






PVT
Abstract
虽然卷积神经网络(cnn)在计算机视觉方面取得了巨大的成功,但本研究研究了一个更简单、无卷积的骨干网络,可用于许多密集预测任务。与最近提出的专门用于图像分类的视觉变压器(ViT)不同,我们介绍了金字塔视觉Transformer(PVT),它克服了将Transformer移植到各种密集预测任务中的困难。与目前的技术相比,PVT有几个优点。(1)与ViT输出分辨率低、计算和存储成本高不同,PVT不仅可以在图像的密集分区上进行训练以获得高输出分辨率,这对密集预测很重要,而且使用渐进收缩金字塔来减少大型特征图的计算量。(2) PVT继承了CNN和Transformer的优点,无需卷积即可成为各种视觉任务的统一主干,可直接替代CNN主干。(3)我们通过大量的实验验证了PVT,表明它提高了许多下游任务的性能,包括目标检测,实例和语义分割。
Introduction
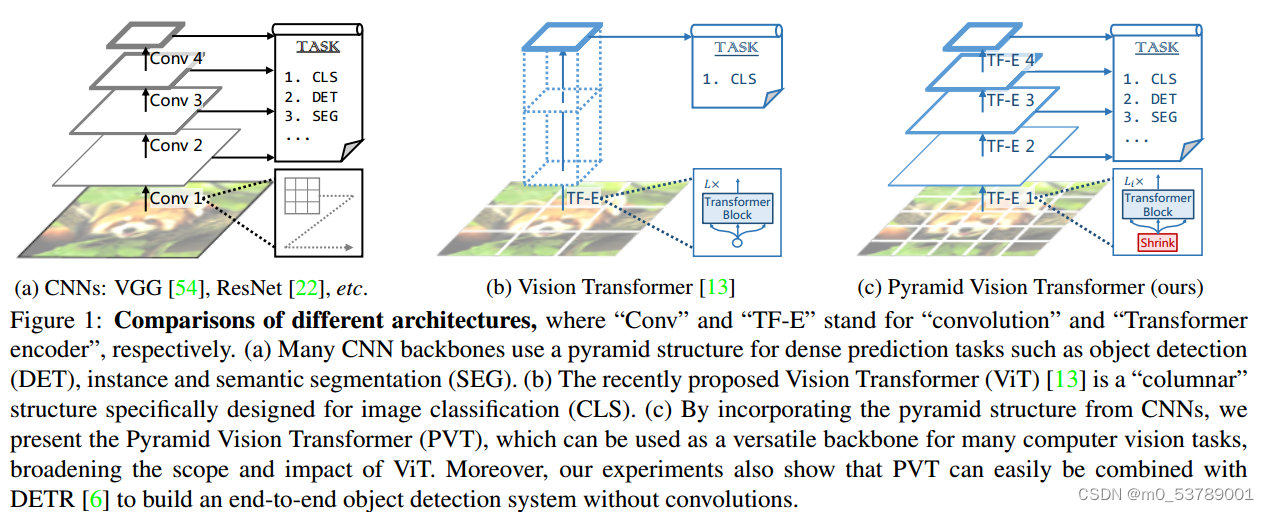
本工作提出了一种纯Transformer骨干,称为金字塔视觉变压器(PVT),它可以在许多下游任务中作为CNN骨干的替代方案,包括图像级预测以及像素级密集预测。具体来说,如图1 ©所示,我们的PVT通过以下方式克服了传统Transformer的困难:(1)采用细粒度图像块(即每个块4×4像素)作为输入来学习高分辨率表示,这对于密集预测任务至关重要;(2)引入渐进式收缩金字塔,随着网络的加深减少Transformer的序列长度,显著降低计算成本;(3)采用空间约简注意层,进一步降低学习高分辨率特征时的资源消耗。拟议的PVT具有以下优点。首先,与传统的CNN主干(见图1 (a))相比,我们的PVT总是产生一个全局接受野,它更适合于检测和分割。其次,与ViT相比(见图1 (b)),由于其先进的金字塔结构,我们的方法可以更容易地插入到许多具有代表性的密集预测管道中。
- 我们提出了金字塔视觉变压器(PVT),这是第一个专为各种像素级密集预测任务设计的纯变压器骨干。结合我们的PVT和DETR,我们可以构建一个端到端的目标检测系统,没有卷积和手工制作的组件,如密集锚点和非最大抑制(NMS)。
