在最大值上近似恒定,而这会导致梯度消失)。
缺点:无论程度如何,每个超边的贡献都被赋予相同的权重
改进:在对入射到给定超节点的超边求和之前,我们根据实参数α,用其阶的幂对每个超边的贡献进行加权
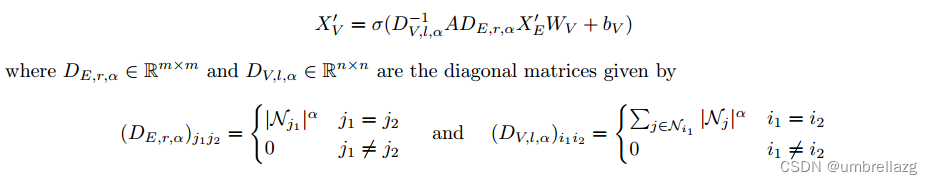
当α>0时,与之前的归一化相比,度高的超边的贡献增加,而如果α<0,它们的贡献减少。α被视为针对给定数据集要优化的超参数。
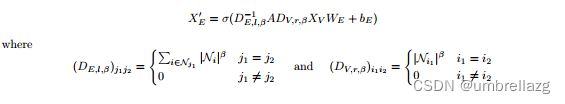
算法细节:
输入:超节点和超边之间的关联关系、超节点的输入特征向量以及超节点子集的目标标签。
步骤:从超图结构中,提取邻域信息来计算归一化因子。
然后HNHN超图卷积的每一层将信号从超节点中继到超边
然后,HNHN超图卷积的每一层都将信号从超节点中继到超边,具有非线性和特定于节点的归一化,再然后类似地从超边到超节点
最后,再基于学习节点表示的预测标签和给定的目标标签之间使用交叉熵计算损失。
Dropout被添加到任何不是最后一个的卷积层中,以减轻过拟合,ReLU被用作非线性激活函数
模型训练及参数设置
使用Adam优化器,每100次迭代,学习率会成倍降低0.51倍,HNHN性能相对于超参数变化是鲁棒的。超参数:0.3 dropout率;0.04 初始学习率;200训练epochs,PubMed数据集的隐藏维度是800,其他数据集为400
数据预处理:
本文用的基本上是co-citation和co-authorship两种类型的数据集,并利用这两种数据集构建超图, 具体来说就是,对于co-aturhorship数据集,如果一些超节点对应的文章是某条超边对应的作者写的,那么这些超节点就属于这条超边;而对于co-citation数据集,如果一些超节点对应的文章被超边e引用,那么这些超节点属于超边e。文章没提这个e的物理意义
co-citation例子:CiteSeer 、PubMed
co-authorship例子:Cora、DBLP

超图预测任务:
超节点预测:给定一个超图和一小组超节点上的节点标签,该任务是预测剩余超节点上的标签。预测和目标标签之间的交叉熵是损失函数,如参数设置所提到的,本文使用Adam优化器和一个学习率调度器,它以固定的时间间隔成倍地降低学习率。超参数α和β通过对训练集的5重交叉验证来确定。(α和β分别是用来给超边和顶点加权的参数),可调整的超参数还包括(层数、dropout rate)想要获得accuracy,最多需要两个卷积层(原文说at most two layers are needed,一般说这个不是至少要两个吗?不太懂)
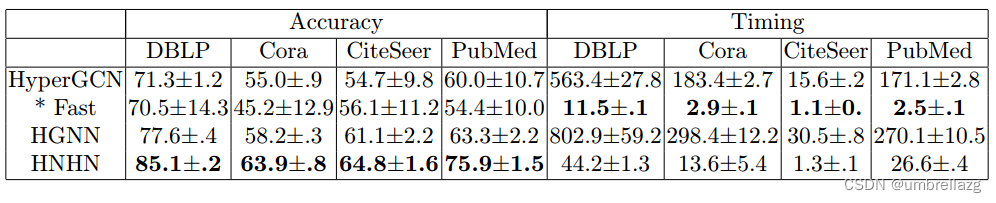
超图预测任务实验结果如上,HNHN在数据集上优于最先进的技术,同时获得有竞争力的计时结果。
减少特征维度(feature dimensions)的节点预测:
feature dimensions到底是特征维度还是特征尺寸,不太懂。
本文在使用潜在语义分析[Journal of the American Society for Information Science的方法]减少输入特征维度之后,实验了节点预测,结果是训练速度更快,但是准确率下降了,这个实验表明HNHN适用于计算资源有限的情况
边特征表示学习Edge representations learning:
与依赖于超边扩展的方法相比,HNHN的优势在于它为每个超边生成一个专用的向量表示,因此,HNHN学习表示可以容易地适用于下游边缘相关的任务,例如边预测。因为HNHN中的超边-超节点具有对称性,在超节点和超边都代表论文的co-citation数据集CiteSeer上,当给定15%的超边标签(并且没有超节点标签)时,超边分类精度为62:79±1:43。这与64:76 1:63的超节点预测精度相当
normalization parameters标准化参数的影响:
归一化参数α控制不同基数的超边之间存在多少权重差异。当α > 0时,大尺寸的超边被赋予较大的权重;当α < 0时,越小的超边权重越大。β也一样,不过β是影响超节点的。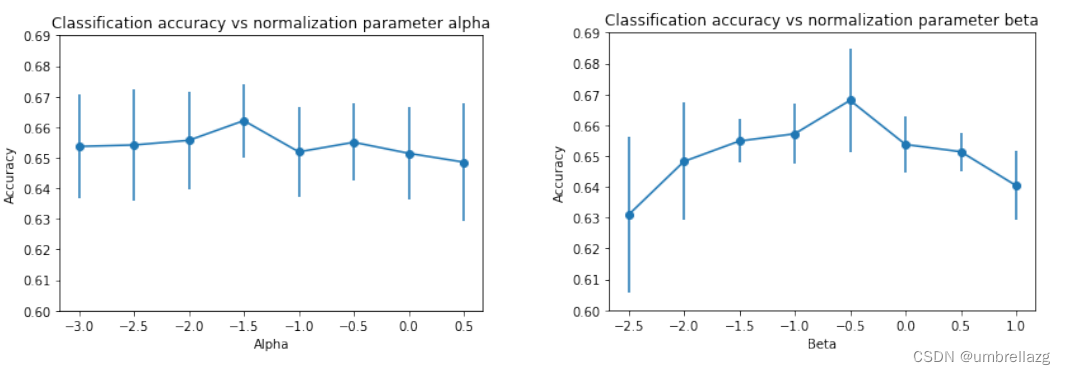
