






对于炼丹师来说,特别是面对海量特征,还要从中挖掘出交叉特征"喂"给模型,是十分痛苦的。不得不说,人都是"懒惰"的,我们炼丹师当然希望有个厉害的深度学习模型,只需要对最原始的特征做预处理后,扔给模型,让它自己学习交叉特征。
希望模型像"奶牛"吃草,挤得是"牛奶",那么我们必须保证"喂"的是草。并不是所有的交叉特征与推荐系统的最终优化目标都是相关的,盲目的"喂"特征只会带来更多的噪声和系统准确率的下降。《Detecting Beneficial Feature Interactions for Recommender Systems》这篇论文就提出了用GNN去自动检测对推荐系统有利的交叉特征。

首先一个数据集定义如下:
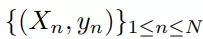

其中ck表示类目特征,xk标志特征的值,J是所有特征的索引。
定义1: 有益的pairwise交互特征
这个定义其实比较简单,就是有一系列特征,所有特征两两组合,成一个大的集合,我们希望从中能找到一个交叉特征子集,它在验证集上的准确率优于其他子集。
定义2:pairwise statistical interaction
这个定义是这样,有x1~xk一共k个特征(特征是向量同理),F(X)能表示成两个分别不依赖xi和xj特征的函数之和,那么我们认为这两个特征间没有pairwise statistical interation,如下式:
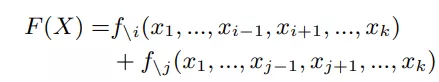

L0-SIGN模型的输入是没有边信息的图,特征是nodes,特征交互是边,如果两个特征nodes之间存在边,代表这两个特征的交互特征对模型有益。
L0-SIGN有两个模块,第一个是L0边预估模块,就是预估边应不应该存在。然后是图分类SIGN模块,SIGN模块如下图所示:
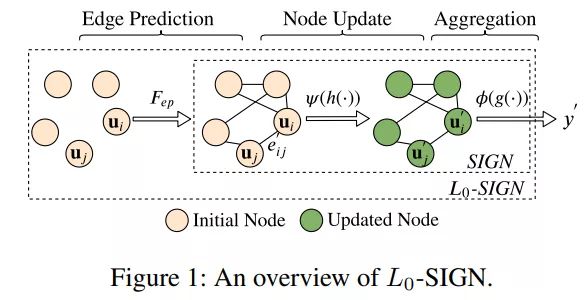
首先有初始化embedding后的nodes,通过边进行交互,然后nodes的表达开始不断更新,最后更新完的所有nodes的表达产出最终预估。整体的预估函数如下:
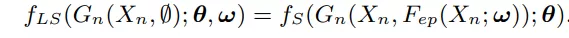
L0 边预估模块:
这里我们使用基于矩阵分解的模型对边进行预估。矩阵分解通过对图的邻接矩阵进行分解,能够非常高效的对边进行建模,而且把所有node转成稠密向量。但在L0-SIGN中,我们并不知道该图的邻接矩阵真实应该是什么样,所以无法进行梯度更新。所以每条边的值,我们通过一个边预估函数:
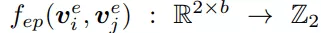
输入两个节点embedding,输出0/1,表示node间是否有边,我们知道无向图邻接矩阵是对称的,所有fep也是对称的:
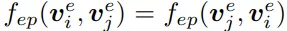
在这篇论文中,fep的输入是两个node向量的element-wise product,fep是多层感知器。在训练的时候,L0就像正则化一样最小化探测边的数量。
SIGN边预估模块:
如果两个节点之间边是1,那么这两个节点之间的交互特征用一个非加法的函数映射:
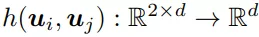
通过该函数映射后的embedding zij就是交互特征。和fep类似,h(ui, uj)函数同样要是对称的。接下来每个节点就可以开始更新过程,每个节点的更新用一个线性aggregation方程:
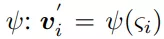
最后所有节点的embedding都会通过一个线性方程g转变成标量,所有的标量再通过一个线性方程转变成SIGN的输出,如下所示:
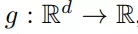
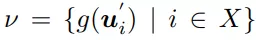
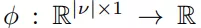

SIGN总体的预估函数如下:
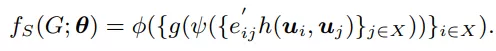
总结完所有模块,L0-SIGN的预估方程就如下所示:
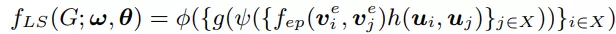

为了确保模型能够成功的找到有益的交互特征,损失函数定义如下:
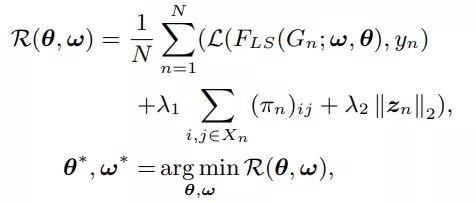
一共3项,第一项就是正常预估偏差,第二项是所有边为1的概率和,第三项是l2正则项。

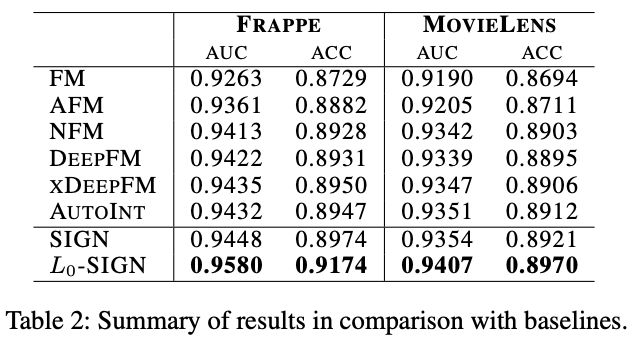
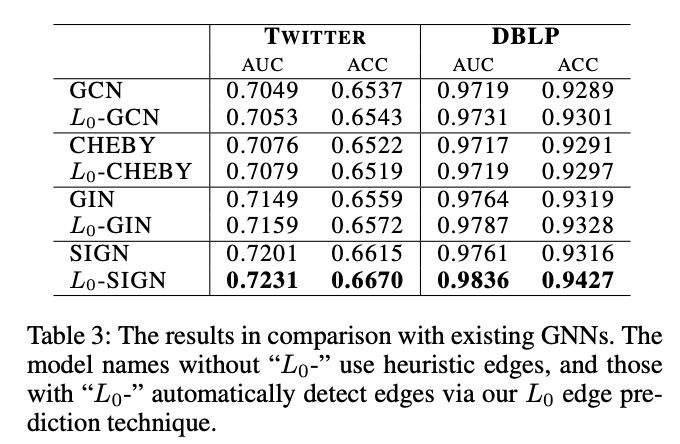
从实验中,我们可以看到无论对比各种FM模型,还是图模型,L0-SIGN都表现最优。
















 940
940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









