






1、训练-training
通过真值框尺寸聚类得到Na个anchor;将输入图像划分为S*S个网格,对每个grid cell,预测(Na*(5+num_class))个值,计算该“长方体”(13*13*125)与真值“长方体”(13*13*125)的损失函数,根据loss调整网络参数。
其中num_class为训练集的class数量。依照原论文取S=13,Na=5,num_class=20。采用多尺度训练时,S可变。
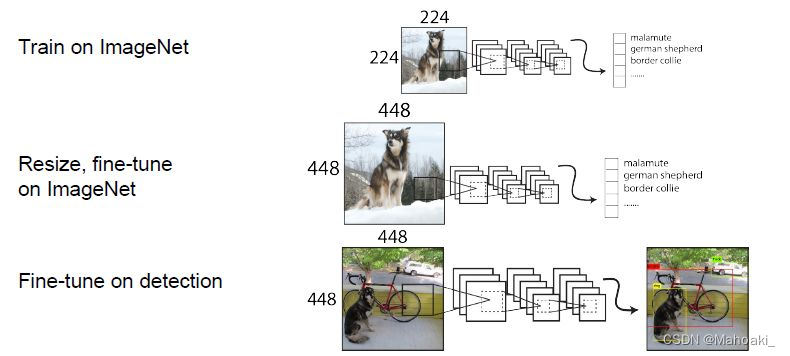
宏观来看,原论文中YOLO v2的训练分为三个阶段:
第一阶段,在标准ImageNet 1000数据集上训练DarkNet-19分类网络,输入图像大小为224*224,共训练160个epoch;
第二阶段,调整输入图像尺寸为448*448,训练10个epoch来微调分类网络;
第三阶段,修改DarkNet-19分类网络为检测网络,删去DarkNet-19的最后一个卷积层及后面的Avgpool层和FC层,改添3个3*3的卷积层和1个1*1的卷积层,训练160个epoch。
1.1 真值
把真值长方体13*13*125三维改写为四维13*13*5*25,初始赋值全0;
真值框与5个anchor中心对齐计算IOU,选取IOU最大的anchor作为best_anchor;计算真值框中心的x,y相对于其所在的grid cell左上角的偏移量(0-1之间),作为真值x,y;计算真值框w,h相对于best_anchor宽高比值的log值,作为真值w,h;该grid cell's best_anchor对应的conf=1,对应obj类别标记为1。
其它值保持为0。
# Set masks
obj_mask[b, best_n, gj, gi] = 1 # 实际包含物体的设置成1
# Coordinates
tx[b, best_n, gj, gi] = gx - gx.floor() # 根据真实框所在位置,得到其相当于网络的位置
ty[b, best_n, gj, gi] = gy - gy.floor()
# Width and height
tw[b, best_n, gj, gi] = torch.log(gw / anchors[best_n][:, 0] + 1e-16)
