






摘要:
本文在 PyTorch 框架下搭建了 AlexNet ,并在 CIFAR10 上完成了图片分类。同时,更正了一些原论文中的小错误(如:输入图像尺寸)。由于 CIFAR10 没有验证集,本文将训练集的 10% 当作验证集。
完整代码已上传至 GitHub:https://github.com/TiezhuXing01/AlexNet_in_PyTorch
1. 引入库
import torch
import torch.nn as nn
import numpy as np
from torchvision import datasets
from torchvision import transforms
from torch.utils.data.sampler import SubsetRandomSampler
SubsetRandomSampler 是 PyTorch 中的一个采样器(sampler)。
具体可以看这篇文章:SubsetRandomSampler 是什么?
2. 选择设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
通常情况下,我们都会选择在GPU上训练网络模型,因为神经网络的训练需要大量的计算,而英伟达的GPU提供了CUDA(一个加速计算库)。但如果你的电脑显卡是AMD的,那么有很大概率不支持使用CUDA,此时只能用CPU训练。但在CPU上训练模型是十分缓慢的。如果你暂时没法换电脑,那我建议你去租一个服务器。或者使用阿里云、百度飞桨、谷歌Colab等平台。
3. 加载数据集
CIFAR-10 是一个经典的计算机视觉数据集,用于图像分类任务。它包含了来自 10 个不同类别的 60,000 张彩色图像,每个类别有 6,000 张图像。数据集被分为训练集和测试集,其中训练集包含 50,000 张图像,测试集包含 10,000 张图像。本文拿出训练集的 10% 作为验证集。
3.1 定义获取训练集和验证集的数据加载器
def get_train_val_loader(data_dir, batch_size, augment,
random_seed, valid_size = 0.1, shuffle = True):
# ------------- 设置图像变换 ------------- #
# (1) 归一化
normalize = transforms.Normalize(mean = [0.4914, 0.4822, 0.4465],
std = [0.2023, 0.1994, 0.2010])
# (2) 验证集图像变换
val_transform = transforms.Compose([transforms.Resize(227),
transforms.ToTensor(),
normalize])
# (3) 训练集是否数据增强
if augment:
train_transform = transforms.Compose([transforms.RandomHorizontalFlip(),
transforms.Resize(227),
transforms.ToTensor(),
normalize])
else:
train_transform = transforms.Compose([transforms.Resize(227),
transforms.ToTensor(),
normalize])
# ---------- 👆 数据变换设置完毕 -------------- #
# 下载并加载训练集
train_dataset = datasets.CIFAR10(root = data_dir,
train = True,
download = True,
transform = train_transform)
val_dataset = datasets.CIFAR10(root = data_dir,
train = True,
download = True,
transform = val_transform)
# ---------- 划分验证集和训练集 ---------- #
# (1) 计算训练集图片数量
num_train = len(train_dataset)
# (2) 计算验证集数量,并向下取整
num_val = np.floor(valid_size * num_train)
# (3) 设置训练集和验证集的划分界限
split = int(num_val)
