







 超级会员免费看
超级会员免费看
专栏内提供试读,感兴趣小伙伴可以订阅一下哈!
适用于所有的CV二维任务:图像分割、超分辨率、目标检测、图像识别、低光增强、遥感检测等
每日分享最新的前沿技术,
助力快速发论文、模型涨点!
from torch import nn
import torch
from einops import rearrange
# 预定义一个带有层归一化的预处理模块
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.ln = nn.LayerNorm(dim) # 层归一化,标准化输入
self.fn = fn # 用于传入的函数(例如 Attention 或 FeedForward)
def forward(self, x, **kwargs):
return self.fn(self.ln(x), **kwargs) # 对归一化后的输入应用函数
摘要
本文提出了一种新型的视觉变换器架构——CrossFormer,通过跨尺度嵌入层(CEL)和长短距离注意力(LSDA)模块,解决了现有视觉变换器无法有效建立不同尺度特征之间交互的问题。此外,还提出了动态位置偏置(DPB)模块,使相对位置偏置能够适应不同大小的输入图像。CrossFormer在图像分类、目标检测、实例分割和语义分割等多个视觉任务上表现出色,尤其是在密集预测任务上,性能提升显著。
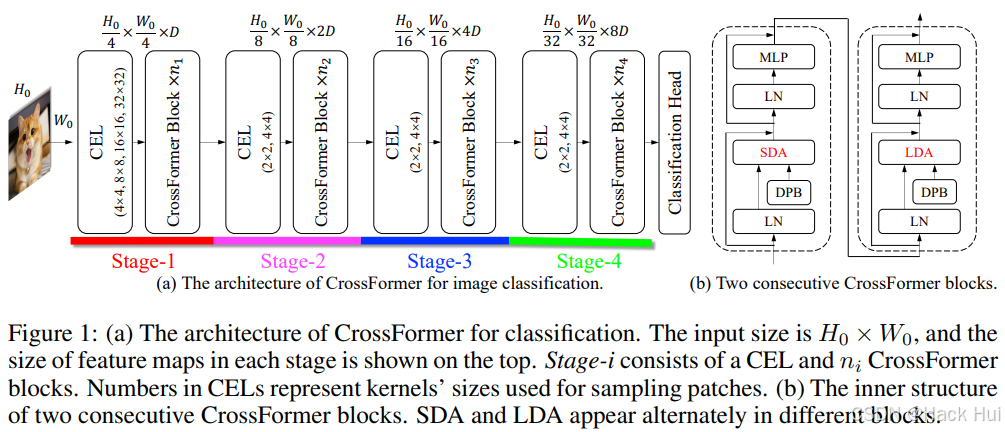
引言
近年来,变换器在自然语言处理(NLP)领域取得了巨大成功,其自注意力机制能够捕捉长距离依赖关系。受此启发,研究者们将其应用于计算机视觉任务,设计了多种视觉变换器架构。然而,现有视觉变换器存在一个关键问题:它们无法有效建立不同尺度特征之间的交互。例如,图像中可能存在不同尺度的物体,理解这些物体之间的关系对于视觉任务至关重要。但现有方法由于输入嵌入是等尺度的,且在自注意力模块中会丢失小尺度特征,因此无法实现跨尺度交互。为解决这一问题,本文提出了CrossFormer架构。
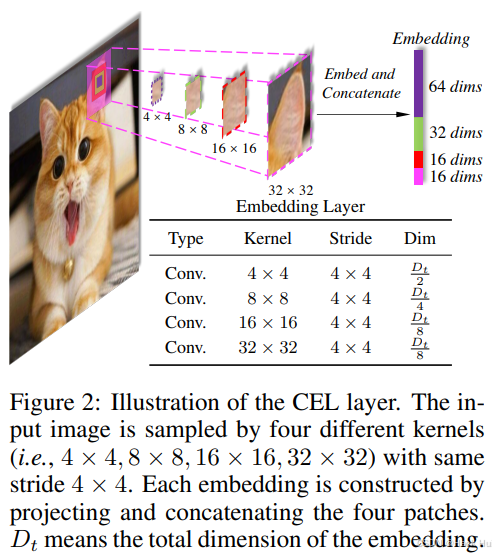
创新点
-
跨尺度嵌入层(CEL):通过使用不同尺度的卷积核采样图像,并将这些多尺度的特征拼接在一起,为每个嵌入提供了跨尺度特征。
-
长短距离注意力(LSDA):将自注意力模块分为短距离注意力(SDA)和长距离注意力(LDA),既保留了小尺度特征,又降低了计算成本。
-
动态位置偏置(DPB):提出了一种基于MLP的模块,能够根据输入嵌入的相对距离动态生成位置偏置,适用于不同大小的输入图像。
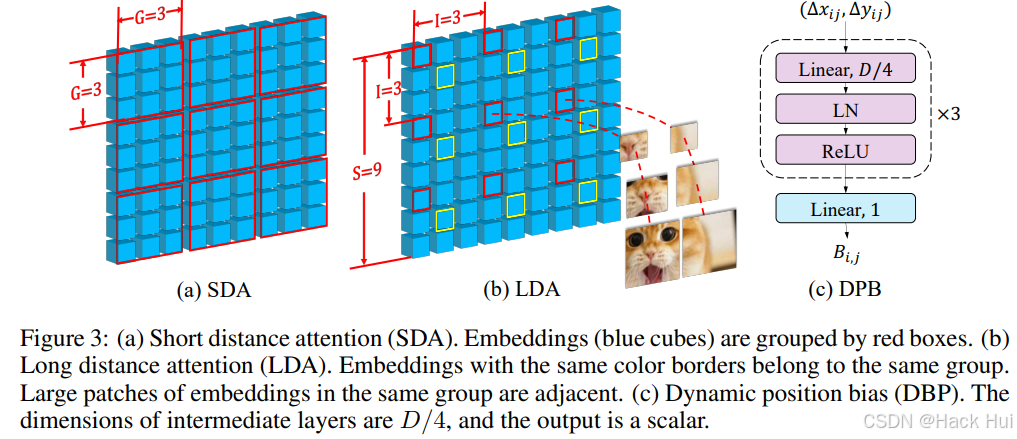
主要方法
跨尺度嵌入层(CEL)
CEL是CrossFormer的核心组件之一,用于生成每个阶段的输入嵌入。它通过多个不同尺度的卷积核(如4×4、8×8、16×16等)对输入图像或特征图进行采样,然后将这些多尺度的特征通过投影和拼接操作生成一个嵌入。这种设计使得每个嵌入都包含不同尺度的信息,从而支持跨尺度交互。
长短距离注意力(LSDA)
LSDA是CrossFormer的另一个关键模块,用于替代传统的自注意力模块。它将自注意力分为两部分:
-
短距离注意力(SDA):只关注相邻的嵌入,通过分组的方式计算局部依赖关系。
-
长距离注意力(LDA):关注远距离的嵌入,通过固定间隔采样来计算全局依赖关系。
这种设计不仅降低了计算成本,还保留了小尺度和大尺度特征。
动态位置偏置(DPB)
为了使相对位置偏置能够适应不同大小的输入图像,本文提出了DPB模块。它通过一个MLP网络根据嵌入之间的相对距离动态生成位置偏置,从而克服了传统相对位置偏置(RPB)只能处理固定大小输入的限制。