th[b, best_n, gj, gi] = torch.log(gh / anchors[best_n][:, 1] + 1e-16)
# One-hot encoding of label
tcls[b, best_n, gj, gi, target_labels] = 1 #将真实框的标签转换为one-hot编码形式
# confidence
tconf = obj_mask.float() # 真实框的置信度,也就是11.2 损失函数
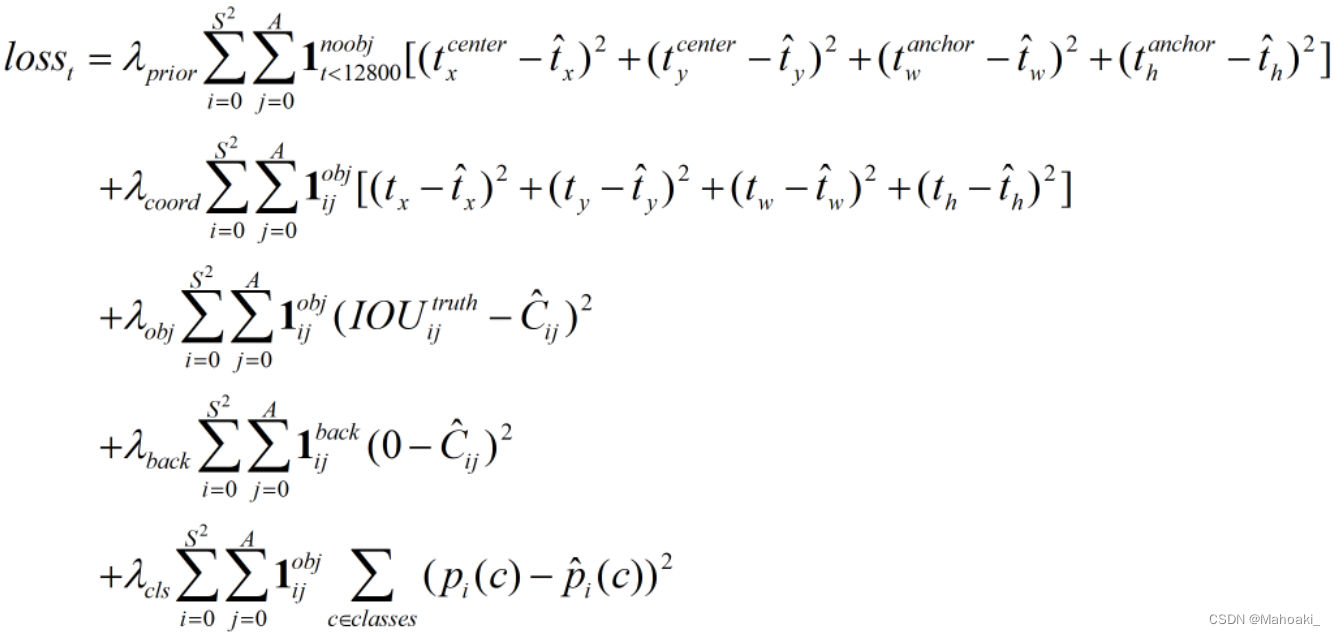
其中,带上标^表示预测值,不带的表示真值。
根据代码以及网友的总结,YOLO v2的损失函数分为4部分:
第一部分,前12800次迭代,计算不负责预测obj的预测框与其对应anchor的位置误差,其中anchor的x,y取该grid cell的中心,主要目的是为了在模型训练的前期更加稳定(不太理解,有的代码就干脆没写这项损失)。取lmd_prior=0.01。
第二部分,负责预测物体的anchor对应的预测框与真值框的位置误差。
*负责预测物体的预测框:真值框中心所在的grid cell的5个anchor分别与真值框中心对齐计算IOU,IOU最大的anchor对应的预测框来负责预测物体。
第三部分,置信度误差,包括 ①负责预测物体的预测框的conf去逼近预测框与真值框的IOU;②负责预测背景的预测框的conf逼近0。
*负责预测背景的预测框:该预测框与所有真值框求IOU,若最大的IOU都小于阈值,则认为该框预测背景。
第四部分,分类误差,对于负责预测物体的预测框,使后20个类条件概率逼近one-hot。
都使用平方和误差计算损失。
综上,不考虑第一部分的话,对于预测物体的anchor对应的预测框需要计算位置误差、置信度误差以及分类误差;对于预测背景的预测框只需要计算置信度误差。
而其它预测框,比如该预测框与某个真值框的IOU大于阈值(不预测背景),但却不是与该真值框IOU最大的anchor对应的预测框(不预测物体)的话,则忽略其损失。
预测值
在损失计算时,真值采用1.1节中计算的真值,预测值需要在网络输出结果的基础上进行处理:
