








亮点直击
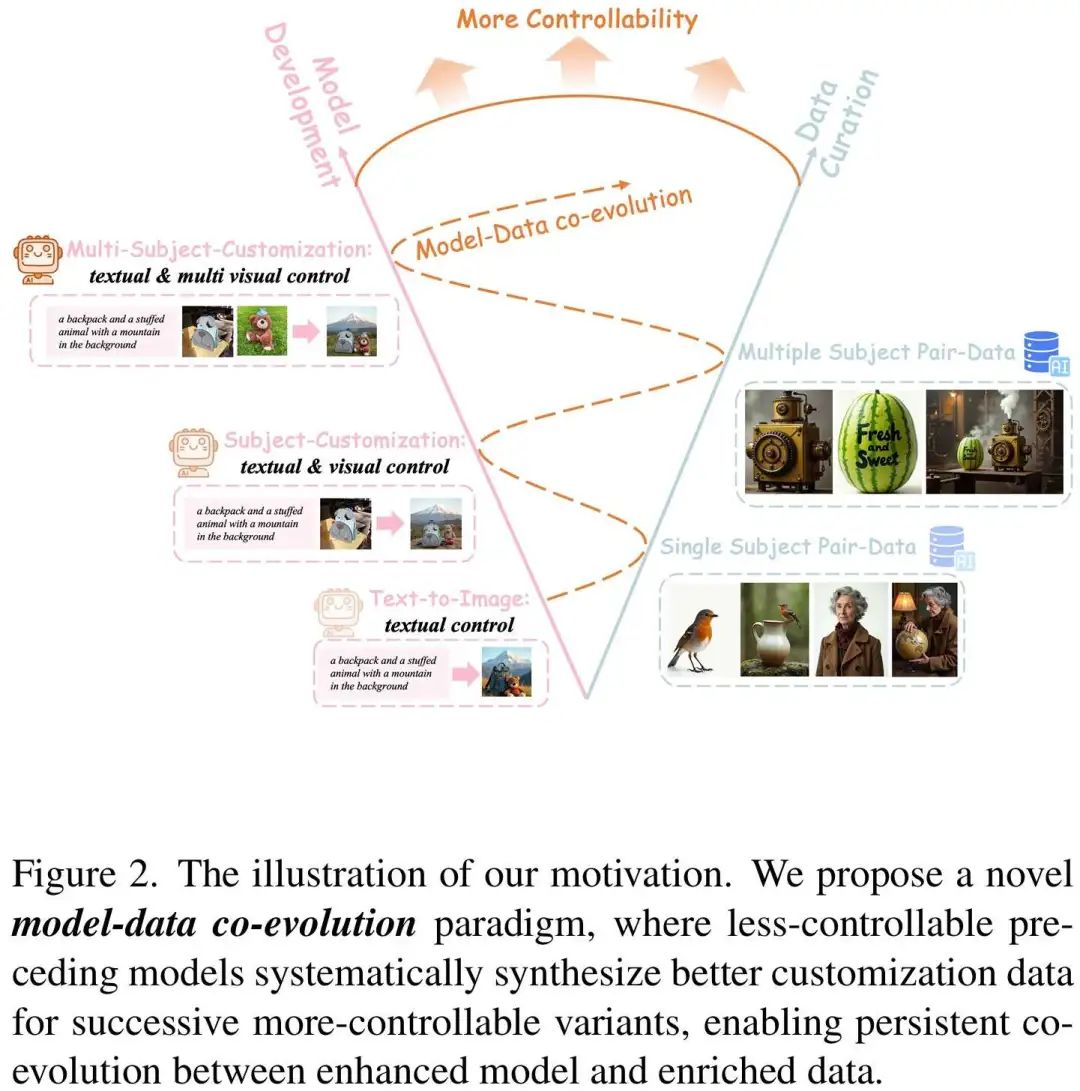
- 提出了模型-数据协同进化范式,突破了传统定制化图像生成中数据瓶颈的限制。
- 开发了渐进式数据生成框架和通用定制化模型UNO,实现了从单主体到多主体的高质量图像生成。
- 在多个任务中取得了卓越的性能,包括单主体和多主体驱动的图像生成,并且能泛化到id、tryon、style等场景
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

**温馨提示:篇幅有限,已打包文件夹,获取方式在

总结速览
解决的问题
- 数据瓶颈:高质量、多视角主体一致的配对数据难以获取,限制了模型的可扩展性。
- 主体扩展性:现有方法主要针对单主体生成,难以处理复杂且种类丰富的多主体场景。
提出的方案
- 提出了模型-数据协同进化范式,通过Text-to-Image(T2I) 模型生成更好的单主体定制化数据,进而训练更强大的Subject-to-Image(S2I)模型用于生成质量高、种类丰富的多主体数据。
- 开发了渐进式数据生成框架和通用定制化模型UNO,实现从单主体到多主体的高质量图像生成。
应用的技术
- 基于当前最先进的T2I模型FLUX,改进其成支持多条件生成的S2I模型。
- 渐进式跨模态对齐:通过逐步训练实现多图像条件的处理。
- 通用旋转位置嵌入(UnoPE):解决多图像条件下的属性混淆问题。
