







目录
1 概率论知识
1.1 先验概率
先验概率是基于背景常识或者历史数据的统计得出的预判概率,一般只包含一个变量,例如P(A),P(B)。
1.2 联合概率
联合概率指的是事件同时发生的概率,例如现在A,B两个事件同时发生的概率,记为P(A,B)、P(A∩B)、P(AB)。
若事件A和事件B相互独立,则有:
例子:假设事件A为明天上班,事件B为明天中彩票,其中P(A)=0.5,P(B)=0.5,则明天既上班又中彩票的概率为P(A)P(B)=0.25
1.3 条件概率
其中一般条件概率中的A事件表示结果,B事件表示原因,即由因求果

其中,P (AB) 就是联合概率。在A与B相互独立的情况下,易得:
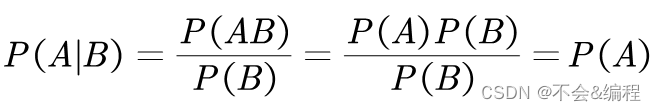
即B事件对A事件没有影响
1.4 后验概率
后验概率和条件概率的区别是:后验概率是由果求因:,例如,事件A是由事件B引起的,则P(A|B)是条件概率,P(B|A)是后验概率
举个通俗易懂的例子:
- 条件概率:新闻说今天路上出现了交通事故,若想推算一下因此而堵车的概率,也就是 P(堵车|交通事故),这是由因推果。
- 后验概率:出门后路上遇到了堵车,若想推算一下这次堵车是由发生了交通事故而引起的概率,也就是后验概率 P(交通事故|堵车),这是由果求因。
1.5 全概率公式
(1)样本空间

(2)全概率公式

1.6 贝叶斯公式
设样本空间为Ω,B为Ω中的事件,为Ω的一个划分,且
,则有:
称上式为贝叶斯公式,也称为逆概率公式

2 贝叶斯分类器理论知识
2.1 朴素贝叶斯发的学习与分类
2.1.1 基本方法
设
- 输入空间:
为n维集合的向量
- 输出空间:类标记集合
- 输入为特征向量:
- 输出为类标记(class label):
X是定义在输入空间上的随机向量,Y是定义在输出空间
上的随机变量。
是X和Y的联合概率分布。训练数据集
是独立同分布产生
朴素贝叶斯法通过训练数据集学习联合概率分布,学习过程如下:
(1)学习先验概率分布及条件概率分布
- 先验概率分布:
- 条件概率分布:
假设可取值有
个,
,Y的可能取值有K个,那么参数的个数有
,因此条件概率分布
有指数级别数量的参数,其估计实际是不可行的
朴素贝叶斯法对条件概率分布作了条件独立性的假设。由于这是一个较强的假设,朴素贝叶斯法也由此得名。朴素贝叶斯法的条件独立性假设为:
朴素贝叶斯法实际上学习到生成数据的机制,所以属于生成模型。条件独立假设等于是说用于分类的特征在类确定的条件下都是条件独立的。这一假设使朴素贝叶斯法变得简单,但有时会牺牲一定的分类准确率。
朴素贝叶斯分类时,对给定的输入x,通过学习到的模型计算后验概率分布,将后验概率最大的类作为x的类输出,后验概率计算根据贝叶斯定理进行:
将公式(1)代入到公式(2)可得:
于是, 朴素贝叶斯分类器可表示为:
由于分母是一样的,所以可以简化为:
2.1.2 后验概率最大化含义
朴素贝叶斯会将实例分到后验概率最大的类中,即等价于期望风险最小化,假设选择0-1损失函数:
其中是分类决策函数。这时,期望风险函数为
期望是对联合分布取的。所以取条件期望
为了使期望风险最小化,只需对逐个最小化,因此有
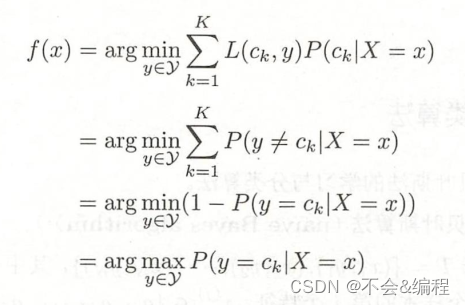
最终可知后验概率最大的类=期望风险最小的类,即朴素贝叶斯采用的原理:
2.2 朴素贝叶斯法的参数估计
2.2.1 极大似然估计

2.2.2 学习与分类算法
1 算法流程

2 例子


2.2.3 贝叶斯估计
1 理论

2 例子
取λ=1,之后如下所示:

















 547
547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









