







 Wav2Lip是一种AI模型,通过使用音频特征和随机参考视频,生成与目标语音同步的唇部动作。文章详细介绍了其输入数据预处理、生成器和判别器架构,以及在GAN框架下的训练过程,旨在解决唇同步生成中的身份、声音和词汇限制问题。
Wav2Lip是一种AI模型,通过使用音频特征和随机参考视频,生成与目标语音同步的唇部动作。文章详细介绍了其输入数据预处理、生成器和判别器架构,以及在GAN框架下的训练过程,旨在解决唇同步生成中的身份、声音和词汇限制问题。
文中提到,早期的研究主要集中在特定发言者(如巴拉克·奥巴马)的视频上,通过学习音频输入与唇部标记之间的映射来生成说话面孔视频,但这些方法需要大量的特定发言者数据,并且无法适应新的身份或声音。另外,一些新的研究尝试通过修改现有视频中的语句来减少对大量数据的依赖,或者采用两阶段学习方法,首先学习与发言者无关的特征,然后使用较少的数据进行训练。然而,这些方法仍然面临着数据集大小和词汇限制的挑战,影响了模型处理真实视频中音素和视素映射的能力。与此相对,我们的研究旨在开发一种能够在不受身份、声音或词汇限制的情况下,对任何目标语音进行唇同步的无约束说话面孔视频生成技术。这将大大扩展生成说话面孔视频的应用范围和灵活性。
2020年,来自印度海德拉巴大学和英国巴斯大学的团队,在ACM MM2020发表了的一篇论文**《A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild 》**,在文章中,他们提出一个叫做Wav2Lip的AI模型,只需要一段人物视频和一段目标语音,就能够让音频和视频合二为一,人物嘴型与音频完全匹配。
Wav2Lip 则可以直接将动态的视频,进行唇形转换,输出与目标语音相匹配的视频结果。
https://bhaasha.iiit.ac.in/lipsync/example_upload3
https://learn.thinkdiffusion.com/wav2lip-lip-sync-any-existing-video/
https://medium.com/@jacksaunders909/wav2lip-generalized-lip-sync-models-e0effc4e8ed3
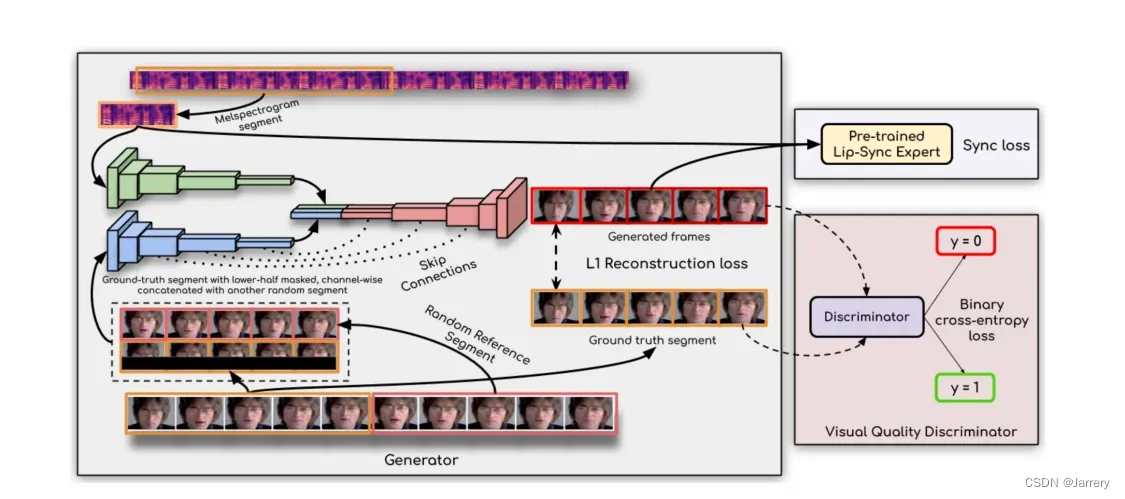
- 输入: 输入包括一个Mel频谱图段(音频特征)和一个随机参考视频段(一系列连续的视频帧)。 处理: 生成器的任务是通过这两个输入来生成一系列新的视频帧,这些帧中的嘴型应该与Mel频谱图中的音频信息同步。 掩蔽策略: 在视频帧中,下半部分可能被掩蔽,并与另一随机视频段连接,这有助于生成器专注于嘴唇区域的生成。 Skip Connections: 在网络中使用跳过连接技术,有助于在深度网络中保留低层特征信息。 L1重建损失: 生成器在训练过程中会用到L1重建损失,以确保生成的帧与真实帧(Ground truth segment)在像素级别上尽可能接近。
- 同步判别器 (Lip-Sync Expert) 预训练: 该部分是预先训练过的专家系统,用于检测生成的帧和原始音频之间的同步性。 同步损失 (Sync loss): 在训练过程中,同步损失用于衡量生成的视频帧与音频的同步精度。
- 视觉质量判别器 (Visual Quality Discriminator) 判别器 (Discriminator): 判别器的任务是区分生成的视频帧与真实视频帧,判别其是否看起来自然和真实。 二元交叉熵损失 (Binary cross-entropy loss): 使用二元交叉熵损失来优化判别器,使得它能够更好地区分真实帧和生成帧。
- 输出 生成帧 (Generated frames): 这是模型输出的最终视频帧,它们应当在视觉上看起来自然,并且
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4162
4162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









