







 这篇博客深入探讨了强化学习的基本概念,包括环境状态、动作、智能体、策略函数和奖励。政策函数是学习的重点,它决定了智能体在特定环境下的行为。奖励的设置对强化学习的性能至关重要,通过调整奖励可以引导智能体学习更优的策略。博客还介绍了强化学习的两个随机性来源:动作随机性和状态转移的随机性。此外,解释了强化学习的整体流程和两种主要方法:基于策略的学习与价值学习。状态价值函数和动作价值函数Qπ是评估策略和状态的关键,其中Q*表示最优动作价值函数。
这篇博客深入探讨了强化学习的基本概念,包括环境状态、动作、智能体、策略函数和奖励。政策函数是学习的重点,它决定了智能体在特定环境下的行为。奖励的设置对强化学习的性能至关重要,通过调整奖励可以引导智能体学习更优的策略。博客还介绍了强化学习的两个随机性来源:动作随机性和状态转移的随机性。此外,解释了强化学习的整体流程和两种主要方法:基于策略的学习与价值学习。状态价值函数和动作价值函数Qπ是评估策略和状态的关键,其中Q*表示最优动作价值函数。
初步介绍基本概念
环境state、动作action、智能体agent、策略函数policy、奖励reward。
例如“超级马里奥”的游戏中,state是当前所处环境的状态;智能体agent是马里奥;动作action有[向左、向上、向右]三种;策略函数如下,就是在当前环境下马里奥做出各个动作的概率。
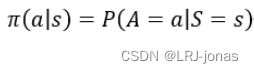
policy函数是强化学习的学习内容
举个例子,如果想利用强化学习使机器自主操纵马里奥,当输入这张图片到policy函数π,agent(马里奥)会做出三种动作中的一种,例如policy函数算出“向左概率0.2,向右概率0.1,向上跳概率为0.7”,policy函数自动操作它做一个随机抽样,以0.2的概率向左走,0.1的概率向右走,0.2的概率向上跳,强化学习就是学这个policy函数。只要有了这个policy函数,就可以让它自动操作马里奥打游戏了。


reward影响强化学习的性能
定义reward 的值 R,以指导policy概
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











