







 文章介绍了PatchCore模型,一种在工业异常检测中表现出色的方法,利用预训练模型和CoresetSampling技术来提高效率。模型通过比较测试图像特征与内存库的正常样本,实现像素级异常评分。实验结果显示,PatchCore在MVTec数据集等上优于传统方法,同时保持了快速的推理速度。
文章介绍了PatchCore模型,一种在工业异常检测中表现出色的方法,利用预训练模型和CoresetSampling技术来提高效率。模型通过比较测试图像特征与内存库的正常样本,实现像素级异常评分。实验结果显示,PatchCore在MVTec数据集等上优于传统方法,同时保持了快速的推理速度。
1. 概述
异常检测问题在工业图像数据分析中扮演着至关重要的角色,其目的是从大量正常数据中识别出异常行为或模式。这一任务的挑战在于,正常数据的样本相对容易获取,而异常情况却因其稀有性和多样性而难以收集。为了解决这一问题,研究者们开发了多种方法,其中一种备受关注的方法是PatchCore模型。
PatchCore模型是一种先进的工业异常检测方法,它在MVTec数据集上取得了最先进的性能(State of the Art,简称SOTA。这个数据集是工业领域内公认的用于评估异常检测算法的标准数据集,包含了多种不同类别的工业产品图像,既有正常样本也有异常样本。
PatchCore的关键优势在于它的特征提取机制。传统的异常检测方法通常需要大量的标注数据来训练模型,以学习正常和异常图像之间的差异。然而,PatchCore采用了一种不同的策略,它利用了预训练模型(如WideResNet50)来提取图像特征。这种方法的优势在于,预训练模型已经在大型数据集(如ImageNet)上学习了丰富的视觉特征,因此可以直接应用于新的任务,而无需进行额外的特征提取训练。
源码地址:https://github.com/amazon-science/patchcore-inspection
论文地址:https://arxiv.org/abs/2106.08265