# Get outputs
x = torch.sigmoid(prediction[..., 0]) # Center x
y = torch.sigmoid(prediction[..., 1]) # Center y
w = prediction[..., 2] # Width
h = prediction[..., 3] # Height
pred_conf = torch.sigmoid(prediction[..., 4]) # Conf
pred_cls = torch.sigmoid(prediction[..., 5:]) # Cls pred.x,y都进行sigmoid处理,置信度和类别概率都使用sigmoid函数放缩到0-1之间。
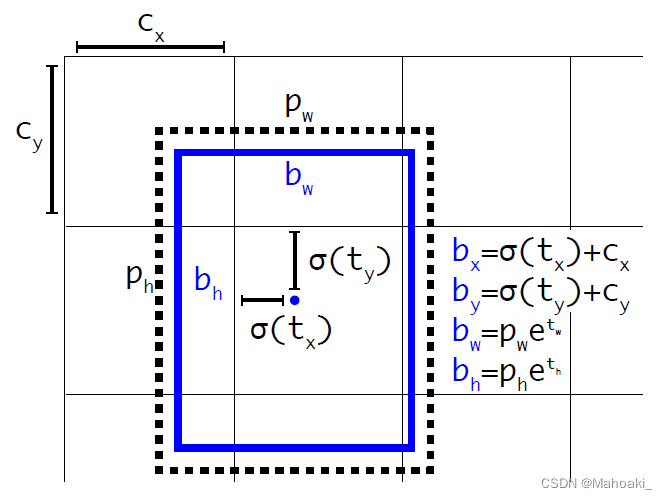
按这张图的公式,损失函数是在以sigmoid(tx)和sigmoid(ty)去逼近bx-cx,by-cy,以tw,th去逼近log(bw/pw)和log(bh/ph)。(bx, by, bw, bh)表示真值框的中心坐标以及宽高,(pw, ph)表示负责预测该物体的anchor的宽高。
2、预测-inference
以下面代码为例,输入图片经过网络后输出prediction,进行进一步处理后返回inference output(若是训练阶段,则直接return prediction再经过1.2节中的预处理,与真值计算损失),对io进行非极大值抑制并在图像上可视化。
# inference
# p:[bs, n_anchor, grid, grid, self.n_output(xywh + obj + classes)]
io = prediction.clone() # inference output
io[..., :2] = torch.sigmoid(io[..., :2]) + self.grid # xy (bs,5,13,13,2)+(1,1,13,13,2)
io[..., 2:4] = torch.exp(io[..., 2:4]) * self.anchor_wh # wh (bs,5,13,13,2)*(1,3,1,1,2)