达到的效果
- 在DreamBench和多主体生成基准测试中,UNO在一致性和文本可控性方面均取得了最佳性能。
- 显著减少了“复制-粘贴”现象,提高了生成图像的质量和可控性。
- 极佳的泛化能力,能覆盖换装、人物保持、风格化等个性化生成
方法
上下文数据生成框架
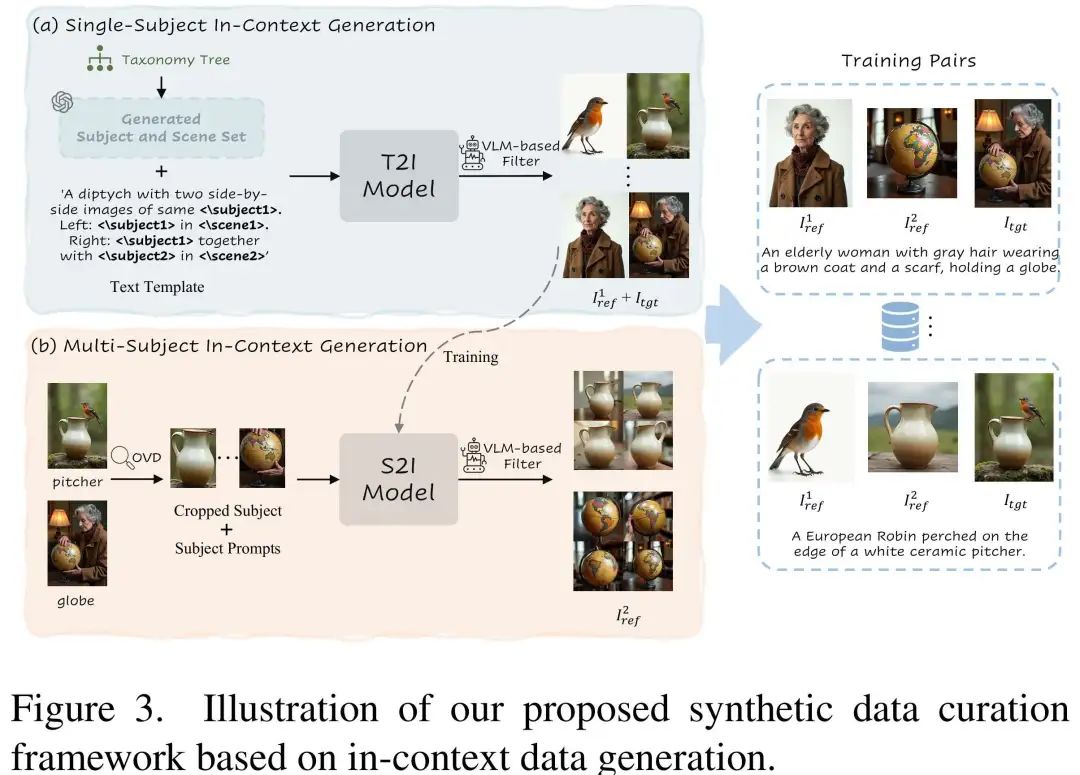
- 单主体配对数据生成:通过预定义的文本模板和LLM构建分类树,生成多样化主题和场景描述,利用DiT上下文生成能力直接生成主题一致的图像对,构建VLM打分器进行过滤
- 多主体配对数据生成:基于单主体数据训练的Subject-to-Image(S2I)模型,用开集检测得到另一新主体反向生成定制化数据,从而构建多主体一致的图像对,避免“复制-粘贴”问题。
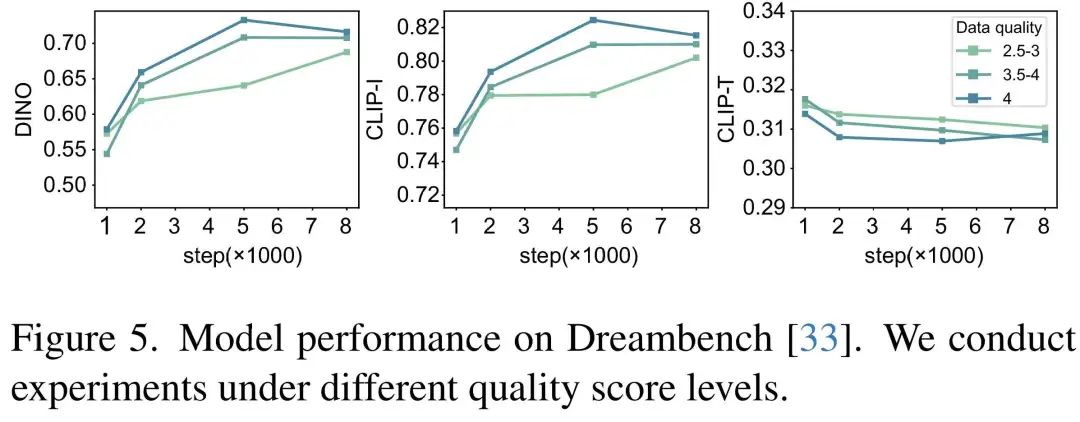
同时,作者在论文中也做了充足实验说明了层级数据过滤的重要性和有效性。
渐进式训练策略
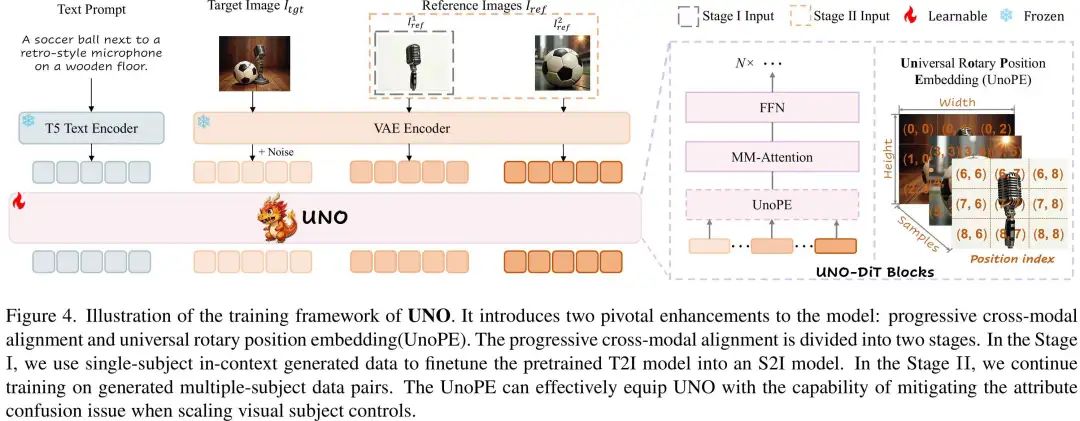
DiT模型最初是为纯T2I设计的,其输入是文本提示和噪声图像的嵌入。然而,当尝试引入多图像条件(如参考图像)时,直接输入多图像可能导致模型训练不稳定或性能下降。这是因为多图像条件的引入会改变模型的收敛分布,导致模型难以适应复杂的输入。为了克服这一问题,论文提出了渐进式跨模态对齐的训练方法,分为两个阶段:
