









Dice系数(Dice Coefficient),也称为Dice相似系数(Dice Similarity Coefficient, DSC),是衡量两个集合相似度的指标,广泛应用于图像分割任务(尤其是医学影像)中评估预测结果与真实标签的重叠程度。以下是其核心定义、应用场景及计算方法的详细解析:
一、Dice系数的定义
1. 公式
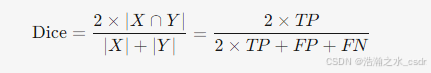
- X:预测分割区域(二值掩码)。
- Y:真实分割区域(Ground Truth)。
- TP(真正例):预测为正且真实为正的像素数。
- FP(假正例):预测为正但真实为负的像素数。
- FN(假反例):预测为负但真实为正的像素数。
2. 取值范围
- 1.0:预测与真实完全重合(完美分割)。
- 0.0:预测与真实无任何重叠。
二、Dice系数 vs IoU(交并比)
1. 关系
- 数学关系:Dice系数与IoU可相互转换:
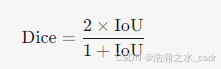
- 数值对比:Dice系数始终大于等于IoU(例如,IoU=0.5时,Dice≈0.67)。
2. 优缺点对比
| 指标 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Dice系数 | 对重叠区域敏感,适合小目标或类别不平衡 | 对FP和FN的惩罚对称,可能忽略边界细节 | 医学影像分割(如肿瘤区域) |
| IoU | 直接反映重叠比例,解释性强 | 对小目标或低重叠区域敏感度较低 | 通用分割任务 |
三、Dice系数的应用场景
1. 医学影像分割
- 肿瘤分割:评估肿瘤区域预测的准确性(如BraTS数据集中Dice≥0.85为优秀)。
- 器官分割:如心脏、肝脏的3D分割(要求Dice>0.90)。
2. 小目标检测
- 细胞检测:少量像素的细胞区域需高Dice系数(如Dice>0.7)。
- 遥感图像:建筑物、道路的精细分割。
3. 类别不平衡任务
- 前景-背景分割:前景像素占比极低时(如病灶占1%),Dice比IoU更稳定。
四、Dice系数的计算示例
示例数据:
- 真实标签(Y):1,1,0,0,1(1表示正类,0表示负类)。
- 预测结果(X):1,0,1,0,1。
计算步骤:
-
统计混淆矩阵:
- TP=2(位置1和5正确预测为正)。
- FP=1(位置3错误预测为正)。
- FN=1(位置2真实为正但预测为负)。
-
计算Dice系数:
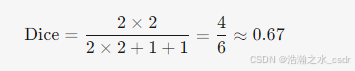
五、代码实现(Python)
1. 基础计算
import numpy as np
def dice_coefficient(y_true, y_pred, smooth=1e-6):
"""
计算Dice系数
:param y_true: 真实标签(二值化,形状[H, W]或[H, W, C])
:param y_pred: 预测结果(二值化,形状同y_true)
:param smooth: 平滑项,避免除以0
:return: Dice系数(标量)
"""
intersection = np.sum(y_true * y_pred)
union = np.sum(y_true) + np.sum(y_pred)
dice = (2. * intersection + smooth) / (union + smooth)
return dice
# 示例
y_true = np.array([1, 1, 0, 0, 1])
y_pred = np.array([1, 0, 1, 0, 1])
print(f"Dice系数: {dice_coefficient(y_true, y_pred):.2f}") # 输出: 0.672. 多类别分割(按类计算)
def multi_class_dice(y_true, y_pred, num_classes, smooth=1e-6):
dice_scores = []
for c in range(num_classes):
true_c = (y_true == c)
pred_c = (y_pred == c)
intersection = np.sum(true_c & pred_c)
union = np.sum(true_c) + np.sum(pred_c)
dice = (2. * intersection + smooth) / (union + smooth)
dice_scores.append(dice)
return np.mean(dice_scores)
# 示例:3个类别(0:背景,1:类A,2:类B)
y_true = np.array([0, 1, 2, 1, 0])
y_pred = np.array([0, 1, 1, 1, 0])
print(f"平均Dice系数: {multi_class_dice(y_true, y_pred, num_classes=3):.2f}")六、Dice损失函数(Dice Loss)
在训练分割模型时,Dice系数常被转化为损失函数以直接优化重叠区域:
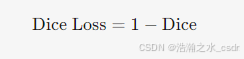
PyTorch实现:
import torch
class DiceLoss(torch.nn.Module):
def __init__(self, smooth=1e-6):
super(DiceLoss, self).__init__()
self.smooth = smooth
def forward(self, y_pred, y_true):
# 输入形状:[B, C, H, W],需转换为二值掩码
y_pred = y_pred.sigmoid() # 若未归一化,需sigmoid或softmax
intersection = torch.sum(y_pred * y_true)
union = torch.sum(y_pred) + torch.sum(y_true)
dice = (2. * intersection + self.smooth) / (union + self.smooth)
return 1 - dice
# 使用示例
loss_fn = DiceLoss()
y_pred = torch.randn(2, 1, 256, 256) # 模型输出
y_true = torch.randint(0, 1, (2, 1, 256, 256)).float() # 真实标签
loss = loss_fn(y_pred, y_true)
print(f"Dice Loss: {loss.item():.4f}")七、优化Dice系数的技巧
-
联合损失函数:
- 组合Dice Loss和交叉熵损失(CE Loss),平衡重叠区域和像素级分类:
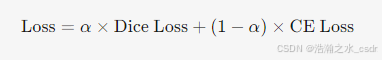
- 组合Dice Loss和交叉熵损失(CE Loss),平衡重叠区域和像素级分类:
-
数据增强:
- 对小目标过采样或使用“复制-粘贴”增强(Copy-Paste Augmentation)。
-
模型改进:
- 使用U-Net++、Attention U-Net等结构增强细节捕捉能力。
-
后处理优化:
- 应用形态学操作(如闭运算)平滑预测边界。
八、总结
- Dice系数的核心价值:在医学影像等小目标或类别不平衡任务中,量化分割区域的重叠精度。
- 使用建议:
- 优先选择Dice系数评估医学影像分割模型。
- 结合IoU和Dice系数全面分析模型性能。
- 训练时使用Dice Loss直接优化重叠区域。
- 局限性:对边界细节不敏感,需结合其他指标(如Hausdorff距离)评估边缘准确性。



















 1524
1524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











