






一、文章背景
在推荐系统中,基于用户-物品图的表示学习已经从使用单一的ID或交互历史发展到利用高阶邻居的方法。这导致了基于图卷积网络(GCN)的推荐方法(如PinSage和LightGCN)取得了成功。尽管这些方法非常有效,但我们认为它们存在两个限制:
(1)长尾问题:高度节点对表示学习产生更大的影响,从而降低了对低度(长尾)物品的推荐效果;
(2)鲁棒性问题:由于邻居聚合方案进一步放大了观察到的边的影响,表示容易受到噪声交互的干扰。
第一个限制是指高度节点对表示学习的影响较大,这主要是因为基于GCN的方法通常通过邻居聚合来更新节点的表示。高度节点具有更多的邻居连接,因此它们的信息在聚合过程中被更频繁地传播。这导致高度节点在表示学习中占据主导地位,而低度节点(即长尾物品)的表示往往被忽视或降低了重要性。
第二个限制是指表示容易受到噪声交互的干扰。由于邻居聚合的方式,观察到的边的影响被进一步放大。然而,在真实的用户-物品图中,存在着噪声交互,例如错误的评分或无关的交互。这些噪声交互会对表示学习产生负面影响,导致表示不准确或带有冗余信息。
针对这些限制,研究人员正在努力改进基于图的表示学习方法。一些方法通过引入采样策略来缓解高度节点的影响,例如通过对邻居进行采样或限制采样的数量。另一些方法则通过设计更鲁棒的聚合方案来减轻噪声交互的影响,例如对边进行权重调整或利用注意力机制。
基于此,作者提出了图自监督学习的方法SGL(Self-supervised Graph Learning),来提高基于二分图推荐的准确性和鲁棒性。主要思想是,通过辅助的自监督任务来补充传统的监督任务,具体来说,我们对同一个节点通过数据增强(data augmentation)的方式生成多个视图,最大化同一节点不同视图之间的相似性,最小化不同结点表征之间的相似性,来加强节点表征学习的自我区分能力(self-discrimination)。用三种方法来数据增强同一节点以生成不同视图,节点丢弃(node dropout,减少特定节点的影响力,尤其是图中具有高度连接的节点),边丢弃 (edge dropout,降低高度节点的影响力), 随机游走(random walk)。
