







论文介绍
题目:
LEFormer: A Hybrid CNN-Transformer Architecture for Accurate Lake Extraction from Remote Sensing Imagery
论文地址:
https://arxiv.org/pdf/2308.04397
创新点
这篇文章介绍了一种名为LEFormer的混合CNN-Transformer架构,用于从遥感图像中准确提取湖泊。文章的创新点主要包括:
-
混合架构:LEFormer结合了卷积神经网络(CNN)和Transformer架构,以捕获局部和全局特征,并使用交叉编码器融合模块来提高掩码预测的准确性。
-
CNN编码器:提出了一个具有多尺度空间通道注意力(MSCA)的CNN编码器,以提取精确和详细的局部空间信息。
-
轻量级Transformer编码器:开发了一个轻量级Transformer编码器,减少了模型的计算和参数需求,同时保持高性能。
-
交叉编码器融合(CEF)模块:提出了一个轻量级层,用于结合来自CNN层的局部特征和来自Transformer层的全局特征,以恢复局部空间信息并增强细节。
方法
整体结构
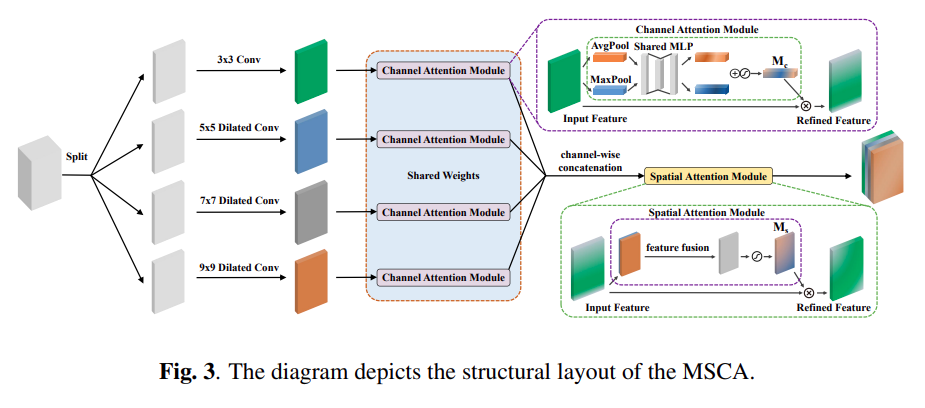
LEFormer是我们提出的一个新颖的混合CNN-Transformer架构,专门用于从遥感图像中准确提取湖泊。整体架构包含三个主要模块:CNN编码器(CE)、Transformer编码器(TE)以及轻量级的交叉编码器融合(CEF)模块。CNN编码器负责精确提取局部空间信息,它基于一个由多个堆叠的CE层组成的层次结构,每个CE层包括一个深度可分离(DW)层和一个多尺度空间通道注意力(MSCA),以改善多尺度特征提取。我们使用DW层作为下采样阶段,将输入图像的尺寸减小到H/4×W/4、H/8×W/8、H/16×W/16和H/32×W/32,其中H和W分别表示输入图像的高度和宽度。每个下采样阶段都包含一个带有卷积层的下采样块和GELU激活函数。此外,文章集成了一个MSCA,它结合了扩张卷积和CBAM的优势,以增强多尺度特征提取。

MSCA(多尺度空间通道注意力)的结构布局是一个关键组件,它结合了扩张卷积和CBAM(Convolutional Block Attention Module)的优势,以增强多尺度特征提取。MSCA的结构布局首先使用不同扩张率的扩张卷积来生成多尺度特征图,具体来说,使用了1、2、3和4的扩张率。这些扩张卷积能够改善不同尺度物体或特征的分割,通过调整核扩张率来实现。接下来,应用CBAM层来计算提取的多尺度特征图的注意力权重,并将这个注意力权重与输入的多尺度特征图相乘,以获得最终的特征。
实验结果
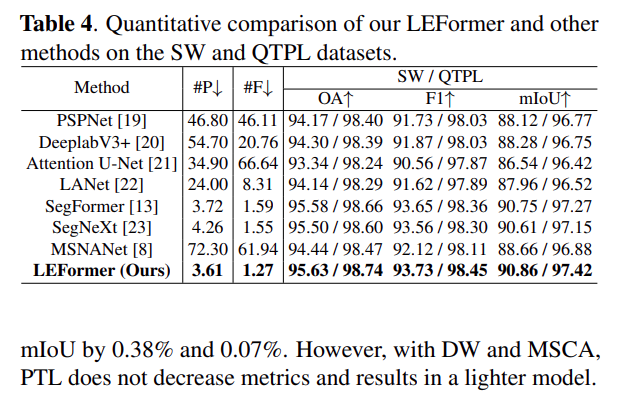
- 文章中的实验结果显示LEFormer在湖泊提取任务上取得了显著的性能。具体来说,在两个公开的卫星遥感数据集——Surface Water数据集(SW数据集)和青藏高原湖泊数据集(QTPL数据集)上,LEFormer均展现出了优异的性能和泛化能力。这两个数据集包含了来自可见光遥感图像的标注湖体,图像大小为256×256。
- 在SW数据集上,LEFormer实现了90.86%的mIoU(平均交并比),而在QTPL数据集上,LEFormer达到了97.42%的mIoU。这些结果表明,LEFormer在参数数量(3.61M)和计算量(1.27G flops)相对较低的情况下,相较于其他先进的湖泊提取模型,如MSNANet,LEFormer在参数量上少了20倍,计算量少了48倍,同时在mIoU上还提高了2.20%。此外,与其他模型相比,LEFormer在参数数量和浮点运算次数上都显著减少,而在整体准确率(OA)、F1分数和mIoU等评估指标上均实现了最佳或接近最佳的表现。
即插即用模块代码
https://github.com/BastianChen/LEFormer/blob/master/tools/train.py


















 375
375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