- 在将Transformer移植到密集预测时,我们克服了许多困难,通过设计渐进收缩金字塔和空间减少注意(SRA)。这些能够减少Transformer的资源消耗,使PVT能够灵活地学习多尺度和高分辨率特征。
Pyramid Vision Transformer (PVT)
Overall Architecture
我们的目标是将金字塔结构引入到Transformer框架中,这样它就可以为密集的预测任务(例如,对象检测和语义分割)生成多尺度特征映射。PVT的概述如图3所示。与CNN骨干网相似[22],我们的方法有四个阶段,分别生成不同尺度的特征图。所有阶段共享一个类似的架构,它包括一个补丁嵌入层和Li Transformer编码器层。
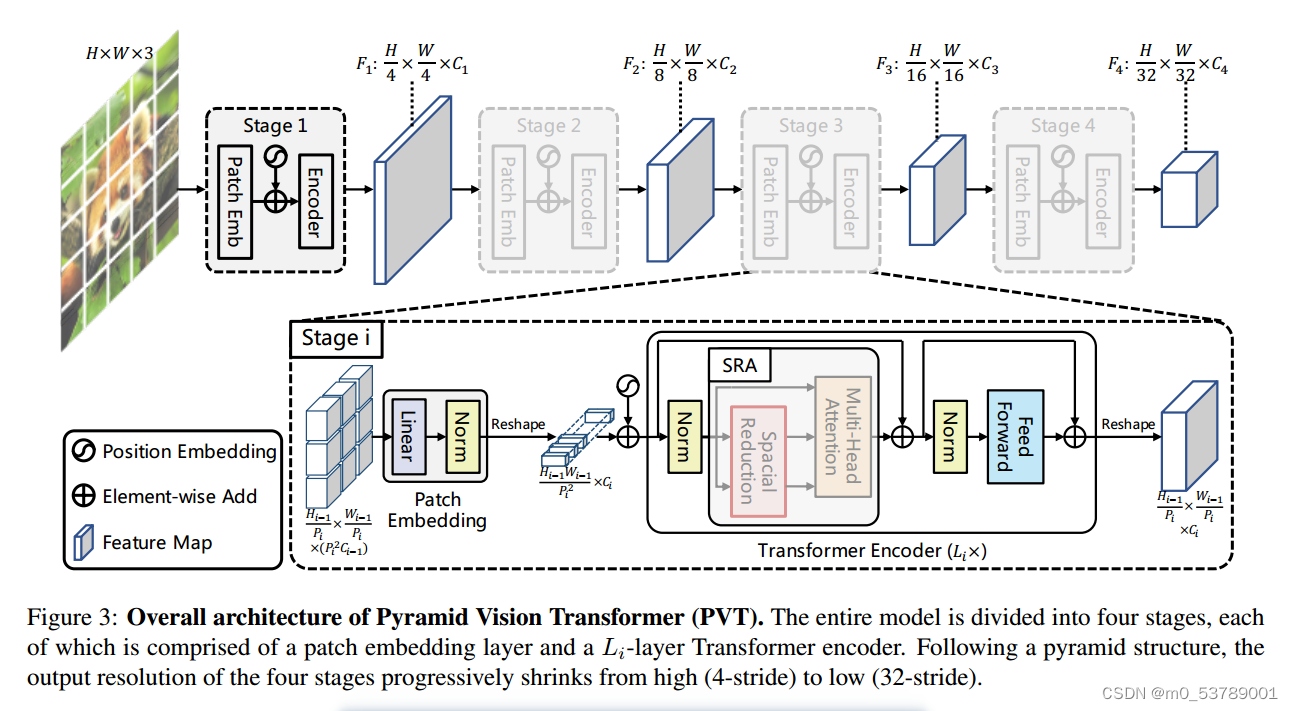
与CNN骨主干网络[54,22]使用不同的卷积步幅来获得多尺度特征图不同,我们的PVT使用渐进收缩策略通过补丁嵌入层来控制特征图的尺度。这样,我们可以在每个阶段灵活地调整特征映射的比例,从而可以为Transformer构建一个特征金字塔。
Feature Pyramid for Transformer

Transformer Encoder
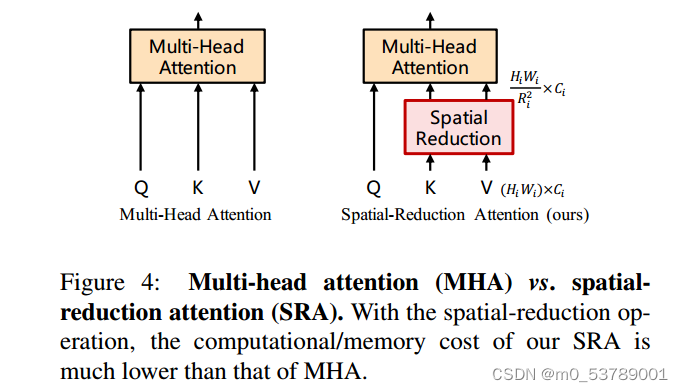
阶段i的Transformer编码器有Li个编码器层,每个编码器层由注意层和前馈层组成[64]。由于PVT需要处理高分辨率(例如,4步)的特征图,我们提出了一个空间减少注意(SRA)层来取代编码器中传统的多头注意(MHA)层[64]。
与MHA类似,我们的SRA接收一个查询Q、一个键K和一个值V作为输入,并输出一个精细的特征。不同之处在于,我们的SRA在注意操作之前减少了K和V的空间尺度(见图4),这在很大程度上减少了计算/内存开销。第一阶段的SRA详情可表述如下:
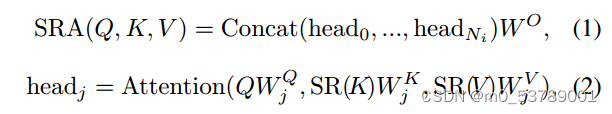
Model Details
综上所述,我们方法的超参数如下:

Discussion