# (4) 生成一个列表索引,其内容为 0 ~ (num_train - 1) 的全部整数
indices = list(range(num_train)) # 为数据"洗牌"做准备
if shuffle:
np.random.seed(random_seed) # 根据种子生成随机数
np.random.shuffle(indices) # 根据随机数打乱图片
# (5) 划分验证集和训练集(根据索引列表 indices 和划分界限 split 划分)
val_idx = indices[:split] # 验证集索引列别
train_idx = indices[split:] # 训练集索引列表
# (6) 根据验证集和训练集的索引列表采样数据
train_sampler = SubsetRandomSampler(train_idx)
val_sampler = SubsetRandomSampler(val_idx)
# ---------- 👆 训练集和验证集划分完毕 ---------- #
# 设置数据加载器
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size = batch_size,
sampler = train_sampler)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size = batch_size,
sampler = val_sampler)
return (train_loader, val_loader)
3.2 定义获取测试集的数据加载器
def get_test_loader(data_dir, batch_size, shuffle = True):
# ------------- 设置图像变换 ------------- #
# 归一化
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225],)
# 图像变换
test_transform = transforms.Compose([transforms.Resize(227),
transforms.ToTensor(),
normalize])
# 下载并加载测试集
test_dataset = datasets.CIFAR10(root = data_dir,
train = False,
download = True,
transform = test_transform)
# 加载测试数据
test_loader = torch.utils.data.DataLoader(test_dataset,
batch_size = batch_size,
shuffle = shuffle)
return test_loader
3.3 调用函数,加载数据
# 设置数据集下载路径
data_dir = "./data"
# 设置批尺寸
batch_size = 64
# 调用训练集和验证集的 DataLoader
train_loader, val_loader = get_train_val_loader(data_dir = data_dir,
batch_size = batch_size,
augment = True,
random_seed = 1)
# 调用测试集的 DataLoader
test_loader = get_test_loader(data_dir = data_dir,
batch_size = batch_size,
shuffle = False)
4. 认识网络
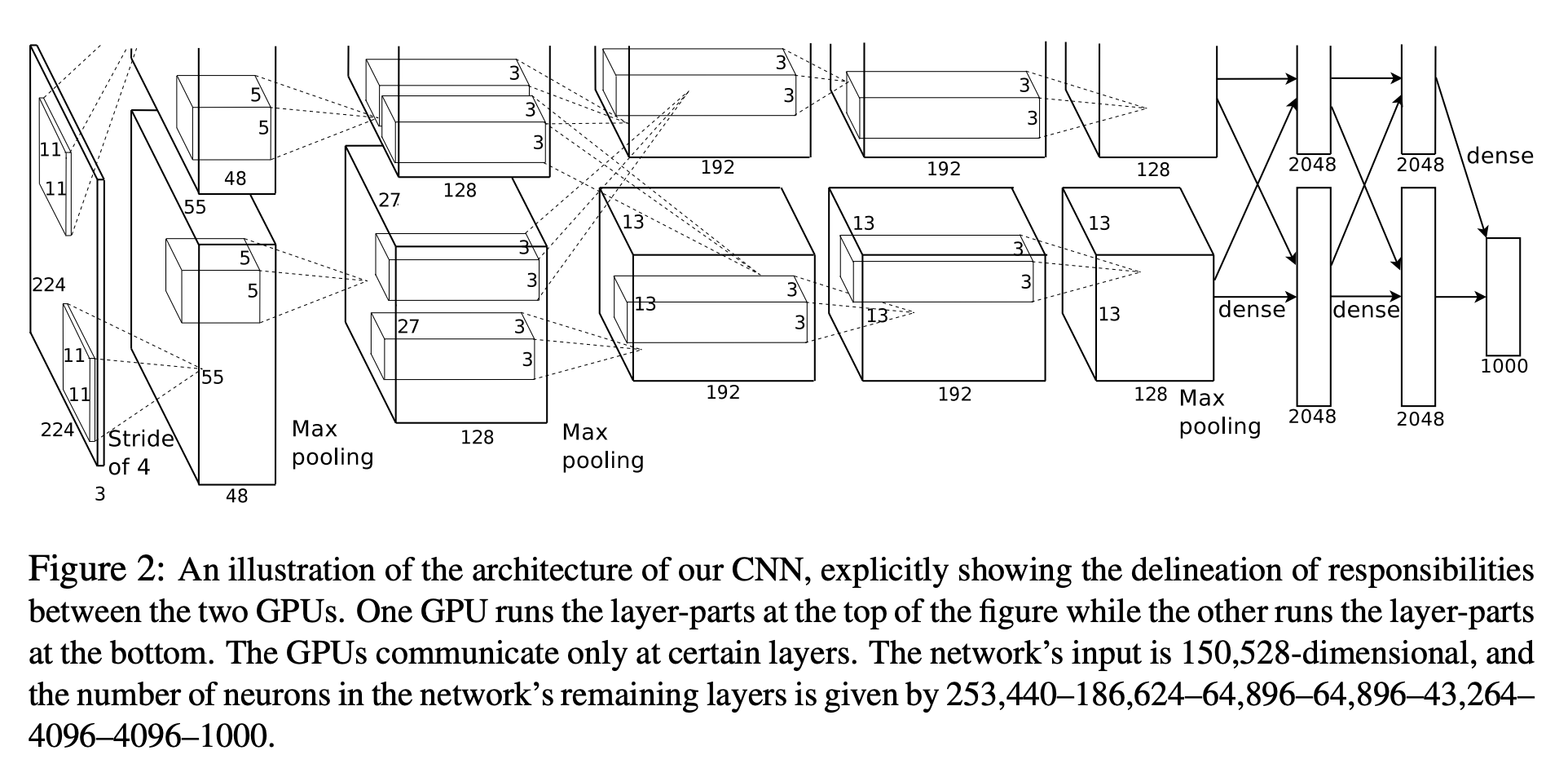
AlexNet 是卷积神经网络的奠基之作,发表时间较早,所以今天看来有一些错误或者局限性:
(1) 在2012年 AlexNet 被提出时,GPU 的算力相对今天来说非常小。为了训练这个网络,他们把 AlexNet 从中间切开,使用多 GPU 训练,分别在 2 块 GTX 580 3G 上花了五、六天时间。
(2) 这种切割只是一种技术细节,以后几年的模型大多都不会这么切割,多 GPU 训练也不是通过切割模型来实现。所以本文的代码并没有切割网络,也没有用到多 GPU 训练。
(3) 论文中写到,输入图片的尺寸是 $224×224×3$ ,即 3 个通道的 $224×224$ 图片。但事实上,这是作者的小错误。正确尺寸应为 $227×227×3$.
