






 论文介绍了在大规模工业制造中检测缺陷部件的PatchCore方法,通过局部补丁特征聚合和核心集减小策略,结合预训练模型进行异常检测。后续还探讨了SA-PatchCore和FR-PatchCore的改进以及未来的研究方向,包括特征增强和CNN/Transformer融合等。
论文介绍了在大规模工业制造中检测缺陷部件的PatchCore方法,通过局部补丁特征聚合和核心集减小策略,结合预训练模型进行异常检测。后续还探讨了SA-PatchCore和FR-PatchCore的改进以及未来的研究方向,包括特征增强和CNN/Transformer融合等。
异常检测学习
文章目录
摘要
这篇论文主要关注大规模工业制造中的关键组件——检测缺陷部件。主要解决了检测中冷启动问题,即仅使用正常(无缺陷)的示例图像来拟合模型。虽然每个类别都可以有手工制作的解决方案,但目标是构建能够同时在许多不同任务上自动工作的系统。最佳的方法是将ImageNet模型的嵌入与异常检测模型相结合。本文在此基础上进行了扩展,提出了PatchCore,它使用了一个最大代表性的记忆库来存储正常的补丁特征。
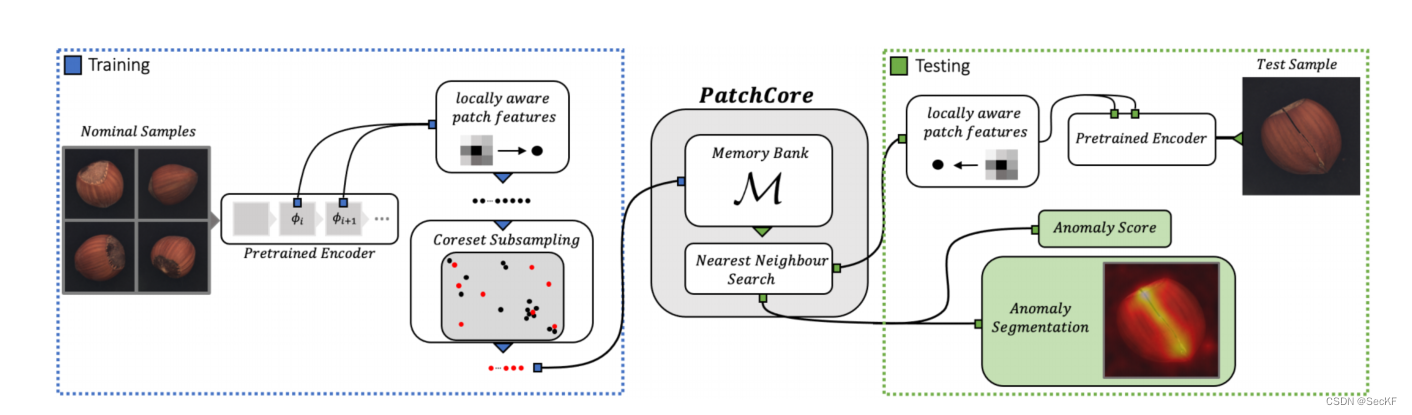
总体流程
Patchcore总体可以分为三个部分:
- 将局部补丁特征(local patch features )聚合到内存库中。
- 使用核心集缩减方法(coreset-reduction method)以提高效率
- 形成检测和定位决策的完整算法。
part 1 Locally aware patch features 局部补丁特征聚合
该方法的主要思想是利用预训练的网络提取图像特征,使用一个记忆库M存储这些特征。
这种方法继承与SPADE与Padim,使用ImageNet上预训练的特征提取网络。如ResNet-50 / WideResNet-50
使用其中间层作为输入,原因是:
保留更多的信息
可以使在ImageNet上预训练的网络提取出来的特征不那么偏向原数据集
提取得到的特征,进行局部领域聚合操作,这是为了增加感受野的大小并且增加对小的空间变化鲁棒性,以下几个公式就是其操作步骤:

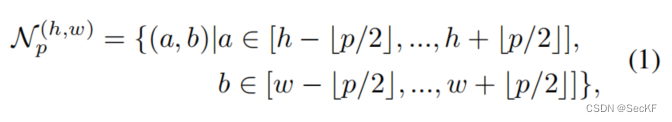
(1)表示一块大小p×p的邻域
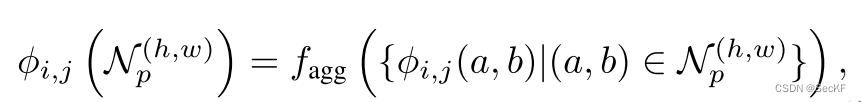 (2)
(2)
(2)表示第i张图输入到backbone后输入的第j层特征,这个特征及其在N_p上的领域进行了f_agg(某种聚集函数)操作,Patchcore中使用的是自适应平均池(adaptive average pooling)。
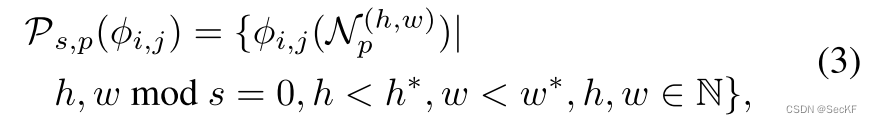
(3)表示局部特征集合
同时,还是用了第j+1层特征,使用双线性缩放使两个特征相匹配
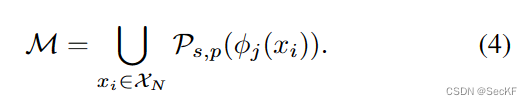
(4)表示遍历所有数据集,形成记忆库M
part 2 Coreset-reduced patch-feature memory bank 核心集减小M大小
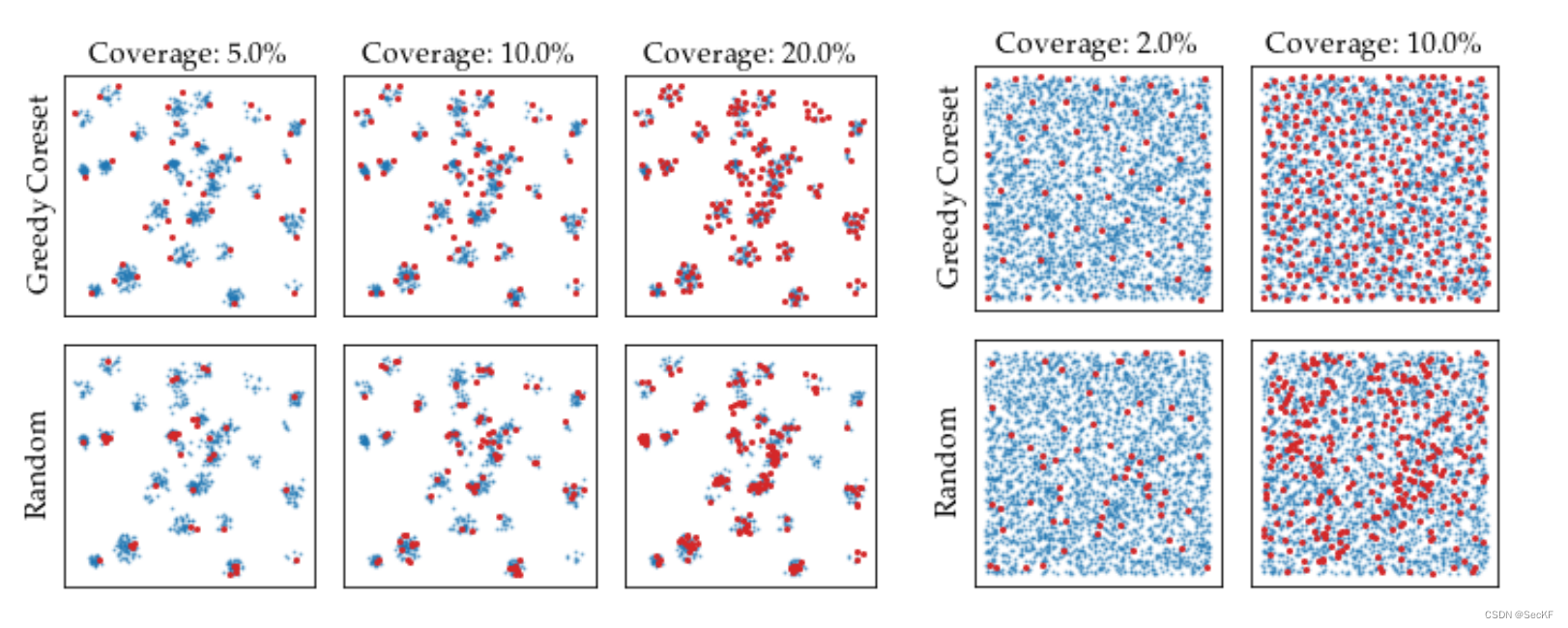
形成得到的记忆库M很大,希望一个寻找一个子集代替。之前的方法使用随机搜索的方法,patchcore提出贪婪核心集算法,上图表示两种方法效果,可见GC算法表示的更加均匀,效果更好。
算法流程图

其中最重要的是:
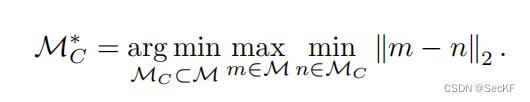
选择一个M_c,使得原始集中的任何实例与 M_c 中最近的实例的最大距离最小化
part 3 Anomaly Detection with PatchCore 计算得分
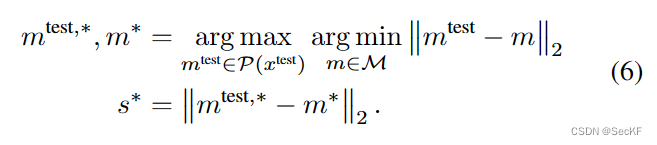
每个点先找最近的邻近区域,然后在这邻近区域中找最远的点的距离作为异常分数。
获取到全局得分并且之后,为了匹配原始输入分辨率,采用了双线性插值来放大结果。还使用了高斯滤波对结果进行了平滑处理。
算法改进
1 SA-PatchCore:
Anomaly Detection in Dataset With Co-Occurrence Relationships Using Self-Attention
引入只注意力机制,解决共现相关的异常的问题,自创数据集,如下

2 FR-PatchCore:
An Industrial Anomaly Detection Method for Improving Generalization
FR-PatchCore方法首先构建一个特征矩阵,然后将其提取到内存库中,并使用最优负余弦相似性损失进行持续更新。
同时其中的后处理方法(还没明白)值得学习。
之后的一些思路与方向
- 针对特征的增强,类似于图像增强技术,只不过其作用在特征提取之后特征上的,理论上其比针对图像的增强更具普遍性,相同的增强可能可以在不同的领域中应用,方法有一些。
- 提取特征时,利用的是j和j+1,j+1层特征还要上采样在于j层融合,可以考虑不同网络提取再做融合。
- 对cnn的特征提取器的转换,transformer的框架以及抗锯齿技术(anti-aliasing)。

















 2087
2087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