2. 算法实现
2.1 整体模型
PatchCore模型在工业异常检测领域中的一项重要创新是其能够评估图像中每个像素的异常程度。这种细致的异常评分机制不仅使得模型能够判断整个图像是否异常,还能够精确地定位到异常发生的具体区域。
在PatchCore模型中,首先会构建一个内存库(Memory Bank),该内存库包含了正常图像的特征向量。这些特征向量是通过预训练的神经网络模型从正常图像中提取出来的,它们有效地捕捉了正常样本的视觉特征。在模型训练阶段,PatchCore仅使用正常图像来构建这个内存库,不涉及任何异常样本。
当有新的测试图像进入模型时,PatchCore会从这些图像中提取特征向量,并与内存库中存储的正常特征向量进行比较。通过计算测试图像特征向量与内存库中最接近的特征向量之间的距离,模型可以评估测试图像的异常程度。这个距离越小,表明测试图像与正常样本越相似,越可能是正常图像;反之,距离越大,表明测试图像与正常样本的差异越显著,越可能是异常图像。
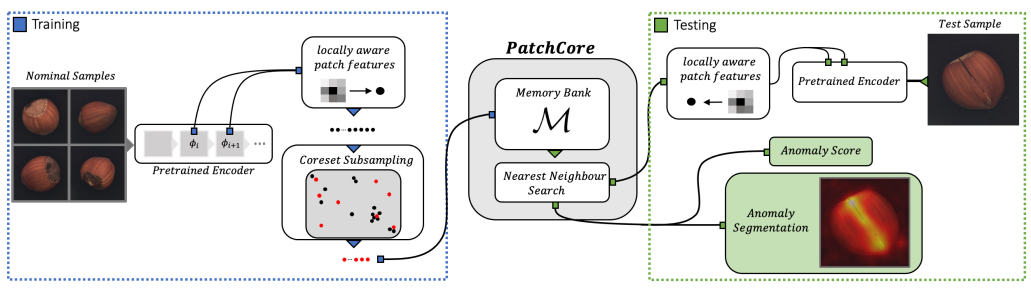
上图的左侧(蓝色虚线框)显示的是学习,右侧(绿色虚线框)显示的是推理流程。
在训练过程中,首先将正常图像通过一个预训练的卷积神经网络(CNN)模型,这个模型负责提取每个斑块的特征向量。这里的CNN模型可以是如WideResNet50这类在大型数据集上预训练过的网络,它们已经具备了强大的特征提取能力。接着,从这些特征向量中进行采样,选择最具代表性的一部分特征向量,将它们存储在记忆库中。
推理(Inference)阶段是PatchCore模型进行异常检测的关键时期。在这一阶段,新的测试图像同样通过训练有素的CNN模型来提取每个斑块的特征向量。这些特征向量代表了测试图像中每个斑块的视觉内容。
随后,模型会计算测试图像中每个斑块的特征向量与记忆库中存储的正常特征向量之间的距离。这个距离可以被视为异常程度的度量:距离越大,表明测试图像中的斑块与正常样本的差异越大,因此越可能是异常的。通过这种方式,模型能够评估整个图像的异常情况,并且能够对每个像素进行异常评分,从而精确地定位到异常区域。
2.2 局部感知
在PatchCore模型中,局部感知的补丁特征是通过从图像中提取逐个补丁的特征向量来实现的。这一过程首先利用了一个已经在ImageNet数据集上完成训练的卷积神经网络(CNN)模型。该模型在此任务中的作用是提取图像特征,而不是进行进一步的训练或调整。
随后,从预训练的CNN模型中得到的特征向量会经过自适应平均池化处理,这一步骤确保了不同尺寸的输入图像能够产生具有一致维度的特征向量,为后续的异常检测工作奠定了基础。
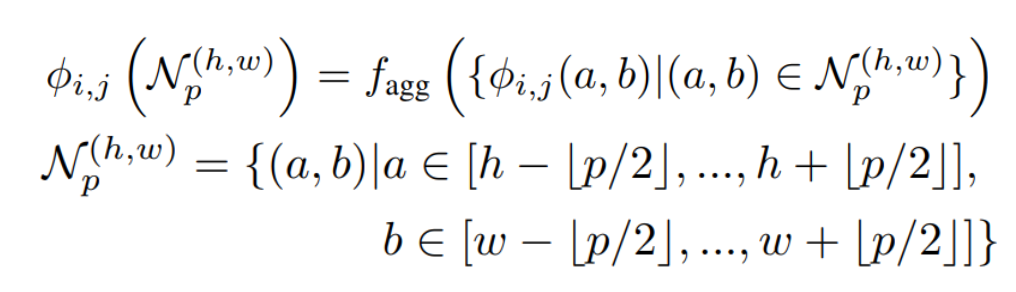
在选择合适的CNN模型层级来提取特征向量时,最后一层虽然提供了高度聚合和高抽象度的特征向量,但存在两个主要问题。首先,深层特征由于经过多次卷积和池化操作,分辨率较低,可能导致局部细节特征的丢失。其次,最后一层的特征向量可能受到原始训练任务——如ImageNet分类问题——的影响,从而在不同领域的异常检测任务中表现出偏差。
