








冷启动问题,大家并不陌生。但是如何解决呢?加特征,加样本,加图谱,加规则?十方在做信息流广告推荐时,主要通过加一些泛化特征解决冷启动问题,但是这样并不一定是最好的方案,新广告很大程度上,还是会被模型"低估"。如何解决冷启动问题呢?

冷启动问题可以逃避吗?当然不能,就拿广告推荐来说,当一个客户想投广告,由于该广告从未曝光过,召回模型可能都无法召回,更别说后面的粗排和精排模型是否会过滤掉,所以很难起量。《Alleviating Cold-Start Problems in Recommendation through Pseudo-Labelling over Knowledge Graph》 这篇论文提出了基于GNN的知识图谱方法解决冷启动问题,该方法增加了伪标签做数据增强。这种方法使用了历史从未观察到的user和item作为正样本,补充到样本中。通过在知识图谱中为每个用户选择可能的正例,同时还进行了负采样策略,从而抑制偏差。通过实验证明该方法在各个场景下能显著提高冷启动user/item的推荐性能。

我们有一个集合的用户U和一个集合的item I,如果用户u和item i有交互,yu,i= 1,我们知道大部分(u,i)都是没有被观测过的,这是个非常稀疏的交互矩阵(u, i) U * I。我们把观测过的user item 对定义为 O = {( , )| ∈ U, ∈ I+ } 。同时我们还有个KG G = {(ℎ, , )|ℎ, ∈ E, ∈ R},看过前几篇关于 GNN的肯定很清楚,h表示head entity,t表示target entity,r就是h和t的关系。然后我们目标就是预估那些未被观测到的yu,i。这篇论文用的GNN框架是KGNN-LS("Knowledge-aware graph neural networks with label smoothness regularization for recommender systems"),不是本文重点,本文重点介绍通过3种方法解决冷启动的样本问题。

我们的数据必须高度覆盖未观测数据,且不能把它们完全当成负样本。为了缓解观测到的(u,i)稀疏性问题,我们通过模型预测未观察到的样本(u,i)的label来增加正负标记数据。具体内容如下:
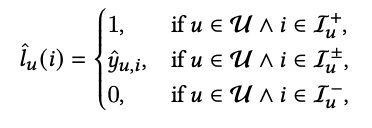
I+, I− , 和 I ±分别表示正例,负例和伪标签,loss定义如下:
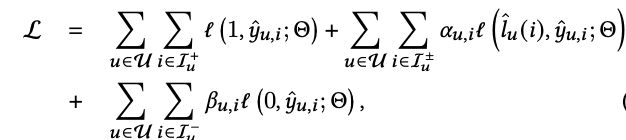

为了找到可靠的个性化伪标签,我们可以用观测到的user和item对,构建图,从而用h跳广度优先搜索算法(BFS)计算某个用户的正例(I+)到各个未交互过的item( I ±)的路径数,通过以下概率公式采样伪标签:
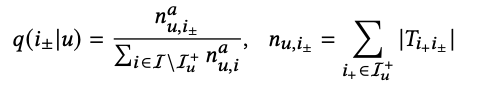
a是一个控制采样分布偏度的超参,nu,i± 表示用户u有交互的item到未交互过的item路径数之和。从该公式,我们发现,如果观测过的item到未观测的item路径数越多,被采样到的概率越大。如果控制a为一个很小的值,这个采样分布就偏向于均匀分布,该论文a取0.5。
此外还有基于流行度的采样。由于冷启动的item相比较与流行的item,更容易被采样作为负样本,因此这个偏差会影响模型的效果,解决办法就是用下式概率分布进行负采样:

mu,i-表示i-与用户交互过的频次,b用于控制频次的重要程度。在训练时,确保三种样本(正例,负例,伪标签)是均匀的。下面算法给出了采样策略。


我们知道,用伪标签训练模型,会造成模型优化过程不稳定,所以该论文引入了co-training方法,该方法同时训练两个模型f和g,每个模型的训练都依赖对方模型的预估结果。学习算法简单描述如下:
(1) 采样两个mini-batches B 和 B . 并通过f和g分别算出伪标签。
(2) 通过loss计算梯度,模型f用 B 更新参数,模型g用B 更新参数。
因此f在B 的loss函数定义如下:


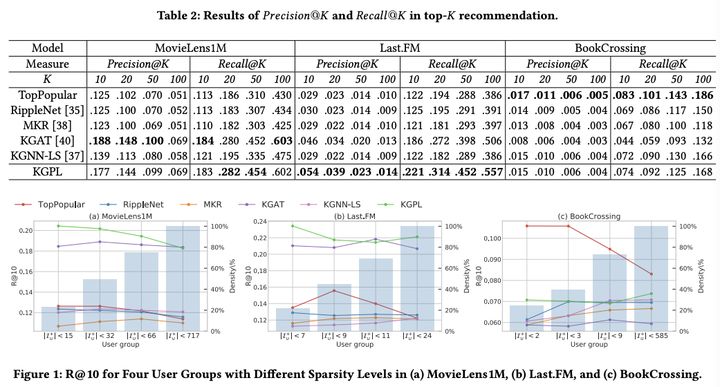
实验比较了各种基于KG的推荐算法,用了3个开源数据集,如下:
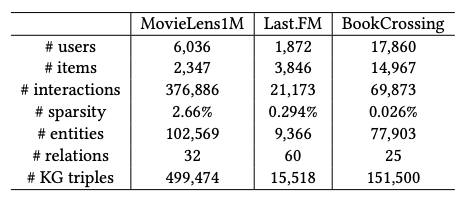
实验结果发现,KGPL在各个数据集的效果是可圈可点的。















 959
959











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