io[..., :4] *= self.stride # 换算映射回原图尺度 (bs,5,13,13,xywh)*32
torch.sigmoid_(io[..., 4:]) # conf & class probability
return io.view(bs, -1, self.n_output), prediction # [bs,3*13*13,25], [bs,3,13,13,25 ]从prediction到io的处理包括x,y,w,h按照公式计算bx,by,bw,bh(0-13之间的数),再乘以stride=32,得到在原预测图像416*416上的x,y,w,h;对置信度以及类概率都经过sigmoid函数控制在0-1之间。
经过NMS后,在图像上可视化之前,还需要把416*416图像上的x,y,w,h映射回原图像。
3、网络
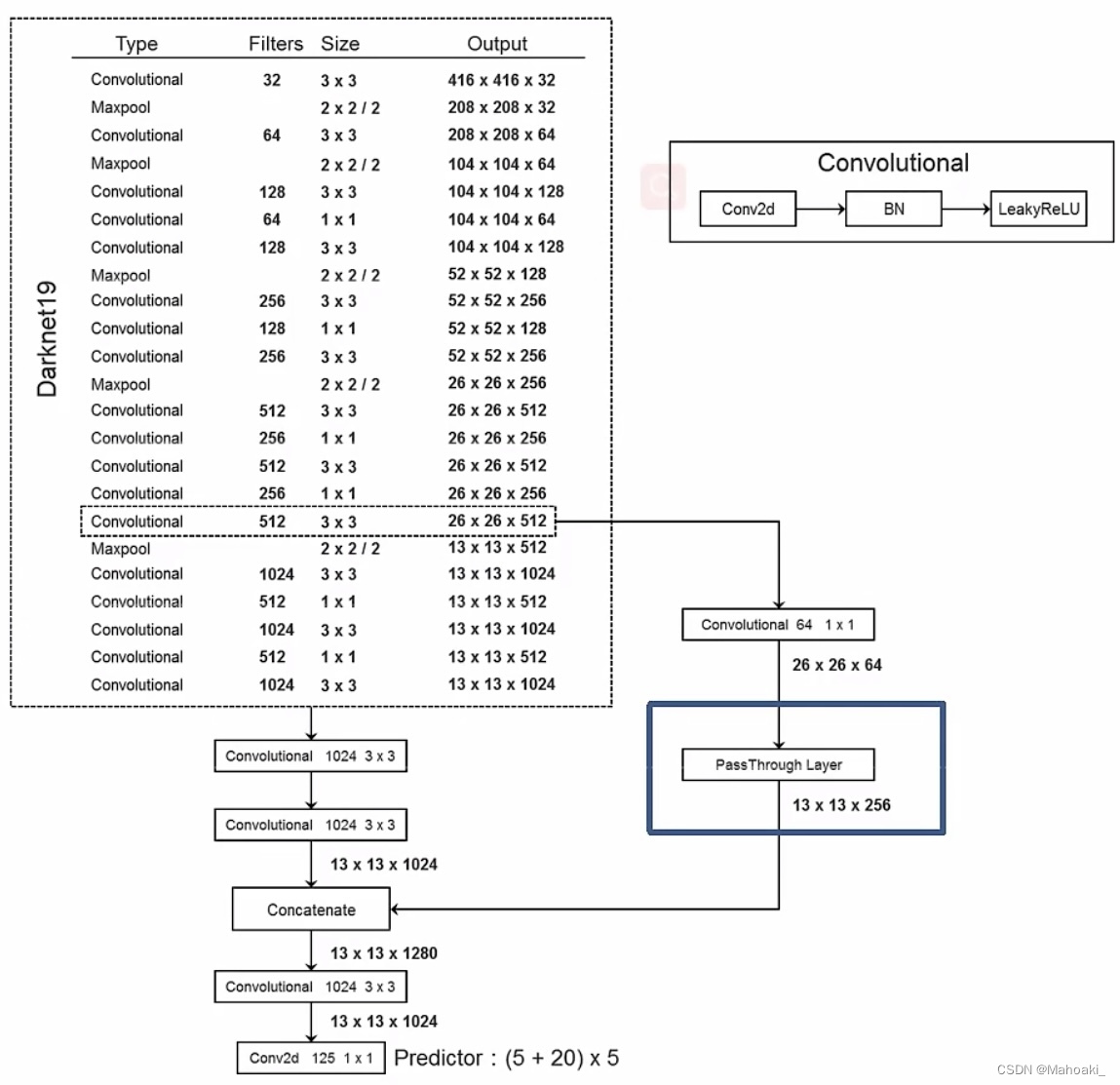
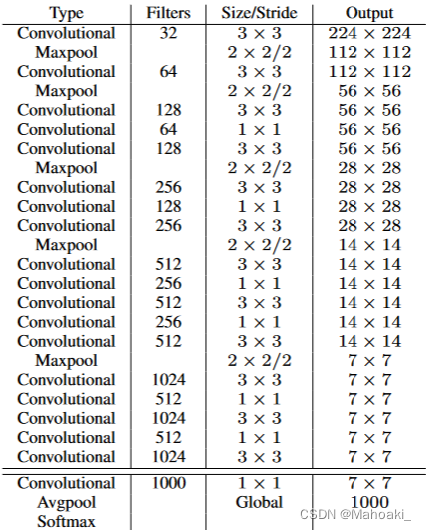
YOLO v2以DarkNet-19为骨干网络,DarkNet-19有19个卷积层,改为检测网络后共有19-1+3+1+1=22层卷积,其中最后一个1*1的卷积为纯卷积(不包含BN层、relu层),有5个maxpool下采样层,图像会缩小为原来的1/32;且增加了passthrough层拼接细粒度特征。
4、Tricks that Better
4.1 Batch Normalization
在所有卷积层(除了最后一个1*1卷积)后面加上BN层,可理解为网络中的每一次输入都做了归一化,收敛相对更容易,并且有一定的正则化效果,可以舍弃Dropout而不会出现过拟合。
4.2 High Resolution Classifier
采用更高分辨率的分类器,即在训练网络时加入的第二阶段,在448*448的图像上再跑10个epoch来微调分类网络。
4.3 Convolutional with Anchor Boxes
由于在YOLO v1中bbx只有两个,且由grid cell来负责预测(1个grid cell只能预测1个物体),v1对于小且密集的物体或者在训练集中没出现过的长宽比的物体检测效果不太好。