鉴于这些问题,本文提出了使用模型中间层的特征向量进行异常检测的方法。这样做可以在保持较高抽象水平的同时,减少预训练任务对特征向量的影响。实验结果表明,使用中间层特征向量的方法在异常检测任务中取得了很好的效果。
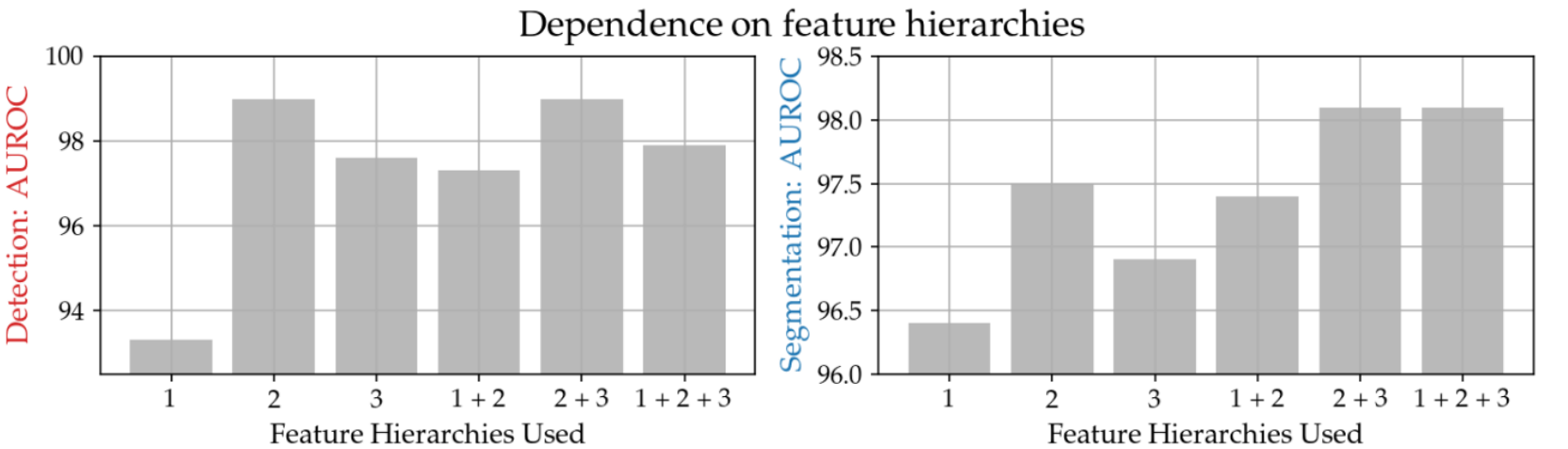
根据实验数据,特征向量的提取层级与异常检测任务的准确性之间存在一定的关系。图表显示,当使用模型的第二层(横轴表示层级编号,数字越小代表层级越浅)时,检测准确率非常高。这一结果证实了PatchCore模型确实从第二和第三层(即2+3)提取了特征向量【3】,这表明在保持特征的局部细节和减少预训练任务影响之间找到了一个平衡点。
2.3 补丁特征记忆库
其次是补丁特征记忆库(Coreset-reduced patch-feature memory bank),这部分是将得到的特征向量存储在Memory Bank中。随着训练数据数量的增加,更多的数据需要存储在记忆库中,这增加了评估测试数据所需的推理时间,并增加了存储的内存容量。因此,本文提出使用Coreset Sampling对得到的特征向量进行采样,并将其存储在Memory Bank中。
采样方法表示如下:其中M是采样前的特征向量集,MC是采样后的特征向量集。
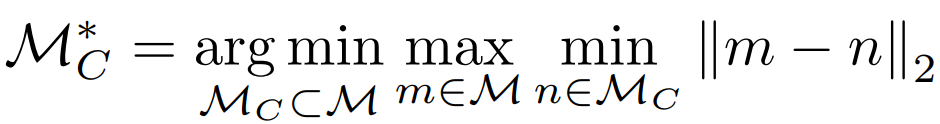
上述公式意味着,进行抽样时,要使预抽样的特征向量(m)和后抽样的特征向量中的最大最小距离最小。
然而,这个优化问题是NP-hard,需要大量的计算时间来获得最优解。因此,在本文中,采用了以下两种创新方法,以更快地获得一个接近最优的解决方案。
- 贪婪法的逼近:以前的研究中使用的方法已经被采纳。
- 通过随机投影降低维度:降低特征向量的维度可以降低上述优化问题的计算复杂度,其依据是Johnson-Lindenstrauss补码,即降维可以实现良好的准确性。
下图将Coreset Sampling应用于虚拟数据,并将结果可视化。
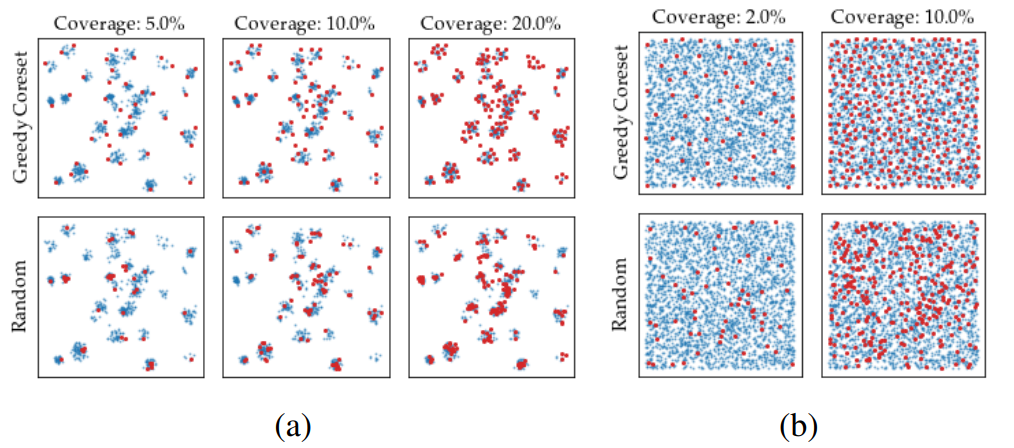
下表比较了随机抽样和Coreset抽样在两个虚拟数据集(a)和(b)上的结果,其中Coverage代表从原始抽样数据中减少的百分比。可以看出,上面的Coreset采样比下面的随机采样更有效率。
下图还显示了每种维度压缩方法在异常检测任务中的还原率(横轴)和准确性(纵轴)之间的关系。
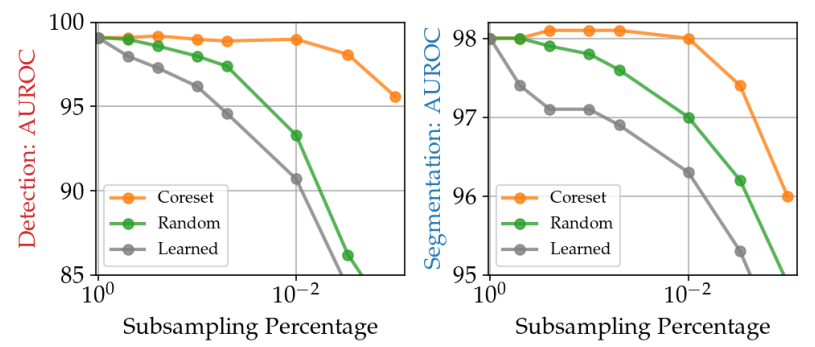
上图显示,在随机的情况下,当减少率达到约10-2时,准确率明显下降,而在Coreset(抽样)的情况下,准确率并没有下降那么多。因此,可以说Coreset Sampling是一种有效的抽样方法,可以减少数据的数量,同时保留异常检测所需的特征。
最后,到目前为止描述的存储库的整个算法显示如下:

