







1 LN
1.1 BN的一些缺点
在Batch Normalization中存在以下几个缺点:
1 对batchsize大小敏感, 由于每次计算均值和方差是在同一个batch上, 如果batchsize设置的太小, 计算出来的均值和方差不足以代表整个数据分布。
2 BN的计算过程中需要保存某一层神经网络batch的均值和方差等统计信息, 对于固定长度的网络结构(DNN、 CNN)比较适合, 但是对于不定长度的RNN的,训练比较麻烦。
1.2 LN介绍以及优点
在Layer Normalization中, 是针对不同样本计算当前样本的所有神经元的均值和方差, 也就是说在LN中, 同层神经元输入拥有相同的均值和方差, 不同的输入样本具有不同的均值和方差; 而在BN中, 同层的不同神经元输入的是不同的均值和方差, 而同一个batch中的所有样本拥有相同的方差和均值
上述是类似全连接的时候,下面是有通道的时候
BN的是对不同样本的同一个通道的每个位置分别计算均值和方差,并用这些统计量对该位置上的值进行归一化
而LN具体的计算方式是
同一个样本上所有通道,每个通道的所有点,全加起来计算均值和方差,然后利用这个均值和方差对这个样本上所有点进行归一化
主要优点:
不受样本批次大小的影响
在RNN上效果比较明显, 但是在CNN上, 效果不及BN
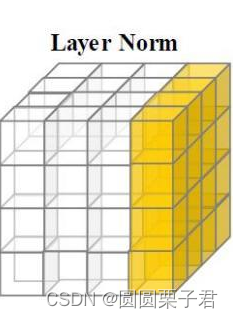
上图就是LN的归一化示例范围
LN的计算在归一化跟BN一样,每个点的值减去该通道的均值,然后除以该通道的方差的平方根(通常还会加上一个小的常数epsilon以避免除以零)。通常在归一化后,还会对每个点进行重新缩放和偏移(即乘以一个“尺度”参数γ并加上一个“偏移”参数β),这两个参数是可学习的,允许模型恢复原始的数据分布(如果这对于解决任务是有益的)。
类似于BN的下图
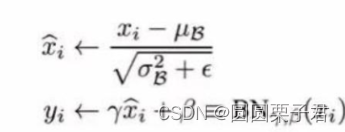
2 IN
Instance Normalization 在某些类型的网络中,特别是在风格转换和图像生成任务中,非常流行。
工作原理:
1 对于每个样本中的每个通道,单独计算该通道内所有值的均值和方差。这意味着对于每个样本的每个通道,你都会聚集该通道内的所有点的值,然后计算这些值的均值和方差。
2 然后,使用计算出的均值和方差对该通道内的每个值进行归一化。具体来说,每个点的值减去该通道的均值,然后除以该通道的方差的平方根(通常还会加上一个小的常数epsilon以避免除以零)。
3 和BN、LN一样,Instance Normalization 也可以包括一个重新缩放(scale)和偏移(shift)步骤,其中每个通道有自己的可学习参数(γ和β),用于进一步调整数据分布。

3 GN
Group Normalization 是一种介于Instance Normalization 和 Layer Normalization之间的标准化技术,它旨在克服批次大小对Batch Normalization性能影响的问题。
GN的工作原理:
1 将每个样本的通道分成几组。每组包含一定数量的通道。例如,如果一个样本有32个通道,而你选择的组数为8,那么每组将有4个通道
2 对于每个样本中的每组,计算该组内所有通道的所有空间位置的值的均值和方差。这意味着,你会将同一组内的所有通道的所有点的值聚集起来,然后计算这些值的均值和方差
3 然后,使用计算得到的均值和方差对该组内的每个通道的每个空间位置的值进行归一化。具体来说,每个点的值减去该组的均值,然后除以该组的方差的平方根(通常还会加上一个小的常数epsilon以避免除以零)
4 类似于其他标准化技术,Group Normalization 也可以包含一个重新缩放(scale)和偏移(shift)步骤,每组有自己的可学习参数(γ和β),用于进一步调整数据分布。
通过这种方式,Group Normalization 能够在不同样本之间独立操作,并且不像Batch Normalization那样对批次大小敏感。这使得GN在小批次大小的情况下表现更为稳定,尤其是在资源受限或实时处理场景中非常有用。