-
单主题训练阶段(Stage I)
-
- 目标:让模型学会处理单图像条件的输入,生成与参考图像一致的结果。
- 方法:使用单主体数据对对预训练的T2I模型进行微调。输入包括文本提示、噪声图像嵌入和单一参考图像嵌入。
- 效果:通过这一阶段,模型能够理解如何将参考图像的信息融入生成过程中,生成与参考图像一致的单主体图像。
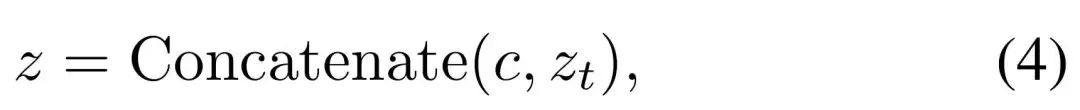
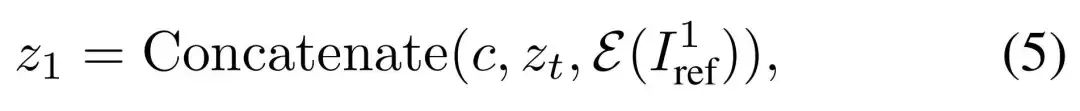
-
多主题训练阶段(Stage II)
-
- 目标:让模型学会处理多图像条件的输入,生成与多个参考图像一致的结果。
- 方法:在单主题训练的基础上,进一步使用多主体数据对进行训练。输入包括文本提示、噪声图像嵌入和多个参考图像嵌入。
- 效果:通过这一阶段,模型能够处理多个参考图像的输入,并生成与所有参考图像一致的多主题图像。
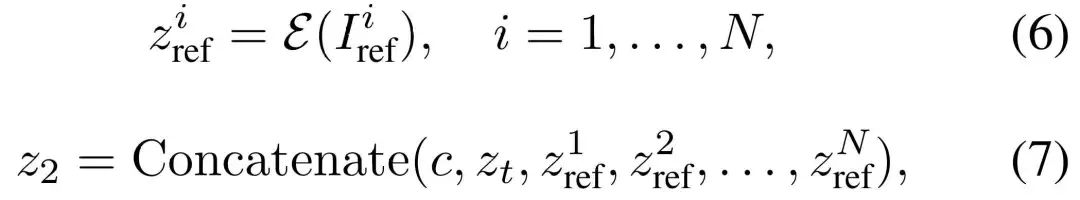
论文通过从简单到复杂的训练范式,让模型能够逐步适应多图像条件的输入,避免直接引入多图像条件导致的训练不稳定。
通用旋转位置嵌入(UnoPE)
在多图像条件下,DiT需要处理多个参考图像的嵌入。然而,直接使用原始的位置索引可能导致以下问题:一是空间结构依赖:模型可能过度依赖参考图像的空间结构(如位置和布局),而忽略文本提示中提供的语义信息;一是属性混淆:不同参考图像之间可能存在语义差距,导致模型难以准确生成目标图像。