v2受Fast R-CNN中region proposal networks(RPN)的启发,引入Anchor Boxes。由anchor来负责预测物体(1个grid cell有5个anchor,则可以预测5个物体,anchor间相互独立),anchor只有w,h信息,预测框的w,h计算相对于anchor的偏移量(比例)。
4.4 Dimension Clusters
在训练集的真值框上使用k-means聚类来得到k个anchor的尺寸。论文中k取5。
聚类计算“距离”时使用1-IOU(box,centroid),和聚类中心框的IOU。
4.5 Direct Location Prediction
RPN中对预测出的偏移量tx,ty没有限制,直接应用到YOLO上会导致如图片左上角的grid cell中的anchor预测了图片右下角的物体,模型很难稳定。
v2还是延续v1中的方法,不直接预测相对anchor中心的偏移量,而是预测相对grid cell左上角的“偏移量”(tx, ty),该“偏移量”经过sigmoid函数约束在0-1范围后才是真正的偏移量。保证了该grid cell的anchor对应的预测框中心都落在该grid cell内。
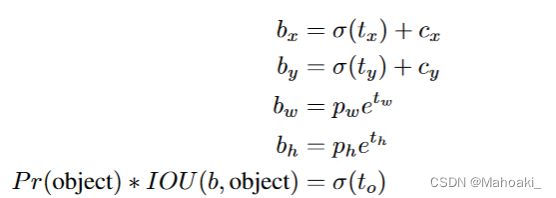
网络输出的是(tx, ty, tw, th, to)。置信度定义仍与v1相同,=IOU*Pr(Obj)。
4.6 Fine-Grained Features
多次下采样后感受野过大,小目标可能丢失,需要融合前面网络的细粒度特征,保留一些细节。
*感受野:特征图上的点能看到原图上多大的区域,网络越往后,感受野越大,特征也越语义化,比如第3层特征提取到“眼睫毛”,第5层提取到“眼睛”,“眼睛”对应于原图像的区域要比“眼睫毛”大。也可以理解为,越往后的特征检测大物体,前面的细粒度特征检测小物体(v3)。
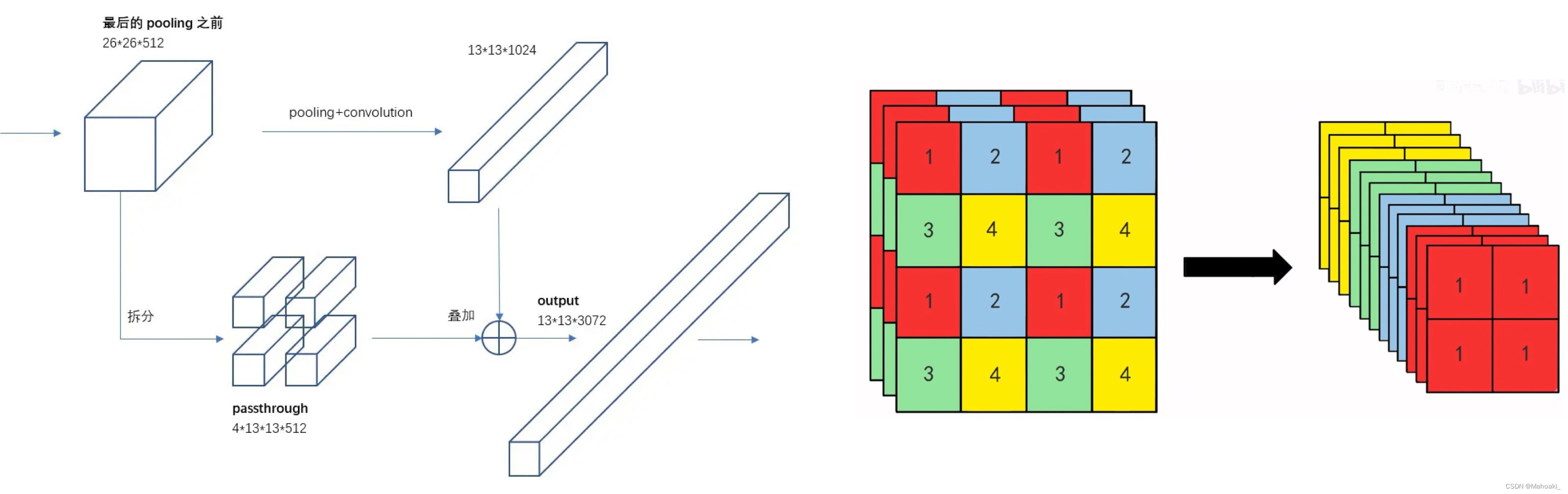
具体passthrough层,结构有点像ResNet,对最近一次下采样前的输出26*26*512经过一次1*1*64的卷积后,进行拆分并堆叠到一起(如上右图),形成13*13*256,再拼接到现在的特征13*13*1024后面,组合成13*13*1280,包括现在的特征与上一次下采样前的细粒度特征。