如果按照论文说的输入尺寸做,会出现错误。可以来算一下, 卷积输出尺寸公式为: $$ \text{output size} = \frac{\text{input size} - \text{kernel size} + 2 \times \text{padding}}{\text{stride}} + 1 $$ 第一次卷积后:$\text{output size} = \frac{224 - 11 + 2 \times 0}{4} + 1=54.25$ 出现小数了。在一块 GPU 上训练的正确 AlexNet 结构及其输入输出尺寸应为下表。
| 操作 名称 | 输入 通道 | 输出 通道 | 核尺寸 | 步幅 | 填充 | 输出尺寸 输入: 227×227×3 |
| conv1 | 3 | 96 | 11×11 | 4 | 0 | 55×55×96 |
| pool | 3 × 3 | 2 | 27×27×96 | |||
| conv2 | 96 | 256 | 5 × 5 | 1 | 2 | 27×27×256 |
| pool | 3 × 3 | 2 | 13×13×256 | |||
| conv3 | 256 | 384 | 3 × 3 | 1 | 1 | 13×13×384 |
| conv4 | 384 | 384 | 3 × 3 | 1 | 1 | 13×13×384 |
| conv5 | 384 | 256 | 3 × 3 | 1 | 1 | 13×13×256 |
| pool | 3 × 3 | 2 | 6×6×256 | |||
| fc1 | 9216 | |||||
| fc2 | 4096 | |||||
| fc3 | num_classes(=10) |
5. 搭建网络
class AlexNet(nn.Module):
def __init__(self, num_classes=10):
super(AlexNet, self).__init__()
self.conv_block1 = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=0),
nn.BatchNorm2d(96),
nn.ReLU()
)
self.conv_block2 = nn.Sequential(
nn.Conv2d(96, 256, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(256),
nn.ReLU()
)
self.conv_block3 = nn.Sequential(
nn.Conv2d(256, 384, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(384),
nn.ReLU()
)
self.conv_block4 = nn.Sequential(
nn.Conv2d(384, 384, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(384),
nn.ReLU()
)
self.conv_block5 = nn.Sequential(
nn.Conv2d(384, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU()
)
self.pool = nn.MaxPool2d(kernel_size = 3, stride = 2)
self.fc1 = nn.Sequential(nn.Dropout(0.5),nn.Linear(9216, 4096),nn.ReLU())
self.fc2 = nn.Sequential(nn.Dropout(0.5),nn.Linear(4096, 4096),nn.ReLU())
self.fc3 = nn.Sequential(nn.Linear(4096, num_classes))
def forward(self, x):
out = self.conv_block1(x)
out = self.pool(out)
out = self.conv_block2(out)
out = self.pool(out)
out = self.conv_block3(out)
out = self.conv_block4(out)
out = self.conv_block5(out)
out = self.pool(out)
out = out.reshape(out.size(0), -1)
out = self.fc1(out)
out = self.fc2(out)
out = self.fc3(out)
return out
Dropout:让一部分神经元输出为0. 目前认为它是一个正则项,防止过拟合。由于目前很少使用全连接了,所以Dropout不是那么重要了。
6. 设置超参数
num_classes = 10
epochs = 20
learning_rate = 0.005
model = AlexNet(num_classes).to(device)
# 设置损失函数
cost = nn.CrossEntropyLoss()
