







目录
仅为个人结合一些博客的理解。
1、混淆矩阵
如果是k+1分类问题,就会生成(k+1)*(k+1)的混淆矩阵(具体定义可参见百度百科)。下面以肺结节分割为例,显然这是一个二分类的问题,肺结节=1,背景=0.
pred: 预测值
gt: 真实值
| pred = 肺结节 | pred = 背景 | |
| gt = 肺结节 | TP | FN |
| gt = 背景 | FP | TN |
TP(真阳性):样本预测为正例,真实为正例,预测正确
FN(假阴性):样本预测为负例,真实为正例,预测错误
FP(假阳性):样本预测为正例,真实为负例,预测错误
TN(真阴性):样本预测为负例,真实为负例,预测正确
橙色表示整个样本
蓝色表示样本中真实为正例(eg. 肺结节)的部分
红色表示样本中预测为正例的部分
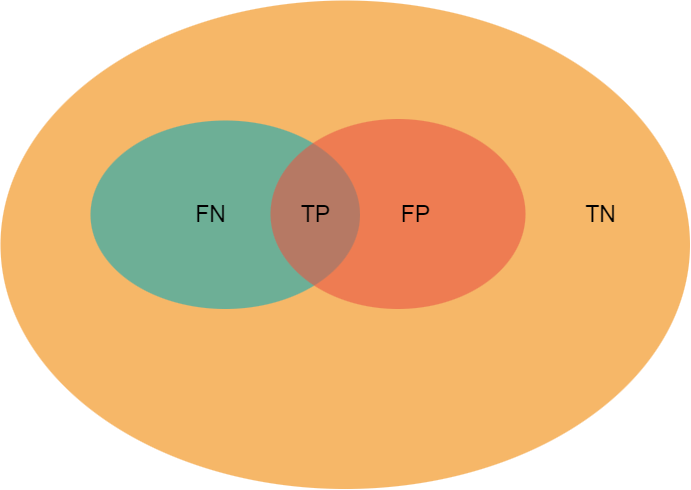
混淆矩阵的计算:
2、Dice

我们把X当作Gt,Y当作Pred,dice系数就可以评价结果了。
参考上面的韦恩图:
X = FN + TP
Y = TP + FP
所以,上面公式可以转换为:
3、均交并比MIoU(Mean Intersection over Union)
(带有M表示平均)
计算两个集合交集与其并集的重合比例。
这里我们计算Gt和Pred之前的交并比。
4、MPA
(带有M表示平均)
计算正确分类的像素与所有像素数量的比值。
5、SEN

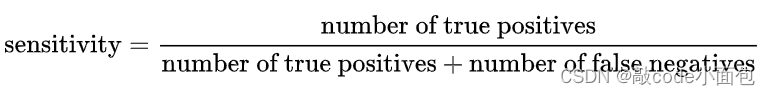
6、PPV(Positive Predict Value)
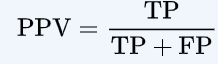
参考博客:

















 2619
2619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