4.7 Multi-scale Training
YOLO v2中只有卷积层和maxpool层,对输入图像的尺寸没有限制,所以为了进一步提高模型对不同尺寸图像检测的稳定性,可以选择每经过若干次迭代变换输入图像的尺寸,但都需要是32的倍数,比如{320,352,…,608}。
5、Tricks that Faster
很多检测网络都依赖VGG-16作为网络框架,它很好但太复杂了,作者大人根据GoogLeNet自己写了一个分类网络框架——DarkNet-19,使用全局平均池化(global average pooling)代替全连接层,再接softmax层做分类。
全局平均池化
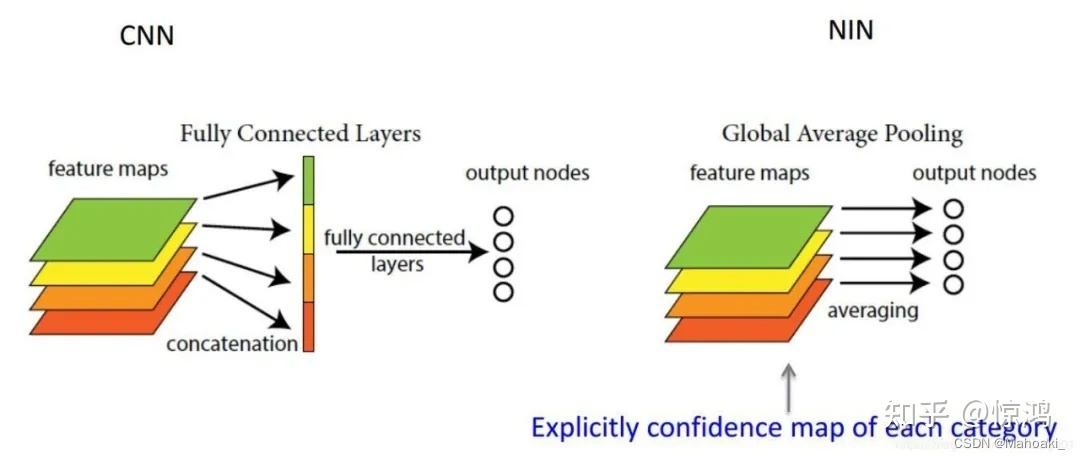
全连接层是将提取的所有特征通过wx+b拉成一个长条,再通过wx+b压成需要的维度;全局平均池化直接在每一个通道上进行平均,如DarkNet-19中的7*7*1000变为1000,就是将每一个7*7共49个特征进行了平均,最终就只剩1*1000个特征。
GAP的优势在于 ①参数更少,抑制过拟合;②输入尺寸更灵活;③可解释的雏形(还没了解)。
6、Tricks that Stronger
没看。看摘要的意思好像是,检测数据集比较少,但分类数据集现在比较多,在COCO检测数据集和ImageNet分类数据集上同时训练,对于ImageNet上那些没有检测数据的类也可以检测出来了,这样作者写道,他的YOLO9000可以检测超过9000种不同类别的物体!
7、总结
个人认为,YOLO v2相比v1最大的改进在于引入了anchor,然后改用了DarkNet-19网络结构,并且在卷积层后都加入了BN层。速度较之更快,mAP也更高。
参考博客:
YOLOV2网络模型_yolov2网络结构_Pywin的博客-CSDN博客
目标检测|YOLOv2原理与实现(附YOLOv3) - 知乎 (zhihu.com)
YOLO v2 损失函数源码分析 - 一只有恒心的小菜鸟 - 博客园 (cnblogs.com)















 380
380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