SGL方法和具体使用的图模型无关,可以和任意的图模型搭配使用。作者在LightGCN的基础上,来引入SGL图自监督学习方法。通过「对比学习范式」的理论分析,阐明了SGL能够有助于挖掘「困难负样本(hard negatives)」,不仅提高了准确性,也能够提高训练过程收敛速度。通过在三个数据集上的经验性分析,也能够阐明这个SGL的有效性,尤其是在长尾items的推荐准确性以及对于噪声交互数据的鲁棒性。
二、文章方法:
先做数据增强操作,来产生多种视图;然后通过图编码(这篇文章使用GCNs)的方式形成不同视图下的结点表征,并在这些视图表征上做对比学习。最后将对比学习辅助目标和传统的监督目标融合在一起,形成多目标学习的范式。
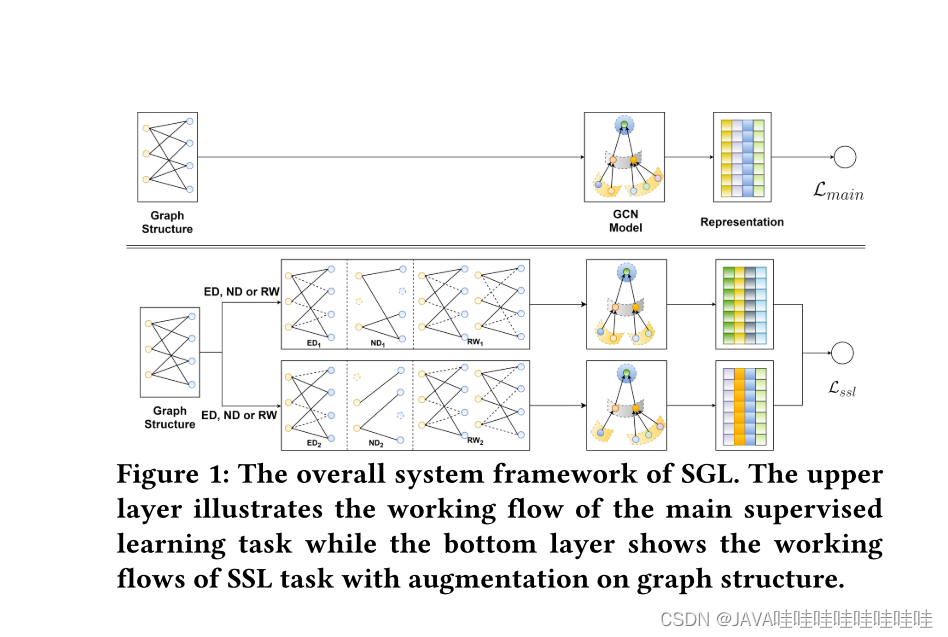
1.具体步骤:
在数据增强阶段,我们采取多种方法来生成不同的表示视图,通过对原始数据进行变换、旋转、遮挡等操作来生成多样化的输入样本。这样可以增加数据的多样性,提供更多的训练样本。
在构建预训练任务阶段,我们使用对比学习来利用生成的表示进行自监督学习。对比学习的目标是将来自同一样本的不同表示视图更加接近,而将来自不同样本的表示视图更加远离。这样可以通过比较不同视图之间的相似性来学习数据中的潜在结构和关系。
在多任务学习中,我们将自监督学习与经典的GCN相结合。GCN用于主要的监督任务,而自监督学习则作为辅助任务。通过同时训练主任务和辅助任务,可以提高模型的性能和泛化能力。
在理论分析方面,我们从梯度级别对SSL进行研究,揭示了SSL与困难负样本挖掘之间的关系。困难负样本挖掘是一种通过选择难以区分的负样本来增加训练难度的方法,从而提高模型的鲁棒性和泛化能力。