实验细节
数据集
-
图像分类:使用ImageNet数据集,包含128万训练图像和5万验证图像。
-
目标检测和实例分割:使用COCO 2017数据集,包含11.8万训练图像和5千验证图像。
-
语义分割:使用ADE20K数据集,包含2万训练图像和2千验证图像。
训练设置
-
使用AdamW优化器,学习率采用余弦衰减调度器,训练300个epoch。
-
数据增强方法包括RandAugment、Mixup、Cutmix等。
-
对于目标检测和实例分割任务,使用RetinaNet和Mask R-CNN作为检测头,训练1×或3×schedule。
-
对于语义分割任务,使用Semantic FPN和UPerNet作为分割头,训练80K或160K迭代。
模型变体
CrossFormer提供了四种不同大小的变体(Tiny、Small、Base、Large),分别适用于不同的任务需求。这些变体在不同阶段的嵌入维度、头数、分组大小等参数有所不同。
实验结果分析
图像分类
CrossFormer在ImageNet验证集上取得了优异的性能。例如,CrossFormer-S在参数量和计算量与现有方法相当的情况下,达到了82.5%的准确率,比其他方法如PVT、Swin等高出至少1.2%。
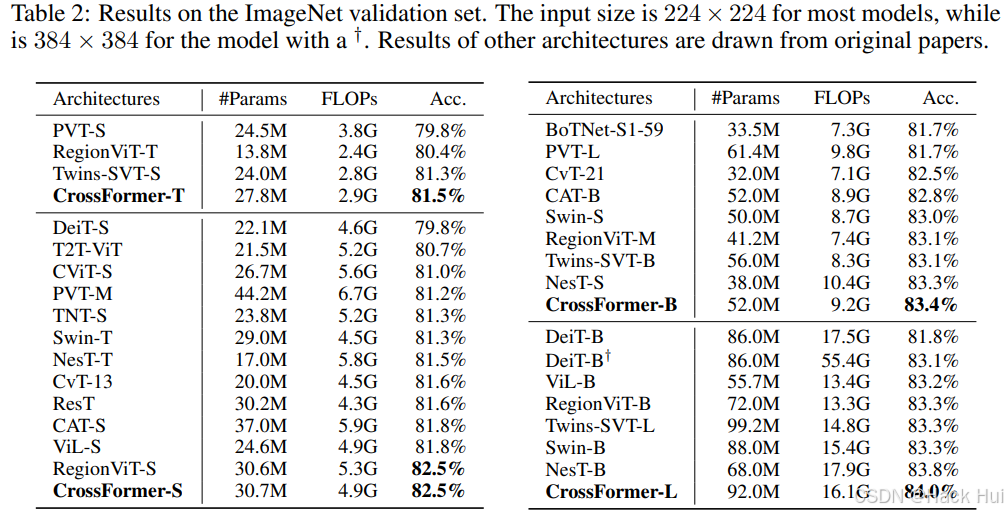
目标检测和实例分割
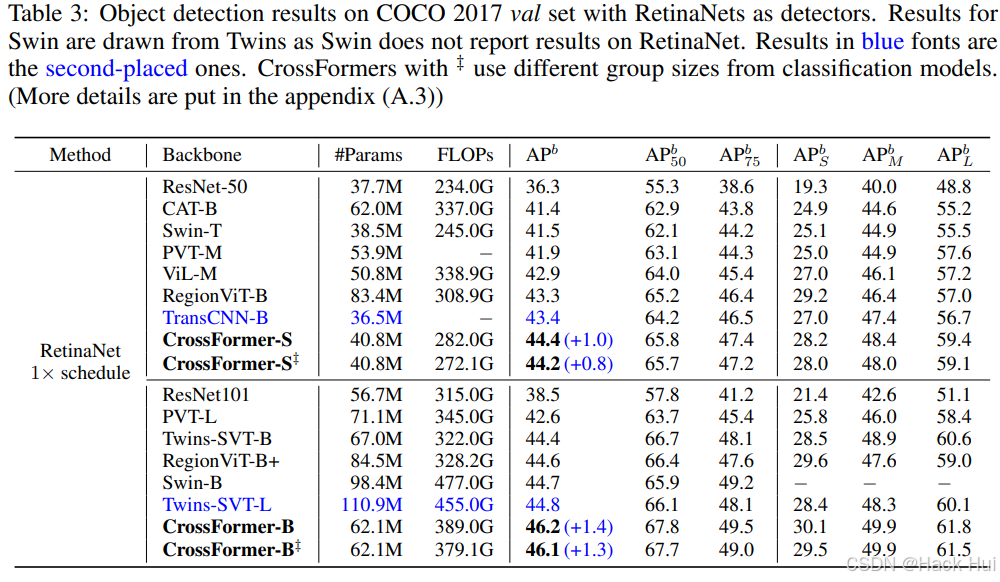
在COCO数据集上,CrossFormer在目标检测和实例分割任务上均优于其他方法。例如,使用RetinaNet作为检测头时,CrossFormer-S的AP达到了44.4,比其他方法如Swin-T、PVT-M等高出1%以上。此外,随着模型规模的增大,CrossFormer的性能提升更为显著。
语义分割
在ADE20K数据集上,CrossFormer在语义分割任务上也表现出色。例如,使用Semantic FPN作为分割头时,CrossFormer-S的mIOU达到了46.0,比其他方法如Twins-SVT-B高出0.8%。当使用UPerNet作为分割头时,CrossFormer-B的mIOU达到了49.7,比其他方法高出1.3%。
消融实验
-
跨尺度嵌入层(CEL):实验表明,使用跨尺度嵌入层的模型比单尺度嵌入层的模型性能更高,例如CrossFormer-S的准确率比单尺度嵌入的模型高出1%。
-
长短距离注意力(LSDA):与PVT和Swin的自注意力模块相比,LSDA能够更好地平衡计算成本和性能。
-
动态位置偏置(DPB):DPB与相对位置偏置(RPB)在性能上相当,但DPB能够适应不同大小的输入图像。
主要代码展示:
from torch import nn
import torch
from einops import rearrange
# 预定义一个带有层归一化的预处理模块
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.ln = nn.LayerNorm(dim) # 层归一化,标准化输入
self.fn = fn # 用于传入的函数(例如 Attention 或 FeedForward)
def forward(self, x, **kwargs):
return self.fn(self.ln(x), **kwargs) # 对归一化后的输入应用函数
# 定义一个前馈神经网络模块,用于 MLP 层
class FeedForward(nn.Module):
def __init__(self, dim, mlp_dim, dropout):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, mlp_dim), # 线性层,输入维度到 MLP 维度