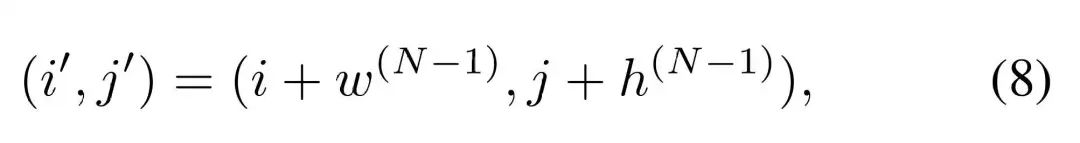
论文提出了通用旋转位置嵌入(UnoPE),通过调整位置索引的方式,使模型能够更好地关注文本特征,而不是简单地复制参考图像的空间结构。
实验结果
实验设置
- 数据生成:通过渐进式数据生成框架生成了230k单主体数据对和15k多主体数据对。
- 训练细节:基于FLUX.1预训练模型,使用LoRA秩为512进行训练,总批次为16,学习率为1e-5。
- 评估指标:使用DINO和CLIP-I分数评估主体一致性,CLIP-T分数评估文本遵循度。
结果
- 定性指标:UNO在Dreambench单主体和多主体生成中均能保持主体细节和文本指令的一致性,显著优于其他方法,几乎做到了对参考图细节的完美保留。


- 定量指标:在DreamBench数据集上,UNO在单主题生成中取得了最高的DINO(0.760)和CLIP-I(0.835)分数;在多主题生成中,DINO和CLIP-I分数分别为0.542和0.733,成为目前一致性生成的SOTA。
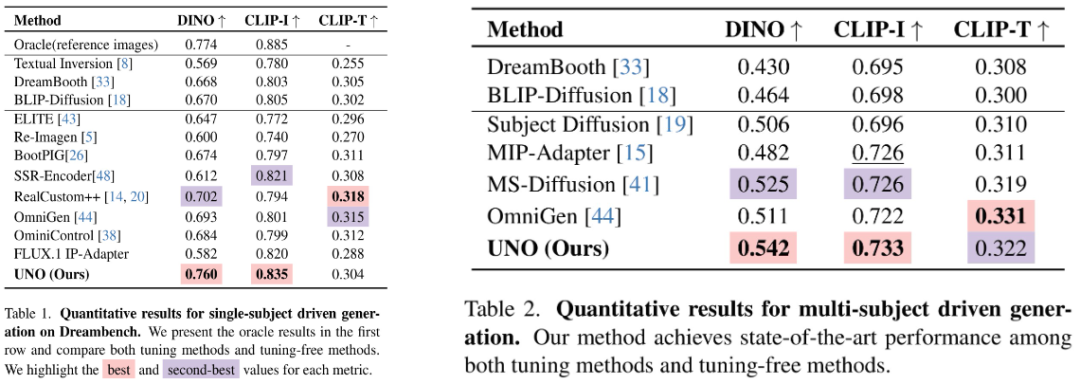
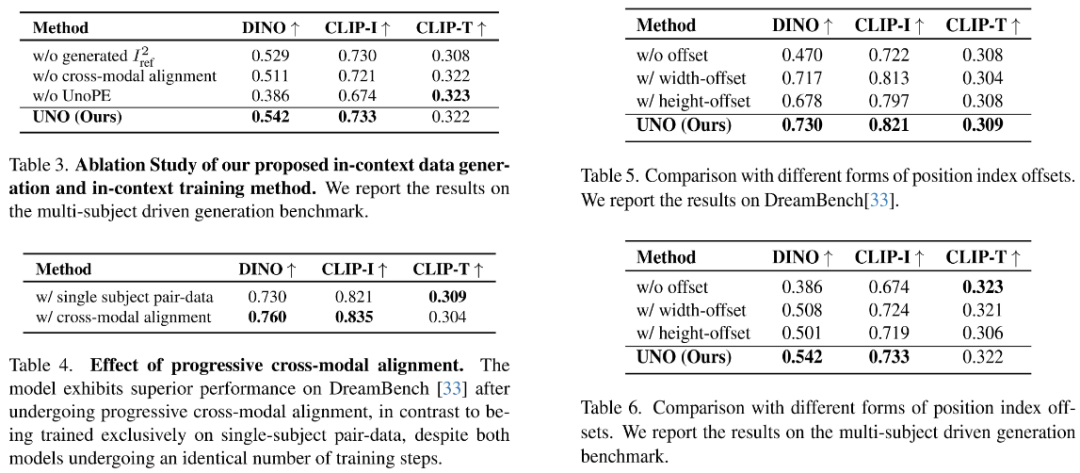
- 消融实验:论文充分验证了渐进式跨模态对齐和UnoPE与其它变体相比的有效性。移除这些模块后,性能显著下降,证明了它们对模型性能的关键作用。
应用案例
UNO还展示了很强的泛化能力,除了应对更为复杂的多图主体保持场景外,还能涵盖以往身份保持、换装、风格化等任务,从而为未来工作提供启发。

结论
论文提出的UNO模型通过模型-数据协同进化范式,突破了数据瓶颈,实现了高质量的单主体和多主体定制化图像生成。实验结果表明,UNO在主题相似性和文本可控性方面均达到了最佳性能,具有广泛的应用潜力,例如虚拟试穿、身份保持和风格化生成等。未来工作将进一步扩展合成数据类型,以解锁UNO的更多潜力。
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。

参考文献
[1] Less-to-More Generalization: Unlocking More Controllability by In-Context Generation
致谢
如果您觉得这篇文章对你有帮助或启发,请不吝点赞、转发,让更多人受益。同时,欢迎给个星标⭐,以便第一时间收到我的最新推送。每一个互动都是对我最大的鼓励。让我们携手并进,共同探索未知,见证一个充满希望和伟大的未来!

















 696
696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