2.4 用PatchCore进行异常检测。
第三种是用PatchCore进行异常检测,它使用获得的记忆库来计算要判别的图像(测试数据)的异常程度。最初,和训练时一样,测试数据图像通过训练好的CNN模型来获得每个补丁的特征向量。根据以下公式,异常情况是由每块测试数据的特征向量(mtest)和存储在记忆库中的特征向量(m)计算出来的。
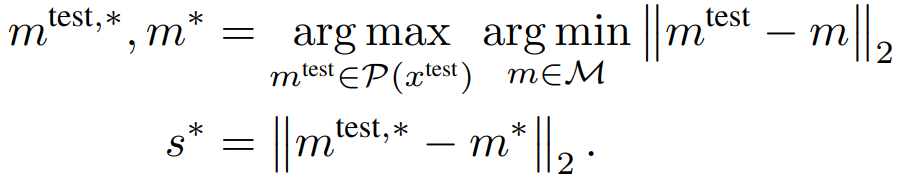
3.实验
3.1 实验装置
本文在三个不同的数据集上测试了所提方法的有效性。
第一个是MVTec数据集。它被广泛用作基准,有15个类别,包括瓶子、电缆和电网。这个数据集是本研究的主要重点。
第二个是磁砖缺陷(MTD)数据集。其任务是检测瓷片图像中的裂纹和划痕。
第三个是迷你上海科技园区(mSTC)数据集[4],它由12个不同场景的行人视频组成,任务是检测异常行为,如打架或骑自行车。
3.2 估值指数
接收者操作曲线下的面积(AUROC)被用来作为区分正常和异常图像的性能指标。按像素计算的AUROC(pixelwise AUROC)和PRO被用作检测适当异常的性能指标,其中PRO对异常的大小不太敏感。
3.3 结果
我们从MVTec数据集的结果开始。
下表显示了在AUROC中与传统方法的比较结果。

此外,下表显示了按像素计算的AUROC的结果。

对于PatchCore,分别以25%、10%和1%来改变存储库的子采样,结果显示PatchCore对于AUROC和像素AUROC都更准确。还可以看出,当存储库中的子采样百分比降低时,准确度并没有下降很多。
mSTC和MTD的结果显示在下表中。这些数据集的结果也超过了传统方法的准确性。

3.4 推理时间
下表显示了每种方法在MVTec数据集上的准确性(AUROC、像素AUROC和PRO)和推理时间。

从PatchCore的结果,可以看出,推理时间因Coreset Sampling的百分比不同而有很大差异。特别是在1%的情况下,推理时间与100%的推理时间相差不大,这表明在保持比传统方法更高的精度的同时实现了快速推理。

















 739
739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