nn.SiLU(), # SiLU 激活函数
nn.Dropout(dropout), # Dropout,防止过拟合
nn.Linear(mlp_dim, dim), # 线性层,将 MLP 维度还原为输入维度
nn.Dropout(dropout) # Dropout
)
def forward(self, x):
return self.net(x) # 输出前馈网络的结果
# 定义注意力模块,用于计算多头自注意力
class Attention(nn.Module):
def __init__(self, dim, heads, head_dim, dropout):
super().__init__()
inner_dim = heads * head_dim # 内部维度为头数乘以每头的维度
project_out = not (heads == 1 and head_dim == dim) # 判断是否需要输出投影
self.heads = heads # 注意力头的数量
self.scale = head_dim ** -0.5 # 缩放因子,用于稳定训练
self.attend = nn.Softmax(dim=-1) # 使用 Softmax 计算注意力权重
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias=False) # 线性变换生成查询、键、值
# 输出层,如果没有单独的投影层则直接使用 Identity
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim=-1) # 将查询、键和值分成三个部分
q, k, v = map(lambda t: rearrange(t, 'b p n (h d) -> b p h n d', h=self.heads), qkv) # 重排维度
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale # 计算注意力分数
return self.to_out(out) # 返回投影输出
# Transformer 模块,由多层注意力和前馈网络组成
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, head_dim, mlp_dim, dropout=0.):
super().__init__()
self.layers = nn.ModuleList([]) # 初始化层列表
for _ in range(depth): # 根据深度循环添加层
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads, head_dim, dropout)), # 预归一化注意力模块
PreNorm(dim, FeedForward(dim, mlp_dim, dropout)) # 预归一化前馈模块
]))
def forward(self, x):
out = x
for att, ffn in self.layers: # 遍历注意力和前馈网络层
out = out + att(out) # 残差连接,应用注意力
out = out + ffn(out) # 残差连接,应用前馈网络
return out
# MobileViT 的注意力模块,结合了局部和全局表示
class MobileViTAttention(nn.Module):
def __init__(self, in_channel=3, dim=512, kernel_size=3, patch_size=7):
