






前言
1、预处理-基于DiAD的过曝区域的去干扰
问题和分析
过曝区域对异常检测具有较大影响:
- 对于异常数据来说,但模型检测为异常时,是否是因为其过曝区域的影响
- 对于正常数据来说,过曝区域容易使其被检测为异常
之前的方法是在检测后形成patch-score时对其进行加权处理,但是,但过曝影响的区域过大不能进行全部的消除,同时增加加权处理的面积对正常区域和异常区域都是影响。
过曝区域一方面在实际检测和图像增强可以一定程度缓解其影响,同时在实际工业检测要求中,尽量减少漏检的发生,对于过曝等应按照异常处理,进行多次检测。
但是对模型实际性能的检测来说,应该避免过曝的影响。针对之前补偿算法的不足,提出一种基于图像生成及融合的去干扰办法。
思路与结果
对待检图片进行过曝区域的判定与检测,然后输入Diad模型获取重建图片,Diad模型会根据输入图片将与正常分布不同的部分重建,重建图片与原始图片在过曝区域进行加权处理获得去干扰图片。
diad原理之前有述。
结果:

分别为原图、融合后的图片、异常热力图。
从结果来看,异常热力图以及置信度(0.468,0.507),融合后的效果比原始图像、部分区域加权补偿较好,但是由于融合边界问题,置信度并没有降低到一个较为满意的值。
2、Patchcore-cait
思路
文献fastflow中提出了基于transform和基于cnn网络两种的backbone。
transform 可以提供全局感受野,并更好地利用全局和局部信息,同时保持不同深度的语义信息。现有检测效果中,对于一些较浅的划痕因其与背景纹路较为相似故检测检测较为困难。故尝试transform特征提取网络,希望在特征提取过程中对于背景纹路整体性会利用更好。
实验
Cait and Deit 是典型的 vit 模型,实验选取cait
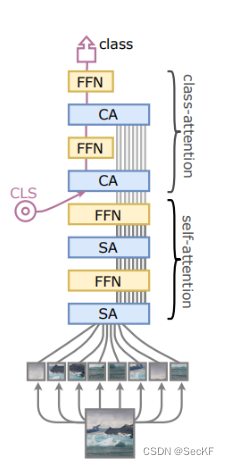
从timm下载预训练模型,对于图片进行处理,以tensor形式输入得到预训练网络得到初步的提取特征。冻结网络参数,使其在训练过程中不在更新。之后将位置编码加到特征上,再进行归一化及重塑处理,获取特征。
结果
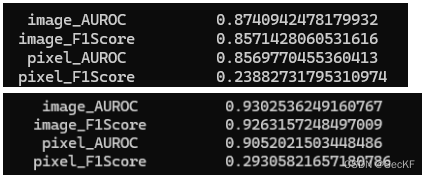
上为cnn提取结果,下为cait。结果提升较好。















 2000
2000











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