最后,我们对SGL的复杂性进行分析。复杂性分析可以帮助我们了解SGL方法的计算和存储开销,从而评估其可扩展性和适用性。
通过以上的步骤和分析,SGL方法通过自监督学习增强了经典GCN模型,提高了模型的性能和表示能力,并且具有一定的理论基础和可行性分析。
2.数据增强
GNN的节点编码:
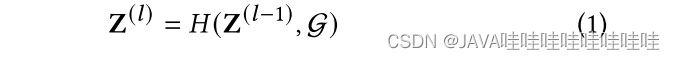
输入:上一层的节点表征、原始图。
输出:本层的节点表征向量。
在本篇在文章中:
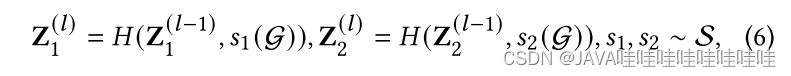
先利用数据增强产生两个不同的子视图
edge dropout: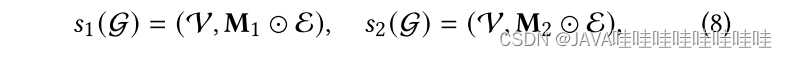
node dropout:
![]()
random walk:
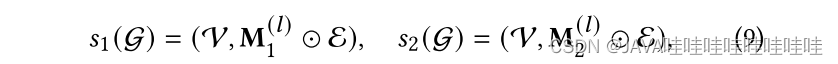
3.对比学习:
最大化同一节点不同视图表征向量之间的相似性,最小化不同节点表征向量之间的相似性。采用了类似SimCLR[5]中的InfoNCE[6]的目标: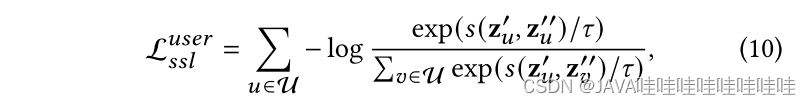
s本篇采用的是cosine相似性函数,τ是温度参数,最终子监督学习的目标函数:
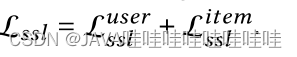
4.多任务训练
和推荐系统常用的BPR-pairwise损失函数结合起来做联合训练,最后一项正则化的只有GNN的参数,因为自监督学习没有引入任何参数:
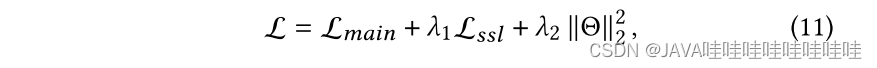
5.Theoretical Analyses of SGL
作者从「梯度贡献角度」来理论地分析了SGL方法为何会有效。作者分析了其中重要的一个原因,SGL有助于挖掘困难负样本,这部分样本能够贡献取值大且有意义的梯度,来引导结点的表征学习。
