







本文主要就是介绍搭建模型和模型训练了!!
1. AAMI 标准
根据 AAMI (简称:美国心脏病协会) 提供的标准:将心拍分为五大类,分别是N、S、V、F和Q,五大类又包含了一些小类;具体如下,大家啊可以参考一下:
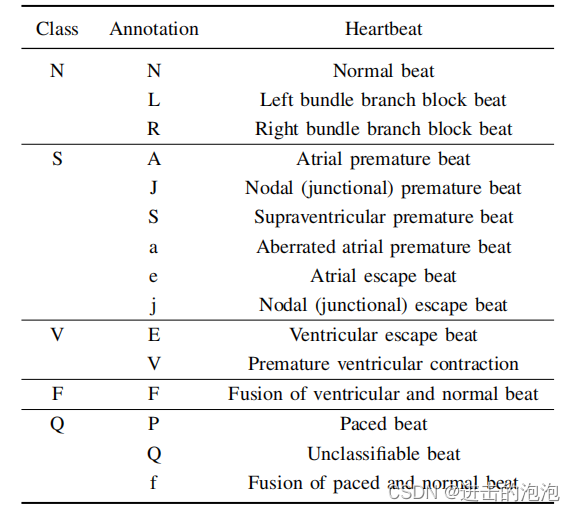
在目前大多数论文的工作中,都是针对于以上五大类进行分类。但由于S类和V类的特征很相似,往往导致准确率降低,不是很高;当然,也有很多工作专门针对于这两类。
全部代码可看结尾。
2. 模型搭建和训练
本篇博客则主要简单介绍一下以卷积神经网络CNN为代表的深度学习模型对N、L、R、A和V五大类进行分类。具体如下(代码的解释已经在注释中,大家可以参考):
实验所用数据集:MIT-BIH Arrhythmia Database
import wfdb
import pywt
import seaborn
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
# 测试集在数据集中所占的比例
RATIO = 0.2
# 小波去噪预处理
def denoise(data):
# 小波变换
coeffs = pywt.wavedec(data=data, wavelet='db5', level=9)
cA9, cD9, cD8, cD7, cD6, cD5, cD4, cD3, cD2, cD1 = coeffs
# 阈值去噪
threshold = (np.median(np.abs(cD1)) / 0.6745) * (np.sqrt(2 * np.log(len(cD1))))
cD1.fill(0)
cD2.fill(0)
for i in range(1, len(coeffs) - 2):
coeffs[i] = pywt.threshold(coeffs[i], threshold)
# 小波反变换,获取去噪后的信号
rdata = pywt.waverec(coeffs=coeffs, wavelet='db5')
return rdata
# 读取心电数据和对应标签,并对数据进行小波去噪
def getDataSet(number, X_data, Y_data):
ecgClassSet = ['N', 'A', 'V', 'L', 'R']
# 读取心电数据记录
print("正在读取 " + number + " 号心电数据...")
# 读取MLII导联的数据
record = wfdb.rdrecord('D:/MIT-BIH-360/' + number, channel_names=['MLII'])
data = record.p_signal.flatten()
rdata = denoise(data=data)
# 获取心电数据记录中R波的位置和对应的标签
annotation = wfdb.rdann('D:/MIT-BIH-360/' + number, 'atr')
Rlocation = annotation.sample
Rclass = annotation.symbol
# 去掉前后的不稳定数据
start = 10
end = 5
i = start
j = len(annotation.symbol) - end
# 因为只选择NAVLR五种心电类型,所以要选出该条记录中所需要的那些带有特定标签的数据,舍弃其余标签的点
# X_data在R波前后截取长度为300的数据点
# Y_data将NAVLR按顺序转换为01234
while i < j:
try:
# Rclass[i] 是标签
lable = ecgClassSet.index(Rclass[i])
# 基于经验值,基于R峰向前取100个点,向后取200个点
x_train = rdata[Rlocation[i] - 100:Rlocation[i] + 200]
X_data.append(x_train)
Y_data.append(lable)
i += 1
except ValueError:
i += 1
return
# 加载数据集并进行预处理
def loadData():
numberSet = ['100', '101', '103', '105', '106', '107', '108', '109', '111', '112', '113', '114', '115',
'116', '117', '119', '121', '122', '123', '124', '200', '201', '202', '203', '205', '208',
'210', '212', '213', '214', '215', '217', '219', '220', '221', '222', '223', '228', '230',
'231', '232', '233', '234']
dataSet = []
lableSet = []
for n in numberSet:
getDataSet(n, dataSet, lableSet)
# 转numpy数组,打乱顺序
dataSet = np.array(dataSet).reshape(-1, 300)
lableSet = np.array(lableSet).reshape(-1, 1)
train_ds = np.hstack((dataSet, lableSet))
np.random.shuffle(train_ds)
# 数据集及其标签集
X = train_ds[:, :300].reshape(-1, 300, 1)
Y = train_ds[:, 300]
# 测试集及其标签集
shuffle_index = np.random.permutation(len(X))
# 设定测试集的大小 RATIO是测试集在数据集中所占的比例
test_length = int(RATIO * len(shuffle_index))