super().__init__()
self.ph, self.pw = patch_size, patch_size # 设置 patch 的高度和宽度
self.conv1 = nn.Conv2d(in_channel, in_channel, kernel_size=kernel_size, padding=kernel_size // 2) # 局部卷积
self.conv2 = nn.Conv2d(in_channel, dim, kernel_size=1) # 用于通道变换的 1x1 卷积
self.trans = Transformer(dim=dim, depth=3, heads=8, head_dim=64, mlp_dim=1024) # Transformer 模块用于全局表示
self.conv3 = nn.Conv2d(dim, in_channel, kernel_size=1) # 将维度变换回原通道
self.conv4 = nn.Conv2d(2 * in_channel, in_channel, kernel_size=kernel_size, padding=kernel_size // 2) # 用于融合的卷积层
def forward(self, x):
y = x.clone() # 复制输入张量 y = x 以保留局部特征
## 局部表示
y = self.conv2(self.conv1(x)) # 使用卷积层获得局部特征
## 全局表示
_, _, h, w = y.shape # 获取 y 的高度和宽度
y = rearrange(y, 'bs dim (nh ph) (nw pw) -> bs (ph pw) (nh nw) dim', ph=self.ph, pw=self.pw) # 重排为 patch 格式
y = self.trans(y) # 应用 Transformer 进行全局特征提取
y = rearrange(y, 'bs (ph pw) (nh nw) dim -> bs dim (nh ph) (nw pw)', ph=self.ph, pw=self.pw, nh=h // self.ph,
nw=w // self.pw) # 恢复为原始形状
## 融合
y = self.conv3(y) # 维度变换回原通道
y = torch.cat([x, y], 1) # 拼接局部和全局特征
y = self.conv4(y) # 融合后的卷积操作
return y # 返回融合结果
if __name__ == '__main__':
m = MobileViTAttention(in_channel=512)
input = torch.randn(1, 512, 49, 49) # 生成输入张量,大小为 (1, 512, 49, 49)
output = m(input) # 应用 MobileViTAttention 模块
print(input.shape) # 打印输入张量的形状
print(output.shape) # 打印输出张量的形状结论
本文提出的CrossFormer通过跨尺度嵌入层(CEL)和长短距离注意力(LSDA)模块,有效地解决了现有视觉变换器无法建立跨尺度交互的问题。此外,动态位置偏置(DPB)模块使模型能够处理不同大小的输入图像。CrossFormer在图像分类、目标检测、实例分割和语义分割等多个视觉任务上均表现出色,尤其是在密集预测任务上,性能提升显著。这表明跨尺度交互对于视觉任务的重要性。


















 7458
7458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