首先对单个节点u求z’u的导数:
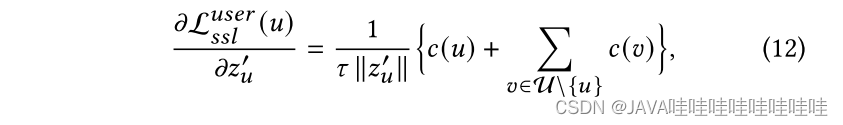
𝑐(𝑢)和𝑐(𝑣)分别表示正节点𝑢和负节点{𝑣}对梯度𝑧‘𝑢的贡献:
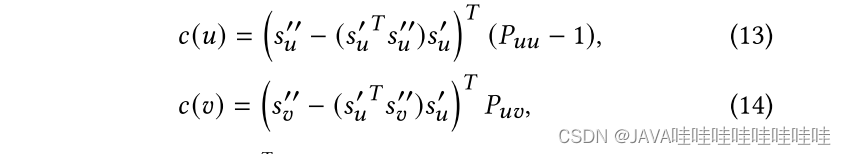
Puv是softmax概率值(用户u选择用户的概率),S‘u,S’‘u是节点u不同视图的归一化表示。重点关注负样本v对于梯度的贡献度,c(v)用L2范数来衡量梯度贡献度:
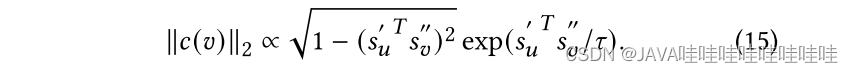
用𝑥 = 𝑠′𝑢𝑇𝑠′′𝑣 ∈ [−1, 1]来简化c(v):
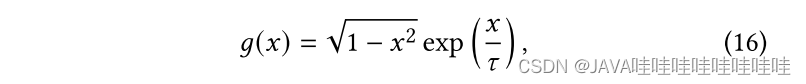
- 困难负样本, 0<x≤1 ,存在一定的相似性,模型在隐空间难以很好地将这类负样本和正样本分离开。
- 简单负样本,−1≤x<0,即:u和v不相似,很容易区分开
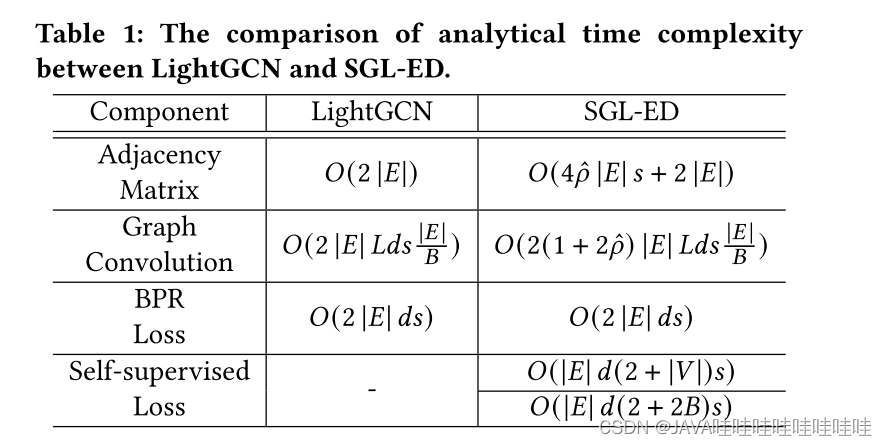
6.时间复杂度分析
相比于LightGCN,主要多的复杂度就是数据增强操作,即对邻接矩阵来做;以及自监督学习任务,这个的复杂度主要在于负样本选取,优化思路是拿同一个batch内其他的结点作为负样本,而不是整个图上所有其他结点都作为负样本。总体上,复杂度略涨,是在可以接受的范围内。
从概念上讲,我们的SGL在现有基于GCN的推荐模型中进行了补充,具体体现在以下几个方面:
1. 节点自我区分:SGL通过节点自我区分提供辅助的监督信号,这是对仅基于观察到的交互的传统监督的补充。节点自我区分可以帮助模型更好地学习节点的表示,从而提高推荐性能。
2. 增强操作:SGL使用增强操作,特别是边缺失(edge dropout),有助于减轻度数偏差,通过有意地减少高度节点的影响。这可以使模型更平衡地对待不同节点,并降低对度数高的节点的依赖性。