# 测试集的长度
test_index = shuffle_index[:test_length]
# 训练集的长度
train_index = shuffle_index[test_length:]
X_test, Y_test = X[test_index], Y[test_index]
X_train, Y_train = X[train_index], Y[train_index]
return X_train, Y_train, X_test, Y_test
# 构建CNN模型
def buildModel():
newModel = tf.keras.models.Sequential([
tf.keras.layers.InputLayer(input_shape=(300, 1)),
# 第一个卷积层, 4 个 21x1 卷积核
tf.keras.layers.Conv1D(filters=4, kernel_size=21, strides=1, padding='SAME', activation='tanh'),
# 第一个池化层, 最大池化,4 个 3x1 卷积核, 步长为 2
tf.keras.layers.MaxPool1D(pool_size=3, strides=2, padding='SAME'),
# 第二个卷积层, 16 个 23x1 卷积核
tf.keras.layers.Conv1D(filters=16, kernel_size=23, strides=1, padding='SAME', activation='relu'),
# 第二个池化层, 最大池化,4 个 3x1 卷积核, 步长为 2
tf.keras.layers.MaxPool1D(pool_size=3, strides=2, padding='SAME'),
# 第三个卷积层, 32 个 25x1 卷积核
tf.keras.layers.Conv1D(filters=32, kernel_size=25, strides=1, padding='SAME', activation='tanh'),
# 第三个池化层, 平均池化,4 个 3x1 卷积核, 步长为 2
tf.keras.layers.AvgPool1D(pool_size=3, strides=2, padding='SAME'),
# 第四个卷积层, 64 个 27x1 卷积核
tf.keras.layers.Conv1D(filters=64, kernel_size=27, strides=1, padding='SAME', activation='relu'),
# 打平层,方便全连接层处理'
tf.keras.layers.Flatten(),
# 全连接层,128 个节点 转换成128个节点
tf.keras.layers.Dense(128, activation='relu'),
# Dropout层,dropout = 0.2
tf.keras.layers.Dropout(rate=0.2),
# 全连接层,5 个节点
tf.keras.layers.Dense(5, activation='softmax')
])
return newModel
def plotHeatMap(Y_test, Y_pred):
con_mat = confusion_matrix(Y_test, Y_pred)
# 绘图
plt.figure(figsize=(4, 5))
seaborn.heatmap(con_mat, annot=True, fmt='.20g', cmap='Blues')
plt.ylim(0, 5)
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
def main():
# X_train,Y_train为所有的数据集和标签集
# X_test,Y_test为拆分的测试集和标签集
X_train, Y_train, X_test, Y_test = loadData()
print(X_train.shape)
model = buildModel()
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy', metrics=['accuracy']
# metrics: 列表,包含评估模型在训练和测试时的性能的指标,典型用法是metrics=[‘accuracy’]。
)
model.summary()
# 训练与验证
model.fit(X_train, Y_train, epochs=30, batch_size=128, validation_split=RATIO) # validation_split 训练集所占比例
# 预测
Y_pred = model.predict(X_test)
print(Y_pred)
if __name__ == '__main__':
main()
根据结果来看,准确率最后可以达到 98%~99% 左右。
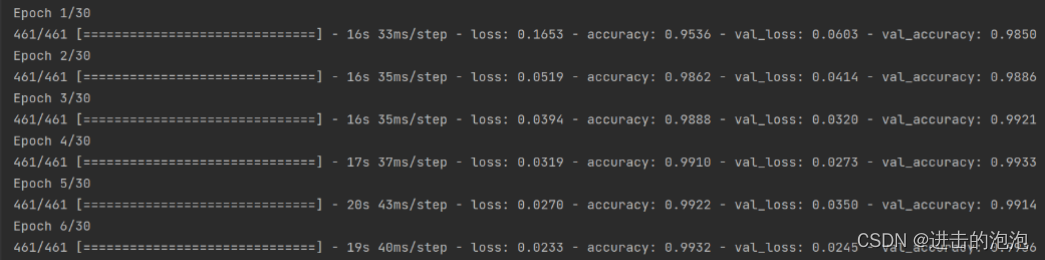
由于以 心律失常ECG数据 为代表的医疗数据其本质上是一种时间序列数据,也可以使用RNN、LSTM等时间序列模型进行训练,可以取得较好的训练效果。
3. 模型搭建环境
根据一些同学反馈,现将环境版本公布如下:
- wfdb 3.4.1
- PyWavelets(pywt) 1.1.1
- seaborn 0.11.2
- numpy 1.19.5
- tensorflow 2.6.3
全部代码:https://github.com/AwakenPurity/DeepL-Learning-ECG-Classification

















 536
536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