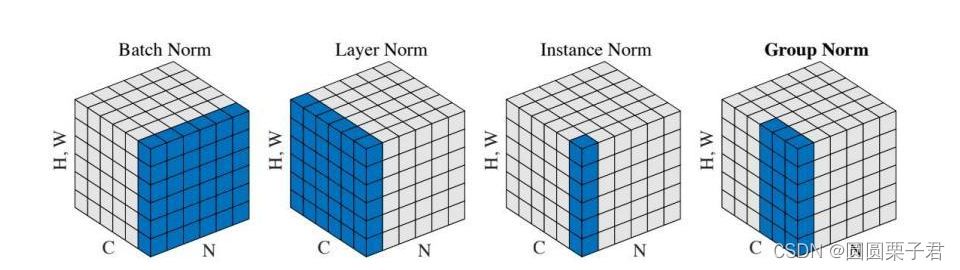
四者类似于下图:
4 SN
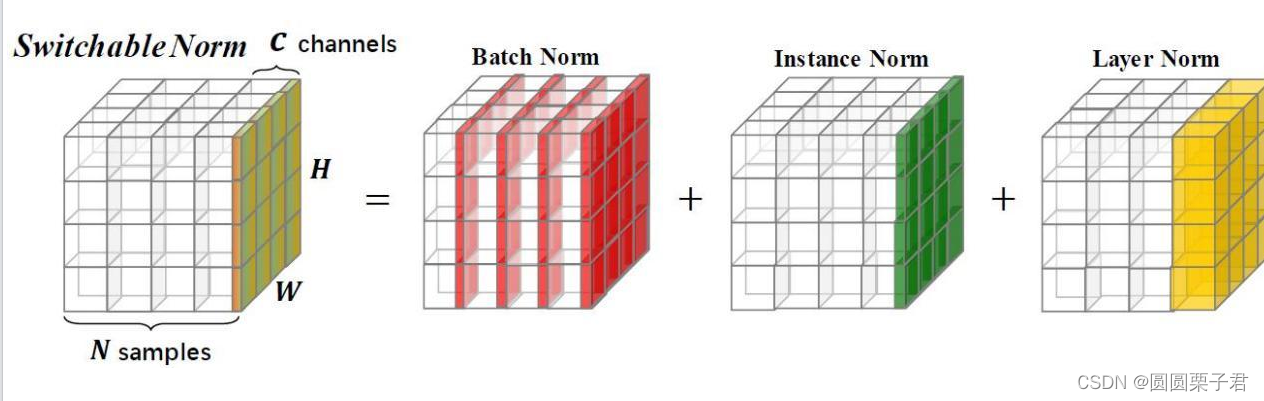
在Switchable Normalization(SN)中,对于每个样本的每个通道,都会使用Batch Normalization(BN)、Instance Normalization(IN)和Layer Normalization(LN)计算得到的均值和方差。然后,这些均值和方差会根据学习到的权重进行加权组合,之后用于归一化该通道的每个位置的值。具体来说:
-
对于一个给定的样本和一个特定的通道:
- 你会得到BN计算的该通道所有样本的均值和方差。
- 同时,你也会得到IN计算的该通道该样本的均值和方差。
- 还有LN计算的该样本所有通道的均值和方差。
-
这些均值和方差会被加权组合:
- 通过学习到的权重(对于BN、IN和LN),你可以得到一个综合的均值和一个综合的方差。

-
使用这个综合的均值和方差进行归一化:
- 每个位置的值会用这个综合的均值和方差进行归一化处理。
-
当处理下一个通道时:
- BN的均值和方差会基于新通道的所有样本重新计算。
- IN的均值和方差会基于该样本新通道的值重新计算。
- LN的均值和方差(如果LN是按样本计算的话)不会改变,因为它是基于整个样本的所有通道计算的。
- 其中,BN对于通道来说,计算的是通道的每个位置的均值和方差,所以,对于下一个值进行归一化的时候,会使用之前BN对于这个值已经保存的均值和方差进行归一化
通过这种方式,Switchable Normalization 能够在BN、IN和LN之间灵活切换,使得网络能够自适应地选择最适合当前任务和数据分布的归一化策略,这有助于提高模型的性能和稳定性。


















 2161
2161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