3. 多视图:SGL针对不同的局部结构和邻居关系为节点提供多个视图,增强了模型对于交互噪声的鲁棒性。通过考虑节点的多个视图,模型可以更全面地理解节点之间的关系,提高推荐的准确性和鲁棒性。
除此之外,我们还对对比学习范式进行了理论分析,发现它具有挖掘困难负例的副作用,这不仅提升了性能,还加快了训练过程。
总之,SGL通过节点自我区分、增强操作、多视图等方式对现有的基于GCN的推荐模型进行了补充和增强。这些改进可以提高模型的性能、鲁棒性和训练效率,并为对比学习范式提供了理论分析支持。
三、实验
1.settings
- 数据集:Yelp2018, Amazon-Book,Alibaba-iFashion
- 指标:Recall@20,NDCG@20
- 对比方法:协同过滤方法。
- 二分图协同过滤方法:NGCF[9]、LightGCN[2]
- 自编码器协同过滤方法:Mult-VAE [8]
- 神经网络+自监督学习方法:DNN+SSL[7]
2.比较研究
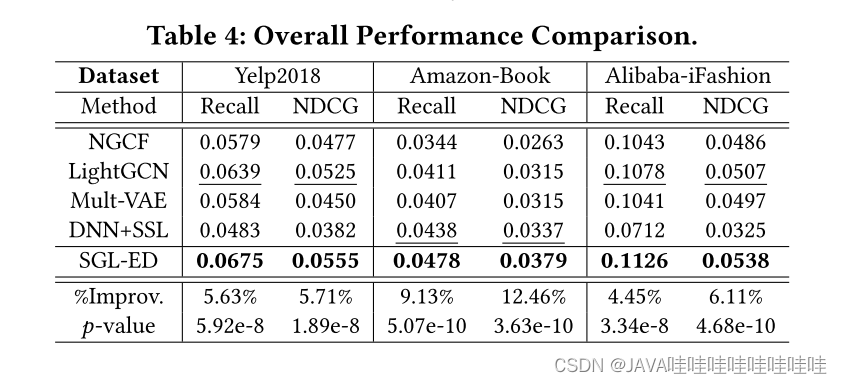
SGL-ED比LightGCN的效果好。
3.消融研究
- 对比3种不同的数据增强操作。发现SGL-ED总体上效果最好,其次是SGL-RW,最后是SGL-ND。作者认为edge dropout方式能更好地发现图结构中潜在的模式。
- SGL和LightGCN单独对比,SGL基本都是赢的。
- 层数从1到3层变化,效果慢慢变好,说明SGL对于泛化性有一定的帮助,即「不同结点之间的对比学习」能够有效缓解随着层数的增加导致的「过度平滑」问题。
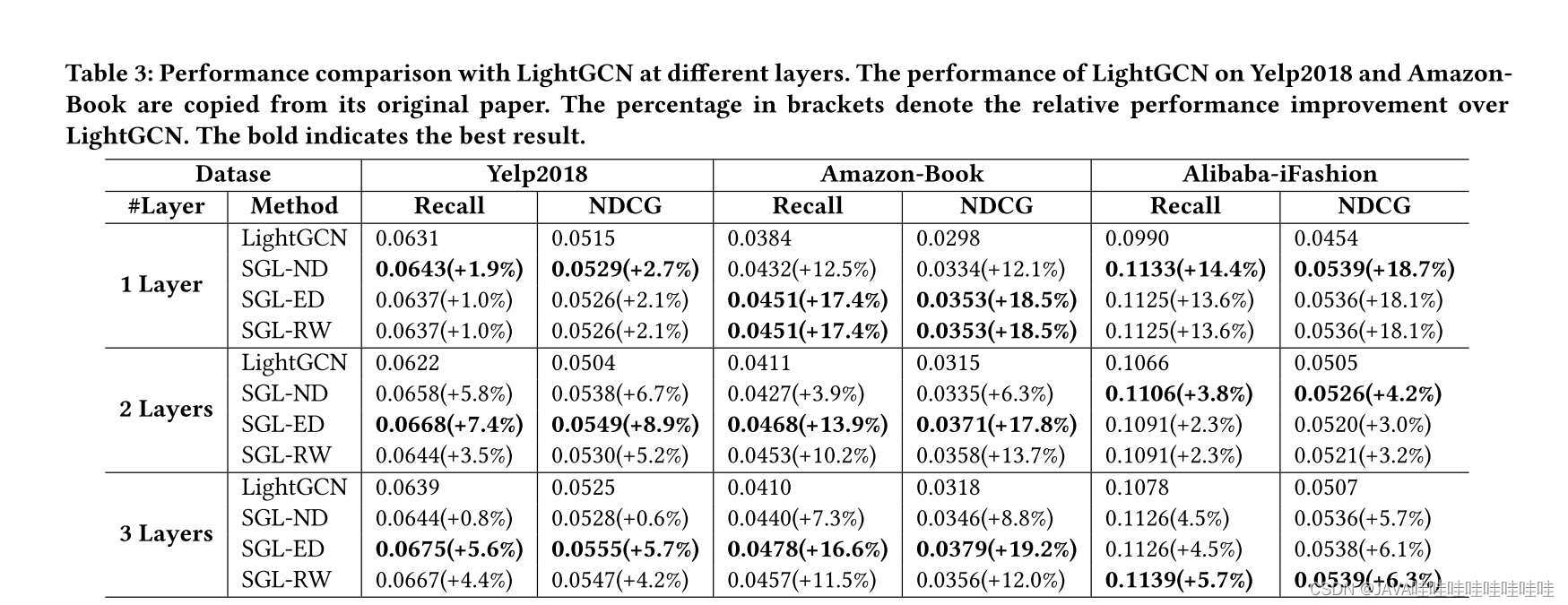
4.长尾推荐
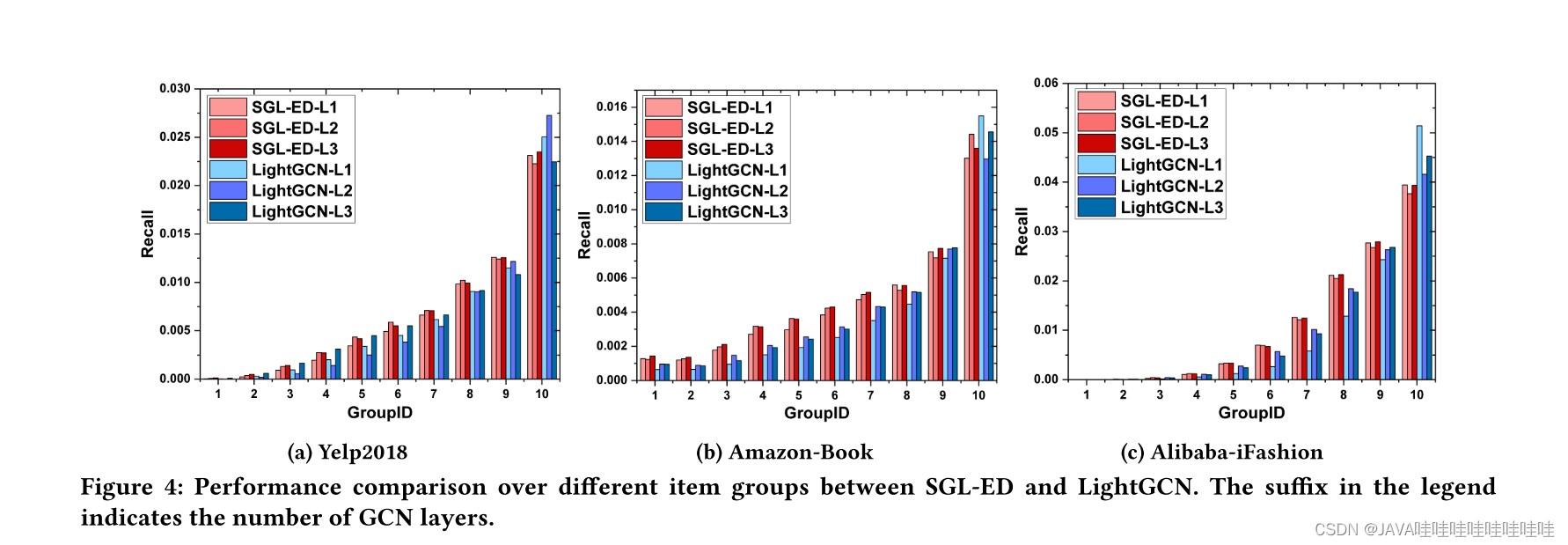
SGL在低度的组别上(分组ID越小,度数越小),指标比LightGCN高,在高度的组别上,不相上下,LightGCN有的略好一些。这从经验上说明了SGL对于长尾物品推荐的有效性。