下面使用来交周报的,不用看:
1 Title
HNHN: Hypergraph Networks with Hyperedge Neurons(Yihe Dong,Will Sawin,Yoshua Bengio)ICML 2020
2 Conclusion
Hypergraph provides a natural representation of many real-world datasets. This paper propose a new framework for hypergraph representation learning, HNHN. HNHN is a hypergraph convolutional network with nonlinear activation functions applied to supernodes and hyperedges, combined with a normalization scheme that flexibly adjusts the importance of high-cardinality hyperedges and higher-order vertices according to the dataset. Compared with the methods of the prior art, HNHN offers improved performance in terms of classification accuracy and speed on real-world datasets.
3 Good Sentence
1、This choice should be made according to whether weighting vertices of large degree highly gives better accuracy on a particular dataest - e.g. on one social network, users with a large number of connections may be important and influential individuals whose activity is useful for prediction, while on another, they may be bots who make connections at random.(Why the normalization should be done and how to normalize)
2、Compared to approaches that rely on hyperedge expansions, HNHN has the advantage in that it produces one dedicated vector representation per hyperedge. This differs from prior works that expand out a hyperedge into multiple nodes or select a representative subset of hypernodes for each hyperedge.(the difference of HNHN and previous works)
3、By allowing a varying hyperpameter α, we can choose a weighting for hyperedges that is appropriate for a given dataset.(the affection of the parameters)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