# 设置优化器
optimizer = torch.optim.SGD(model.parameters(), # SGD 随机梯度下降
lr = learning_rate,
weight_decay = 0.005, # 正则化项的权重是 0.005
momentum = 0.9)
# 一个 epoch 训练的总 step 数
train_step = len(train_loader)
-
len(train_loader)返回加载器中的批次数量。 50000 × ( 1 − 0.1 ) 64 = 703.125 \frac{50000×(1-0.1)}{64}=703.125 6450000×(1−0.1)=703.125,结果出现小数,向上取整为704. -
随机梯度下降(SGD)现在是深度学习最主流的优化算法,因为其内部的噪声使模型有更好的泛化能力。
-
weight_decay:是 L2 的正则项。 -
正则化:在机器学习中,正则化是一种用于防止过拟合的技术。限制模型的复杂性,防止模型对训练数据中的噪声过于敏感,从而提高其在未知数据上的泛化能力。在 AlexNet 提出那年(2012),人们普遍认为正则化对解决模型过拟合问题是很重要的。但在后期,这个观点被推翻了。取而代之的是,网络的设计对防止过拟合更重要的。
-
momentum:动量是一种优化算法中常用的技术,通常与随机梯度下降(SGD)结合使用,用于加速模型的训练过程。它的功能是**避免因下降曲线不平滑而落入局部最优解中。**动量的引入主要是为了解决随机梯度下降的一些问题,例如在梯度更新中存在的震荡和收敛速度慢的问题。动量算法引入了一个指数衰减的累积变量,用来持续跟踪梯度的历史信息。这个累积变量就是动量。动量在更新参数时不仅考虑当前梯度,还考虑了之前梯度的方向。这有助于平滑更新过程,减少参数更新的震荡,提高模型训练的稳定性和速度。
7. 训练和验证
训练需要 2 个循环的嵌套:外部循环用于循环 epoch ;内部循环用于循环每个 epoch 中的每个 batch 的图片,一个 batch 一步(step)。
for epoch in range(epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = cost(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("Epoch [{}/{}], Step [{}/{}], Loss:{:.4f}".format(
epoch+1, epochs, i+1, train_step, loss.item())) # loss是张量,需要.item()转为浮点型
# 一个epoch完成之后,进入验证
with torch.no_grad():
correct = 0
total = 0
for images, labels in val_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# del images, labels, outputs # 删除变量以释放内存
# 输出验证结果
print("Accuracy on validation: {} %".format(100 * (correct / total)))
-
注意:
enumerate(train_loader)返回的是(index, (images, labels))的元组,所以for i, images, labels in enumerate(train_loader):是错的,应该为for i, (images, labels) in enumerate(train_loader):. 相关文章:enumerate(train_loader) 返回什么? -
torch.max(outputs.data, 1)返回每一行的最大值以及这些最大值所在的索引。第一个返回值(_)是最大值,第二个返回值(predicted)是最大值的索引。在这种情况下,我们只关心索引,因为它表示了模型的预测类别。 -
labels.size(0)返回的是当前批次中标签的数量。 -
del images, labels, outputs是手动删除变量以释放内存。在Python中,这通常是不必要的,因为Python的垃圾回收器会自动处理不再使用的对象。 -
for images, labels in val_loader:不需要numerate(val_loader)是因为验证阶段不需要索引,看的是验证集整体的准确度。
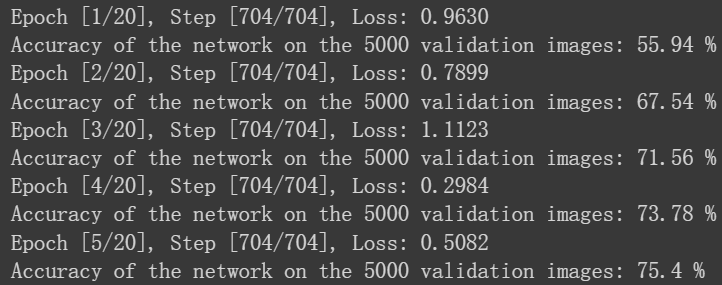
训练结果如下图:
8.测试
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# del images, labels, outputs # 删除变量以释放内存
# 输出测试结果
print("Accuracy on test: {} %".format(100 * (correct / total)))
测试结果如下图:

以上,就是 AlexNet 实现图像分类的全部内容。















 835
835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