5.噪声交互的鲁棒性
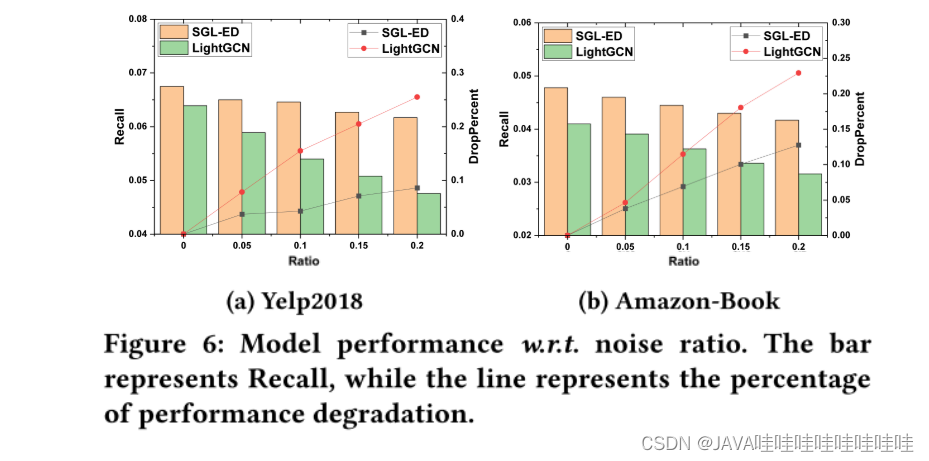
在训练集中加入对抗样本,即一定比例的user-item未交互的样本,然后看SGL和LightGCN在测试集上的表现。通过对比学习同一结点的不同视图表征,模型能够有效地发现最有意义的模式,尤其是结点的图结构,使得模型不会过于依赖某些边。总而言之,SGL提供了一种能够去掉噪声交互信息的方法。
6.其他分析
- 温度参数τ:不宜过大过小,τ=0.2时达到最佳

- 预训练的有效性
先自监督地预训练结点向量去获得模型参数,然后用于初始化结点向量,再通过推荐监督任务来微调模型。最终的效果是,SGL-ED>SGL-pre >LightGCN。说明预训练方式也是有效的。
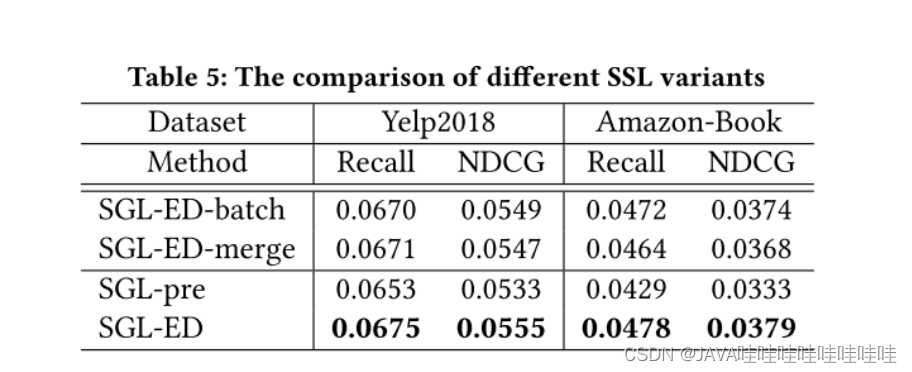
- 负节点的影响
在batch内采样同类型结点作为负样本,比如user采用user结点作为负样本。SGL-ED-batch
batch内采样任意结点,不区分结点类型。SGL-ED-merge。
在全域内采样同类型的负样本。SGL-ED。
SGL-ED > SGL-ED-batch > SGL-ED-merge。SGL-ED-batch和SGL-ED差距不是非常大,说明batch内采样是个很好地优化方法。
三、主要贡献
1.设计了一种新的学习范式SGL,它以节点自区分为自监督任务,为表征学习提供辅助信号。
2.SGL除了减轻度量偏差和增加对交互噪声的鲁棒性之外,还在理论上证明了其从困难负例中学习的特性。通过调整softmax损失函数中的温度超参数,可以控制对困难负例的关注程度。(从困难负例中学习是指在分类或区分样本时更加关注那些难以判断或与其他样本相区分的示例。)
3.对三个基准数据集进行了大量实验,以验证SGL的优越性
四、总结
通过「数据增强」来改变图结构,使得图模型于不会过于依赖某些「边」或者某些「高度结点」。