- PVT和ViT都是没有卷积的纯Transformer模型。它们之间的主要区别是金字塔结构。与传统Transformer相似[64],ViT的输出序列长度与输入序列长度相同,即ViT的输出为单量程(见图1 (b))。此外,由于资源有限,ViT的输入是粗粒度的(如patch大小为16或32像素),因此其输出分辨率相对较低(如16步或32步)。因此,很难直接将ViT应用于需要高分辨率或多尺度特征图的密集预测任务。
- 我们的PVT打破了传统的Transformer,引入了一个渐进的收缩金字塔。它可以像传统的CNN主干一样生成多尺度特征图。此外,我们还设计了一个简单而有效的注意力层- sra,用于处理高分辨率特征图并降低计算/内存成本。得益于以上设计,我们的方法相对于ViT具有以下优点:1)更加灵活——可以在不同阶段生成不同尺度/通道的特征图;2)通用性更强——可以在大多数下游任务模型中轻松插入和播放;3)对计算/内存更友好-可以处理更高分辨率的特征映射或更长的序列。
Conclusions and Future Work
我们介绍了PVT,一个纯Transformer主干,用于密集预测任务,如目标检测和语义分割。为了在有限的计算/内存资源下获得高分辨率和多尺度的特征地图,我们开发了一个渐进收缩金字塔和一个空间约简关注层。大量的目标检测和语义分割基准实验验证了我们的PVT在相当数量的参数下比设计良好的CNN主干更强。
尽管PVT可以作为CNN主干(如ResNet、ResNeXt)的替代方案,但仍有一些为CNN设计的特定模块和操作在本文中没有考虑,如SE[23]、SK[36]、扩张卷积[74]、模型修剪[20]和NAS[61]。此外,随着多年的快速发展,已经出现了许多设计良好的CNN骨干网,如Res2Net[17]、EfficientNet[61]、ResNeSt[79]。相比之下,基于transformer的计算机视觉模型仍处于早期发展阶段。















 1692
1692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