通过「对比学习」同一结点的不同视图表征,模型能够有效地发现「最有意义的模式」,尤其是结点的图结构信息,同时还能挖掘困难负样本,提高模型的区分能力。
五、一些
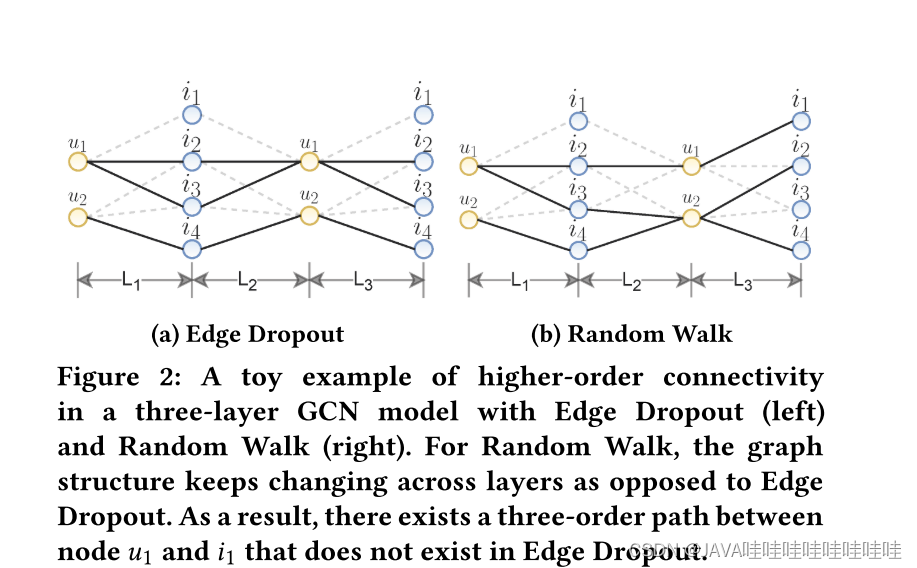
Figure 2展示了一个玩具示例,展示了带有边丢弃(Edge Dropout)和随机游走(Random Walk)的三层GCN模型中的高阶连接性。在Random Walk中,图结构在不同层之间会发生变化,而在边丢弃中保持不变。因此,在节点𝑢1和𝑖1之间存在一个三阶路径,在边丢弃中不存在。
具体来说,在左侧的Edge Dropout示例中,图的结构在每一层保持不变。这意味着在不同层之间,节点之间的连接关系保持不变。这种情况下,可能存在一些边被丢弃的情况,但是整体的图结构保持不变。
而在右侧的Random Walk示例中,图的结构在每一层都会发生变化。在每一层中,通过随机游走的方式,从每个节点出发,按照一定的概率选择相邻节点进行连接。这种随机游走的方式会导致图结构在不同层之间发生变化,从而形成了不同的高阶连接关系。
因此,对于节点𝑢1和𝑖1之间的连接关系,由于Random Walk会随机游走并选择相邻节点,可能会形成一个三阶路径。而在Edge Dropout中,由于图结构保持不变,可能不存在这样的三阶路径。
这个玩具示例展示了在不同的图神经网络模型中,图的结构如何影响高阶连接性的形成。不同的图结构变化方式可能会导致不同的高阶连接关系的存在或缺失。
「SGL的收敛速度快」,这主要得益于困难负样本。值得一提的是,作者提到了一个点,SGL的BPR损失下降和Recall指标的上升存在时间上的小gap,说明了BPR损失在排序任务中不一定是最优的

















 1536
1536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









